
一、问题
最近分享的数据集都是体量巨大,
- 93G数据集| 中国裁判文书网(2010-2021)
- 数据集 | 2.49亿条中国大陆工商企业注册信息(更新至23.9)
- 数据集| 3.9G全国POI地点兴趣点数据集
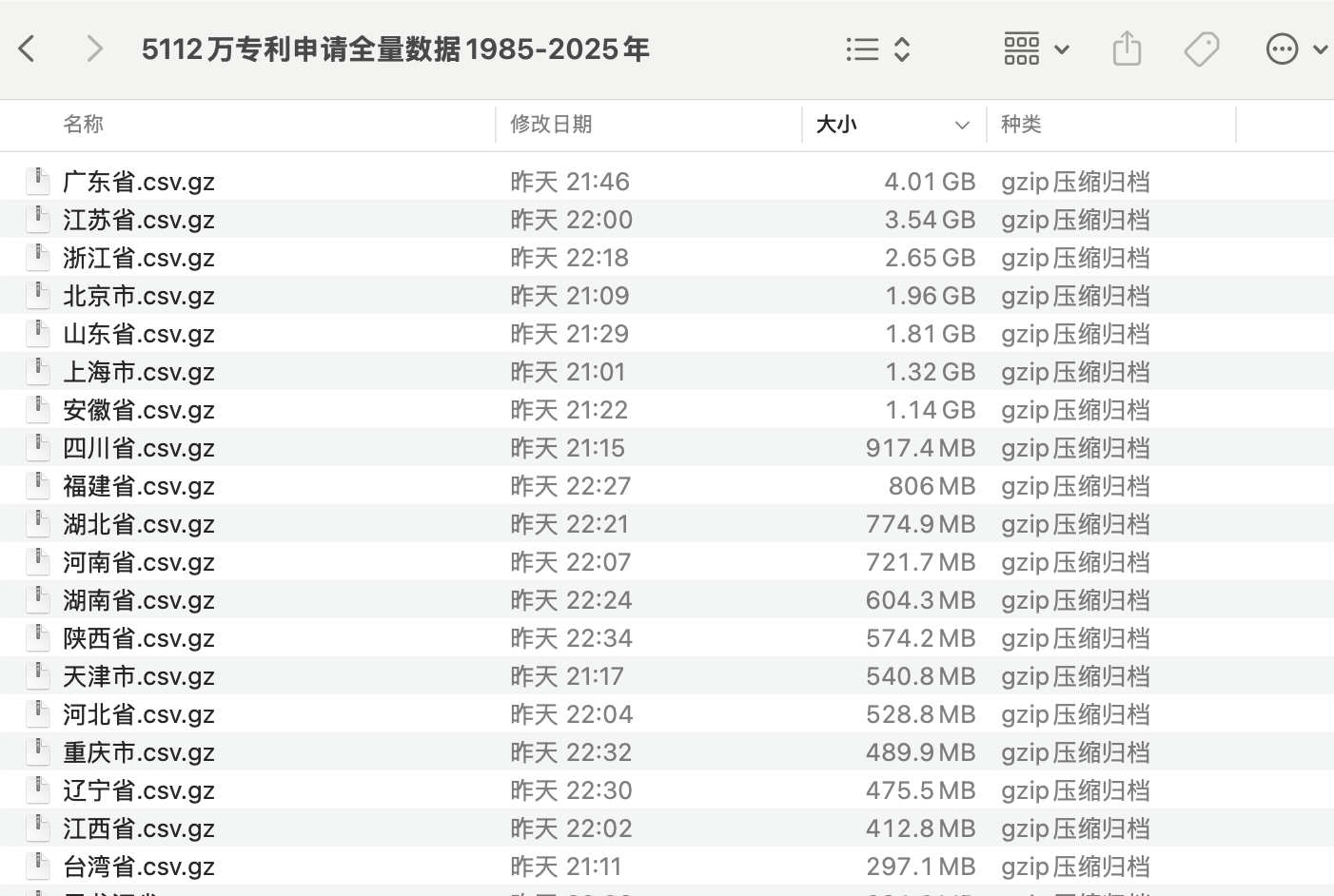
- 数据集| 5112万条专利申请数据集(1985-2025年)
- 数据集 | 1500w+消费者投诉数据集(2018 ~ 2024.8)
下图是 数据集 | 5112万条专利申请数据集(1985-2025年)截图,其中 广东省.csv.gz 4.01 G,解压后得到的 广东省.csv 达到 15.78G, 已经超过很多学员电脑内存(现在常见的笔记本内存是8G、16G、32G),我们应该如何应对这类 巨大csv文件 呢?
二、思路
一般应对 广东省.csv.gz 这类巨大csv文件,可以从以下两大类思路:
思路1. 使用更高配置的电脑
思路2. 花点功夫学大文件处理技巧
2.1 使用更高配置的电脑(服务器)
思路1, 方法简单,思路简单, 写代码的方式一如既往, 认知成本低, 美中不足要花钱。
- 买电脑; 如果你不差钱,直接换更好的电脑, 8G–>16G–>32G–>64–>96G–>128G… 预算决定数据处理能力的上限。
- 租用服务器;如果差钱,资金不足脑力凑。 租用服务器的难点是像你我刚接触电脑一样,要熟悉服务器操作,前期存在较大的认知难度和学习难度。
2.2 花点功夫学大文件处理技巧
网上关于处理大文件的技巧虽然很多,比如针对每个字段的数据类型,整形、浮点型、64位、32位, 反正大邓是不太懂。 咱们学python的原则是,用最少的时间学到最常用最有用的,解决80%的问题,剩下的20%太难的问题还是交给专业人士。假设你我电脑内存是8G,要在此环境下进行数据处理, 以下是常见的处理方法
-
读取前n条记录
-
读取某个(些)字段
-
小批次读取
-
转csv为xlsx
在接下来的章节中,我们重点分享以上5类技巧代码。
三、好技巧
以csv、xlsx这类数据, 每行代表一条记录,每列代表一个字段,而文件体积是由行数和列数决定。而 pd.read_csv有三个最常用的参数nrows、usecols、chunksize,分别决定读前nrows行、选择usecols列读取、按照chunksize分批次读取。
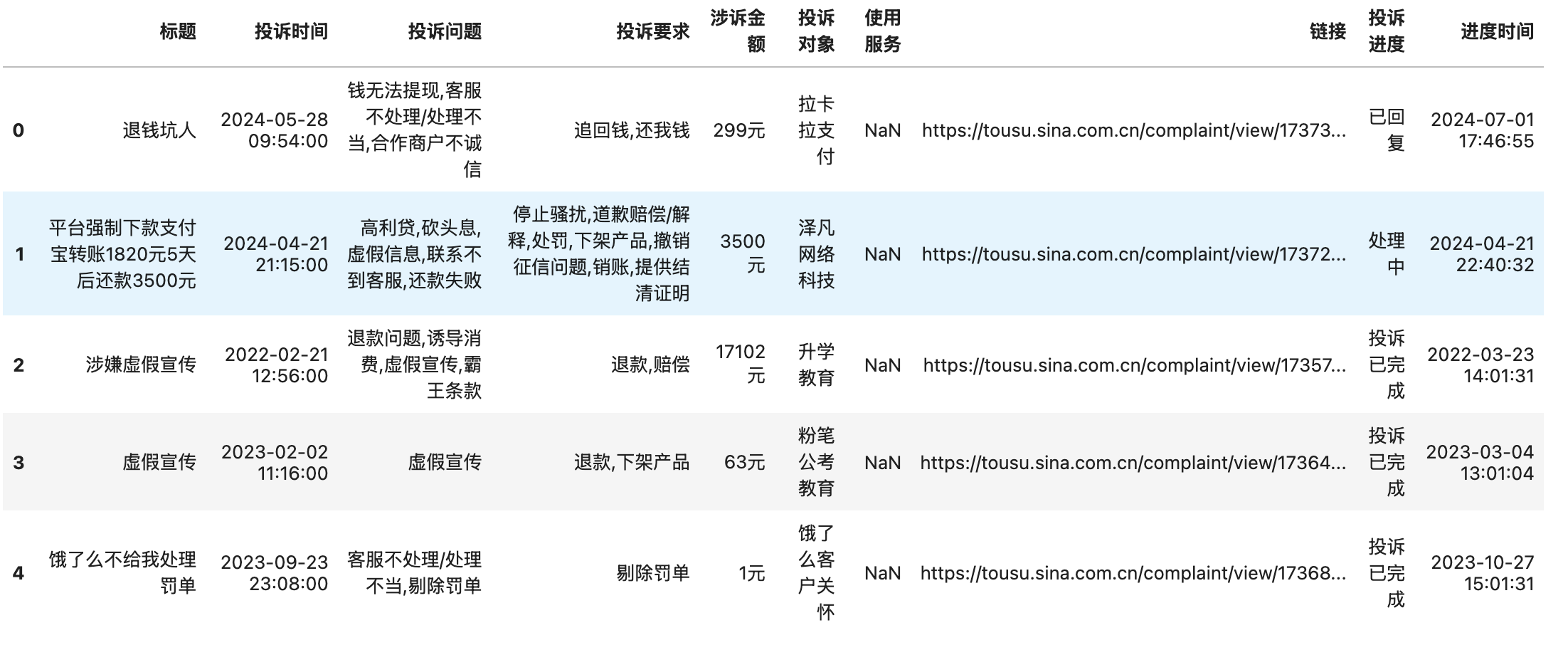
我选择以 数据集 | 1500w+消费者投诉数据集(2018 ~ 2024.8) 中的文件 消费者黑猫投诉数据.csv.gz(解压后3.63G) 为例进行实验。 该文件格式较为干净, 不会出现太多意外情况,能更好的展示实验效果。
对这个csv文件,除了知道文件名,其他信息一无所知。这时候最简单的技巧就是尝试着读取前n条记录,先了解字段有哪些。
3.1 nrows
使用 nrows 参数设置只读取前n条记录, 了解csv字段有哪些
import pandas as pd
#只读取csv中前5条记录
df = pd.read_csv('消费者黑猫投诉数据.csv.gz', nrows=5, compression='gzip')
#使用bandizp、winrar等常用的解压软件解压gz文件,得到csv文件
#df = pd.read_csv('消费者黑猫投诉数据.csv', nrows=5)
df.head()
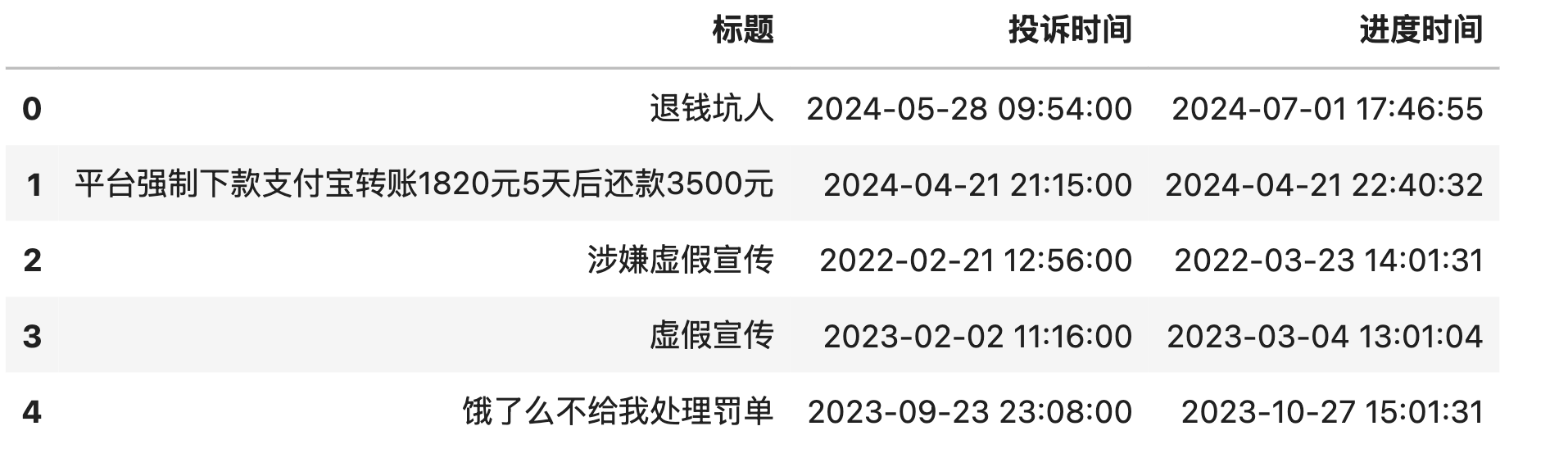
3.2 usecols
使用usecols参数,设置只读取某个(些)字段
import pandas as pd
df = pd.read_csv('消费者黑猫投诉数据.csv.gz', compression='gzip', nrows=5, usecols=['标题', '投诉时间','进度时间'])
df
3.3 bytes_to_GB(df)
设计一个查看文件内存的函数, 单位GB
def bytes_to_GB(df):
bytes_value = df.memory_usage(deep=True).sum()
return round(bytes_value / (1024 ** 3), 2)
%%time
import pandas as pd
df = pd.read_csv('消费者黑猫投诉数据.csv.gz', compression='gzip')
print(f"内存占用: {bytes_to_GB(df)} GB")
Run
CPU times: user 35.7 s, sys: 1.62 s, total: 37.3 s
Wall time: 37.3 s
内存占用: 10.95 GB
3.4 engine
可指定 engine=‘pyarrow’, 来提高读取速度。
%%time
import pandas as pd
df = pd.read_csv('消费者黑猫投诉数据.csv.gz', compression='gzip', engine='pyarrow')
print(f"内存占用: {bytes_to_GB(df)} GB")
Run
CPU times: user 19.1 s, sys: 2.81 s, total: 21.9 s
Wall time: 14.1 s
内存占用: 9.14 GB
注: 使用engine=‘pyarrow’, 容易代码报错, 这时候就只能放弃这个方法乖乖的默认读取。
3.5 dtype_backend
指定 dtype_backend=‘pyarrow’ 理论上会大大降低内存占用,但读取速度可能不一定提高。
%%time
import pandas as pd
df = pd.read_csv('消费者黑猫投诉数据.csv.gz',
compression='gzip',
dtype_backend='pyarrow')
print(f"内存占用: {bytes_to_GB(df)} GB")
Run
CPU times: user 54.1 s, sys: 5.59 s, total: 59.7 s
Wall time: 1min
内存占用: 9.14 GB
同时指定 engine 和 dtype_backend 两个参数, 会明显提高读取速度
%%time
import pandas as pd
df = pd.read_csv('消费者黑猫投诉数据.csv.gz',
compression='gzip',
engine='pyarrow',
dtype_backend='pyarrow')
print(f"内存占用: {bytes_to_GB(df)} GB")
Run
CPU times: user 10.9 s, sys: 2.4 s, total: 13.3 s
Wall time: 4.75 s
内存占用: 3.36 GB
对比
| 参数 | 解析速度 | 内存占用 |
|---|---|---|
| pd.read_csv(csvf) | 最慢 | 最大 |
| pd.read_csv(csvf. engine=‘pyarrow’) | 较快 | 中等 |
| pd.read_csv(csvf, engine=‘pyarrow’, dtype_backend=‘pyarrow’) | 最快 | 最小 |
3.6 chunksize
当探索完前n行,选中某些列,我们已经了解了哪些字段是我们必须要用的, 占用系统内存的大小。
接下来,我们就可以尝试着按照批次读取数据。
为了让实验简单高效,我们假设只读取前50000行, 每批次是10000 行。 对比下占用系统内存的量
import pandas as pd
#一次性读取10000条记录
df = pd.read_csv('消费者黑猫投诉数据.csv.gz', compression='gzip', nrows=50000)
print(f"一次性读取内存占用: {bytes_to_GB(df)} GB")
#分批次读取
#每10000条记录是一个批次,得到chunk_dfs
chunk_dfs = pd.read_csv('消费者黑猫投诉数据.csv.gz', chunksize=10000, nrows=50000)
#每个chunk_df就是我们熟悉的dataframe类型数据
for chunk_df in chunk_dfs:
chunkdf_total_mb = bytes_to_mb(chunk_df.memory_usage(deep=True).sum())
print(f"分批次读取内存占用: {bytes_to_GB(df)} GB")
Run
一次性读取内存占用: 36.62 MB
分批次读取内存占用: 7.32 MB
分批次读取内存占用: 7.32 MB
分批次读取内存占用: 7.33 MB
分批次读取内存占用: 7.33 MB
分批次读取内存占用: 7.32 MB
在实践中,nrows 和 chunksize 不会同时出现, 而且 chunksize 一般都会设置的很大,例如1000000条。
chunk_dfs = pd.read_csv('csv文件', chunksize=1000000)
看到 chunk_dfs 也不要害怕,其实每个 chunk_df 就是我们熟悉的 df ,即dataframe数据类型。
四、总结
记住这行代码
pd.read_csv(csvf, nrows, usecols, engine, dtype_backend, chunksize)
8G内存的电脑, 通过以上技巧,基本可以把我们应对大数据的潜力放大N倍。 N可以是几倍、十几倍、几十倍、上百倍…,放大潜力的过程
- usecols 和 chunksize 起主要作用,百试百爽,稳定不出错。
- engine 和 dtype_backend 提高读取速度并降低内存占用,但代码容易出错。
- chunksize、nrows 参数不能与 engine、dtype_backend同时使用。
