
一、数据介绍
1.1 概况
数据集名:中国专利申请数据集
时间跨度:1985.1-2025.1
记录条数: 5112w
数据来源:『国家知识产权局』
数据体积: 解压后整个文件夹大概 90 G+
本文声明: 科研问题; 如有问题, 请加微信372335839,备注「姓名-学校-专业」
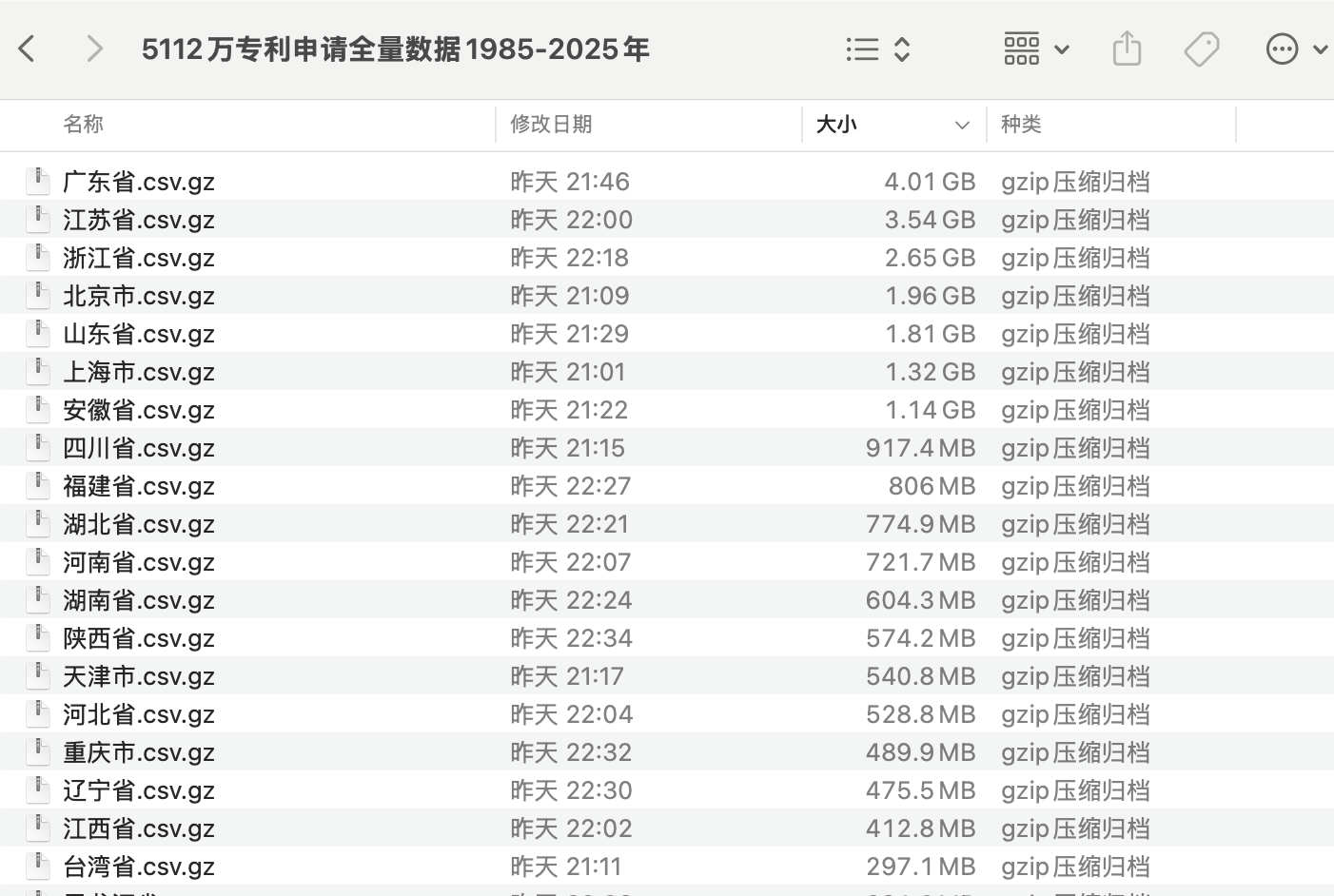
1.2 字段
- 专利名称
- 专利类型
- 申请人
- 申请人类型
- 申请人地址
- 申请人国家
- 申请人省份
- 申请人城市
- 申请人区县
- 申请号
- 申请日
- 申请年份
- 公开公告号
- 公开公告日
- 公开公告年份
- 授权公告号
- 授权公告日
- 授权公告年份
- IPC分类号
- IPC主分类号
- 发明人
- 摘要文本
- 主权项内容
- 当前权利人
- 当前专利权人地址
- 专利权人类型
- 统一社会信用代码
- 引证次数
- 被引证次数
- 自引次数
- 他引次数
- 被自引次数
- 被他引次数
- 家族引证次数
- 家族被引证次数
1.3 声明
科研用途;如有问题, 请加微信372335839,备注「姓名-学校-专业」
二、实验代码
2.1 读取全库文件
全库 中国专利数据库.csv.gz 体积 25.59G, 解压后 90G+。 大邓这里有一台内存 256 G 的服务器, 可以任性的试一试。
%%time
import pandas as pd
mega_df = pd.read_csv('中国专利数据库.csv.gz', compression='gzip', low_memory=False)
#mega_df = pd.read_feather('中国专利数据库.feather')
Run
CPU times: user 56min 29s,
Wall time: 1h 2min 47s
2.2 读取技巧
但平常我们使用的电脑,内存大概16G~32G, 所以只能借助 pandas的一些方法巧妙的读取这个大文件, 详情可参考 代码 | 如何用python处理超大csv文件 。为了后期绘制省份申请量和年度申请量这两个图,因此这里可以选择指定字段进行读取, 减少占用内存量。
%%time
df = pd.read_csv('中国专利数据库.csv.gz',
compression='gzip',
usecols=['申请人省份', '申请日'])
memory_size = int(df.memory_usage(deep=True)/1024/1024/1024)
print(f'两字段占用内存: {memory_size}G')
Run
CPU times: user 6min 29s, sys: 13 s, total: 6min 42s
Wall time: 6min 44s
两字段占用内存: 6G
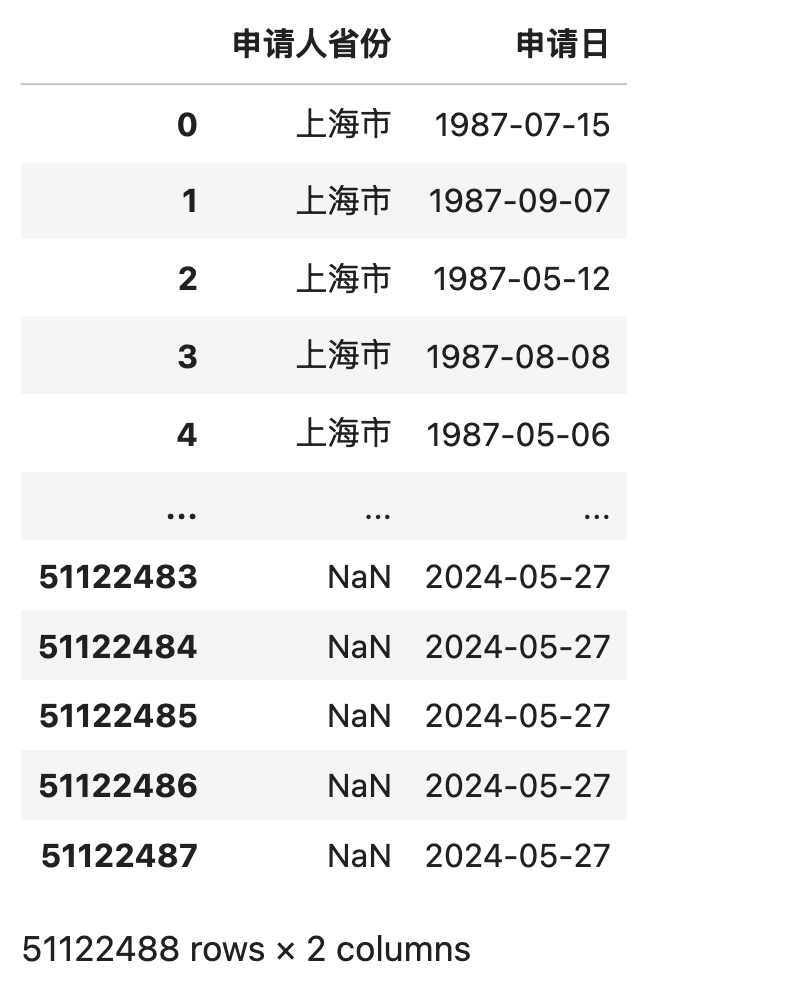
2.3 读取省份文件
数据集中的个别csv文件较大,例如 河北省.csv.gz体积528M , 解压得到的 河北省.csv 2G。 建议直接读取 .csv.gz,这样会提高数据读取的速度。 需要注意每次分析时不要开其他软件,如Word/PPT/Excel/WPS。
import pandas as pd
df = pd.read_csv('河北省.csv.gz', encoding='utf-8', compression='gzip', low_memory=False)
#df = pd.read_csv('河北省.csv', encoding='utf-8', low_memory=False)
df['申请日'] = pd.to_datetime(df['申请日'])
print('河北省申请量: ', len(df))
df.head()
Run
河北省申请量: 1048890

2.4 覆盖日期
print('覆盖日期: ', df['申请日'].min().date(), '~', df['申请日'].max().date())
Run
覆盖日期: 1985-04-01 ~ 2025-01-22
2.5 字段
df.columns
Run
Index(['专利名称', '专利类型', '申请人', '申请人类型', '申请人地址', '申请人国家', '申请人省份', '申请人城市',
'申请人区县', '申请号', '申请日', '申请年份', '公开公告号', '公开公告日', '公开公告年份', '授权公告号',
'授权公告日', '授权公告年份', 'IPC分类号', 'IPC主分类号', '发明人', '摘要文本', '主权项内容', '当前权利人',
'当前专利权人地址', '专利权人类型', '统一社会信用代码', '引证次数', '被引证次数', '自引次数', '他引次数',
'被自引次数', '被他引次数', '家族引证次数', '家族被引证次数'],
dtype='object')
df['专利类型'].value_counts()
Run
专利类型
实用新型 480822
发明申请 319386
外观设计 166560
发明授权 82122
Name: count, dtype: int64
三、字段详情
3.1 字段缺失程度
import missingno as ms
import matplotlib.pyplot as plt
import platform
# 根据操作系统设置字体
plt.rcParams['font.family'] = 'SimHei' if platform.system() == 'Windows' else 'Arial Unicode MS' if platform.system() == 'Darwin' else 'sans-serif'
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 绘制缺失值矩阵图
ms.matrix(dff)
# 显示图表
plt.show()
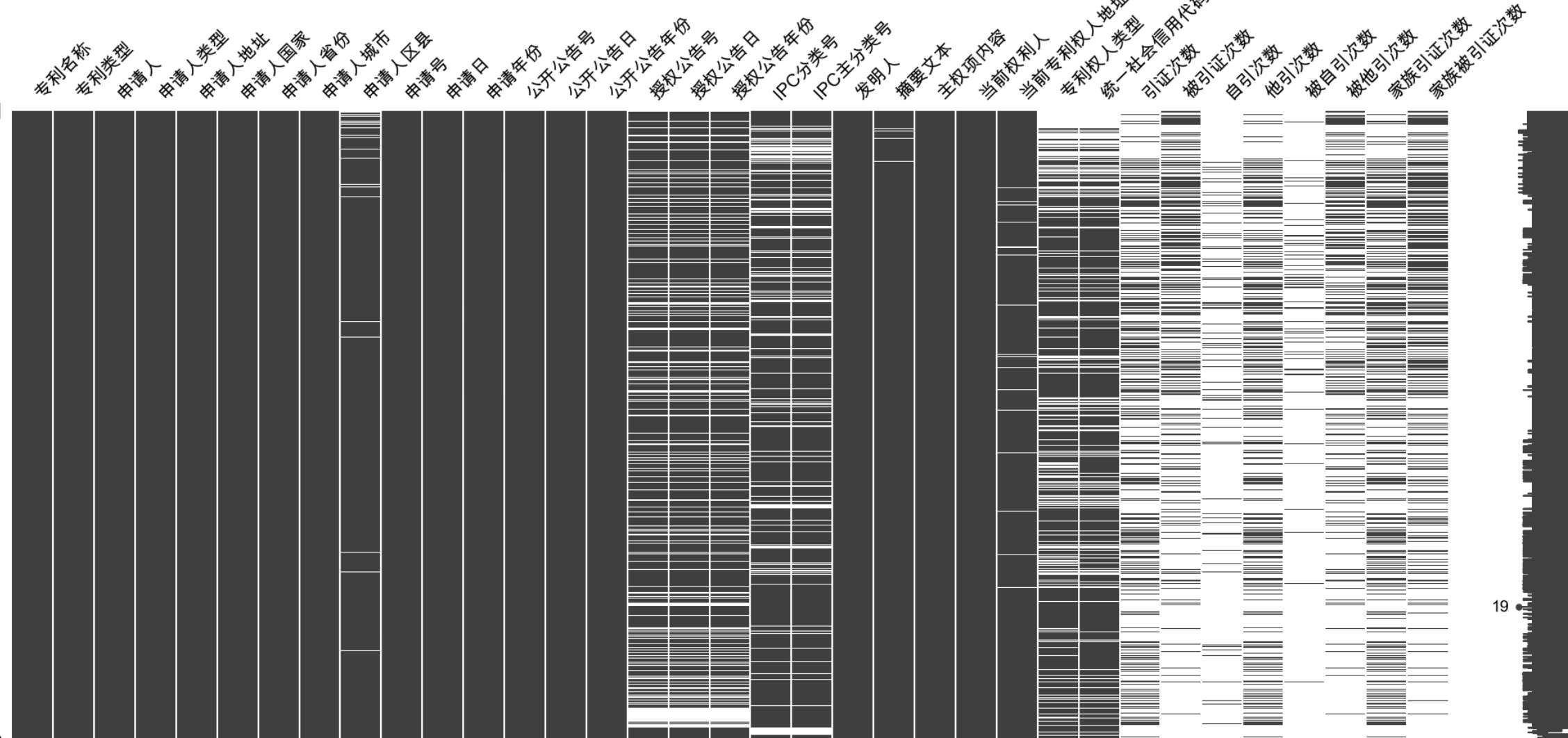
可以看到图右侧的柱状条存在明显的条纹, 柱状条的空白越多,说明对应字段的缺失程度越大。
3.2 专利类型
df['专利类型'].unique()
Run
array(['发明申请', '实用新型', '发明授权', '外观设计'], dtype=object)
3.2 发明人
发明人一般是自然人,但是极少数情况也可以是法人。发明人可以是多个自然人,一般以 ; 间隔
df['发明人']
Run
0 柴秀芬
1 秋海滨
2 葛长虹
3 孙盛典; 申富德
4 马建维; 邢建军
...
1048885 何治东; 刘应梁; 王琴
1048886 邢维鹏; 王春良
1048887 张正东; 张宏彬
1048888 张岩鑫; 韩静; 王宏建; 麻俐; 马东泽
1048889 储焰平; 薛志涛; 袁晓峰; 黄博
Name: 发明人, Length: 1048890, dtype: object
#整个河北省,只有这2条记录是发明人是公司法人
df[df['发明人'].fillna('').str.contains('公司')][['申请号', '专利名称', '申请人类型', '摘要文本', '发明人', '申请人']]

3.3 申请人
注意,申请人可以是自然人、法人、多个(自然人、法人), 一般以 ; 间隔。我们先直接看 申请人
df['申请人']
Run
0 柴秀芬
1 秋海滨
2 葛长虹
3 孙盛典; 申富德
4 马建维; 邢建军
...
1048885 昆明浩淼水利水电工程检测有限公司
1048886 海南紫程众投生物科技有限公司
1048887 泸西县宏达农业发展有限责任公司
1048888 辽宁省德明环境检测有限公司
1048889 中冶南方工程技术有限公司
Name: 申请人, Length: 1048890, dtype: object
#河北省,【申请人类型】大多数是企业
df[df['申请人'].fillna('').str.contains('公司')][['申请号', '专利名称', '申请人类型', '摘要文本', '发明人', '申请人']]

3.4 IPC分类号
dff[['专利名称', '主权项内容', 'IPC主分类号', 'IPC分类号']]
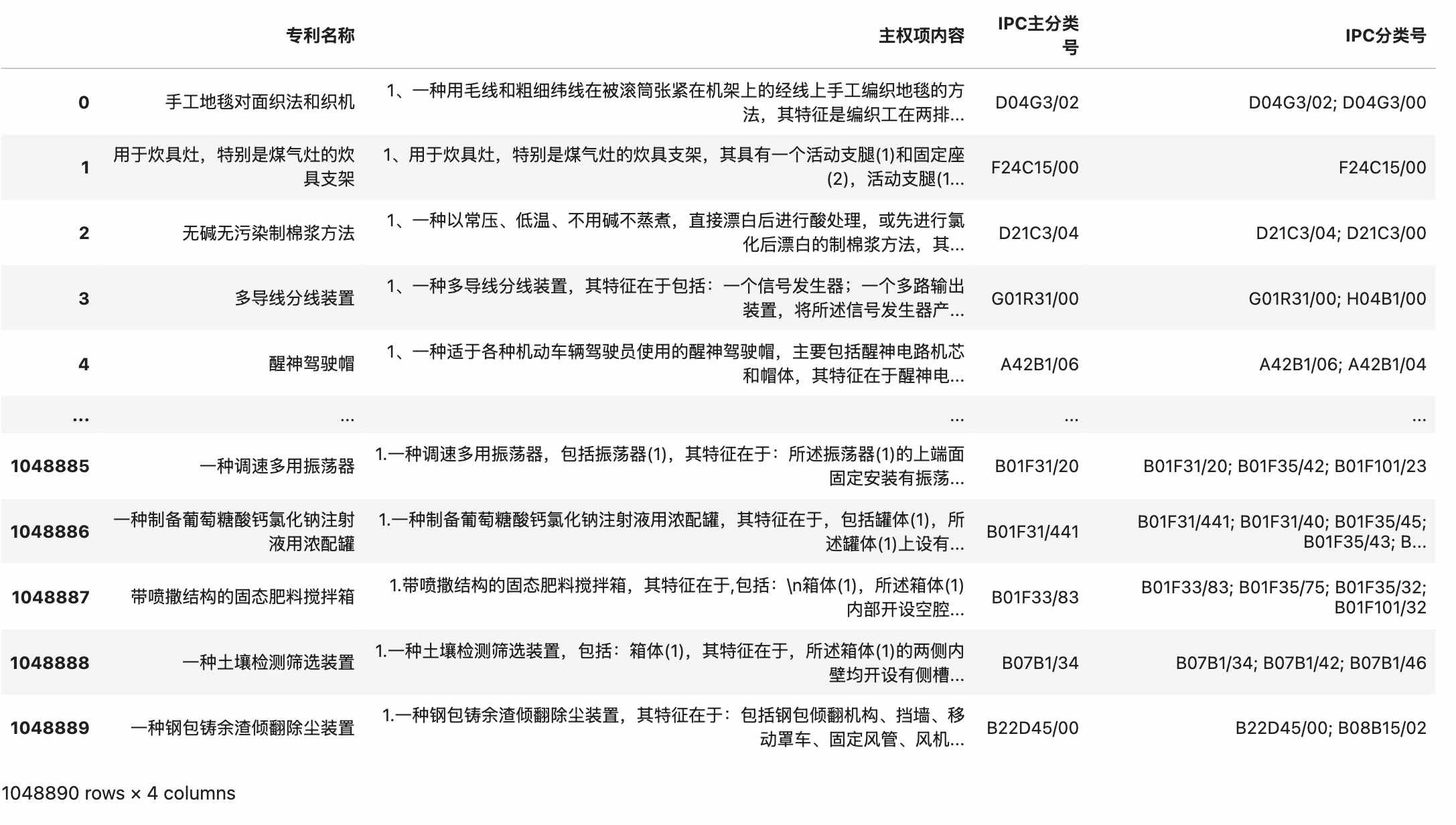
四、可视化
4.1 省份
%%time
import pandas as pd
from plotnine import *
from matplotlib.font_manager import FontProperties
font_prop = FontProperties(fname='文泉驿微米黑.ttf')
df = pd.read_csv('中国专利数据库.csv.gz', compression='gzip', usecols=['申请人省份'])
prov_volumes_df = df.groupby('申请人省份').size().reset_index(name='申请数量')
prov_volumes_df.sort_values('申请数量', ascending=False, inplace=True)
# 转换为分类变量并保持原始顺序
prov_volumes_df['申请人省份'] = pd.Categorical(
prov_volumes_df['申请人省份'],
categories=prov_volumes_df['申请人省份'].unique(),
ordered=True
)
(
ggplot(prov_volumes_df, aes(x='申请人省份', y='申请数量'))
+geom_bar(stat='identity')
+labs(title='省份专利申请量(1985-2025)',
x='',
y='')
+geom_text(aes(label='申请数量'),
va='bottom',
size=4.5,
format_string='{}')
+ annotate(
'text',
x= '新疆维吾尔自治区',
y= prov_volumes_df['申请数量'].max() * 1.05,
label='公众号: 大邓和他的Python',
ha='left',
va='top',
size=10,
color='black',
)
+theme(figure_size=(10, 6),
text=element_text(family= font_prop.get_name(), size=8, rotation=0),
plot_title = element_text(size=15, rotation=0),
axis_text_x = element_text(size=8, rotation=45)
)
)
Run
CPU times: user 8min 19s,
Wall time: 8min 44s
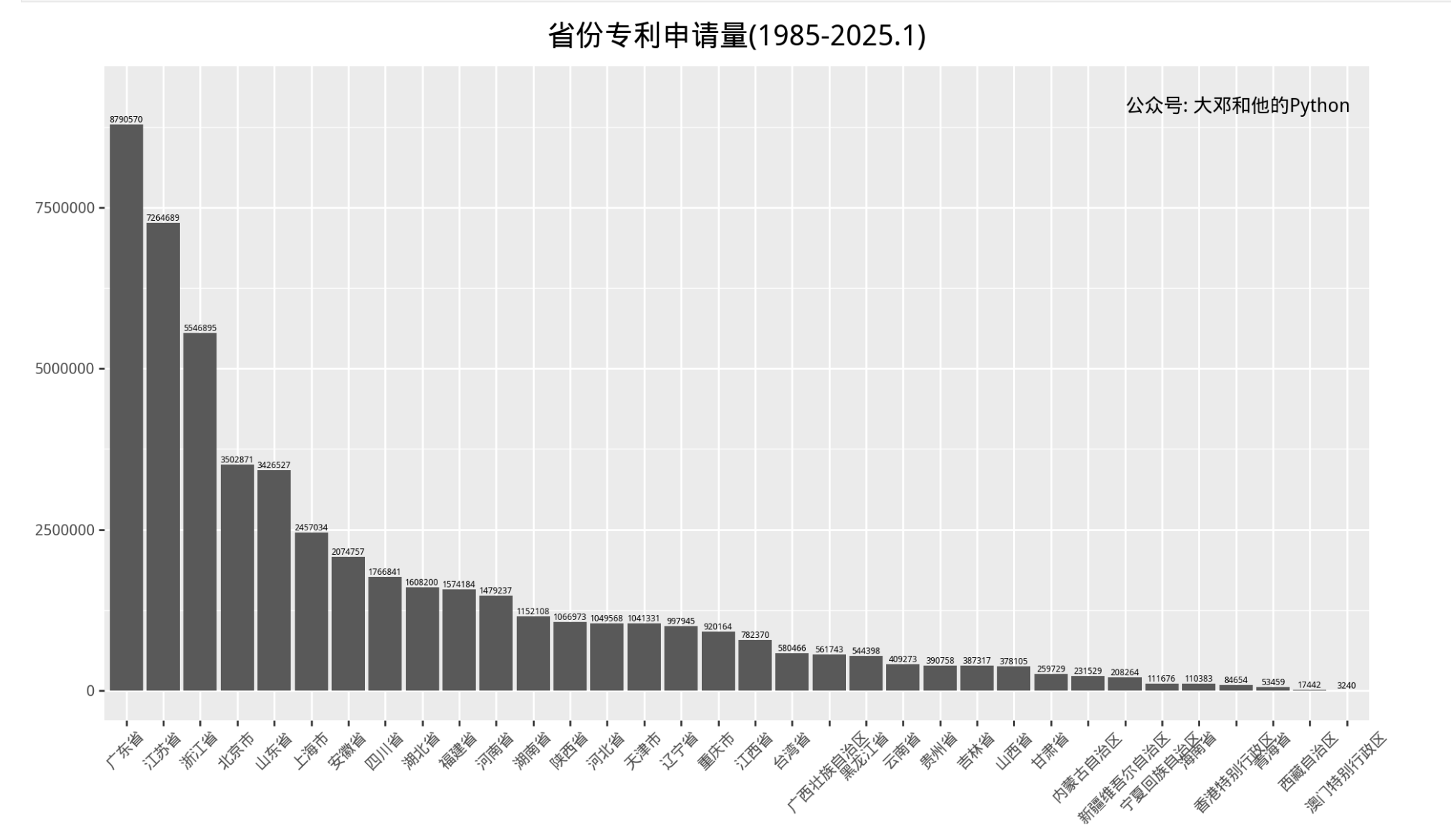
4.2 年份
%%time
import pandas as pd
from plotnine import *
from matplotlib.font_manager import FontProperties
import numpy as np
font_prop = FontProperties(fname='文泉驿微米黑.ttf')
df = pd.read_csv('中国专利数据库.csv.gz', compression='gzip', usecols=['申请日'])
date_df = (
df['申请日'].groupby(
pd.to_datetime(df['申请日']).dt.year.apply(lambda y: str(y).replace('.0', '')))
.size()
.reset_index(name='count')
.rename(columns={'申请日': 'year'})
)
date_df = date_df[date_df.year!='nan']
date_df.sort_values('year', ascending=True, inplace=True)
# 转换为分类变量并保持原始顺序
date_df['year'] = pd.Categorical(
date_df['year'],
categories=yc_df['year'].unique(),
ordered=True
)
(
ggplot(date_df, aes(x='year', y='count'))
+geom_bar(stat='identity')
+labs(title='专利年度申请量(1985-2025.1)',
x='',
y='')
+geom_text(aes(label='count'),
va='bottom',
size=4.1,
format_string='{}')
+ annotate(
'text',
x= date_df['year'].max(),
y= date_df['count'].max() * 1.05,
label='公众号: 大邓和他的Python',
ha='left',
va='top',
size=10,
color='black',
)
+theme(figure_size=(10, 6),
text=element_text(family= font_prop.get_name(), size=8, rotation=0),
plot_title = element_text(size=15, rotation=0),
axis_text_x = element_text(size=7, rotation=45, weight='bold', color='black')
)
# 显式指定坐标轴顺序(可选但保险)
+ scale_x_discrete(limits=[str(y) for y in range(1985, 2026)])
)
Run
CPU times: user 7min 44s,
Wall time: 8min 10s
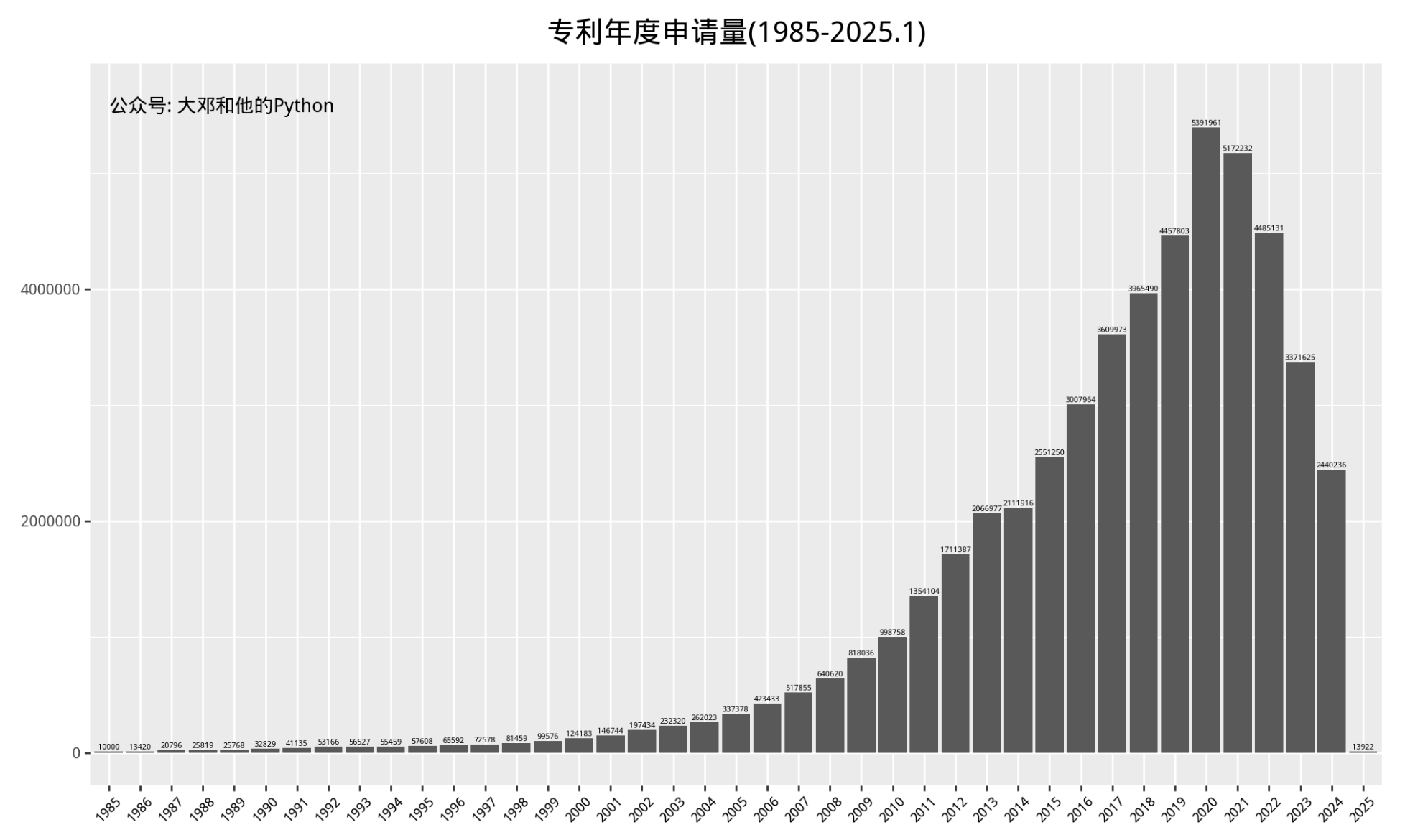
五、相关文献
使用专利数据做研究的文献
[1]Bellstam, Gustaf, Sanjai Bhagat, and J. Anthony Cookson. "A text-based analysis of corporate innovation." _Management Science_ 67, no. 7 (2021): 4004-4031.
[2]Arts, Sam, Bruno Cassiman, and Jianan Hou. "Position and Differentiation of Firms in Technology Space." Management Science (2023).
