一、中国裁判文书数据集
1.1 数据集概括
上亿条中国裁判文书, 公开案件主要覆盖 2010.1 ~ 2021.10 期间的记录, 数据集体量高达 93G 。
1.2 声明
科研用途; 如本文有任何问题, 可加微信372335839,备注「姓名-学校(公司)-专业(职务)」。
1.3 字段含
- 标题
- 审理法院
- 案件类型
- 网页链接
- 案号
- 审理程序
- 裁判日期
- 发布日期
- 文书内容
- 当事人
- 案由
- 法律依据
- 裁判年份
- 裁判月份
- 来源
1.4 可用价值
根据字段信息, 从该数据集中提取一些新的指标,可广泛适用于
- 法学
- 经济学
- 管理学
- 社会学
- 传播学
- 政治学
- 等
1.4 广告
数据体量越大,越乱(非结构的文本数据字段越多),门槛越高(处理难度越大), 该数据的潜在的相对价值越大。
使用这类数据需要读取大数据、文本清洗、文本分析,可以考虑学习 Python实证指标构建与文本分析,内容包括文本分析方方面面的技能点。
二、导入数据
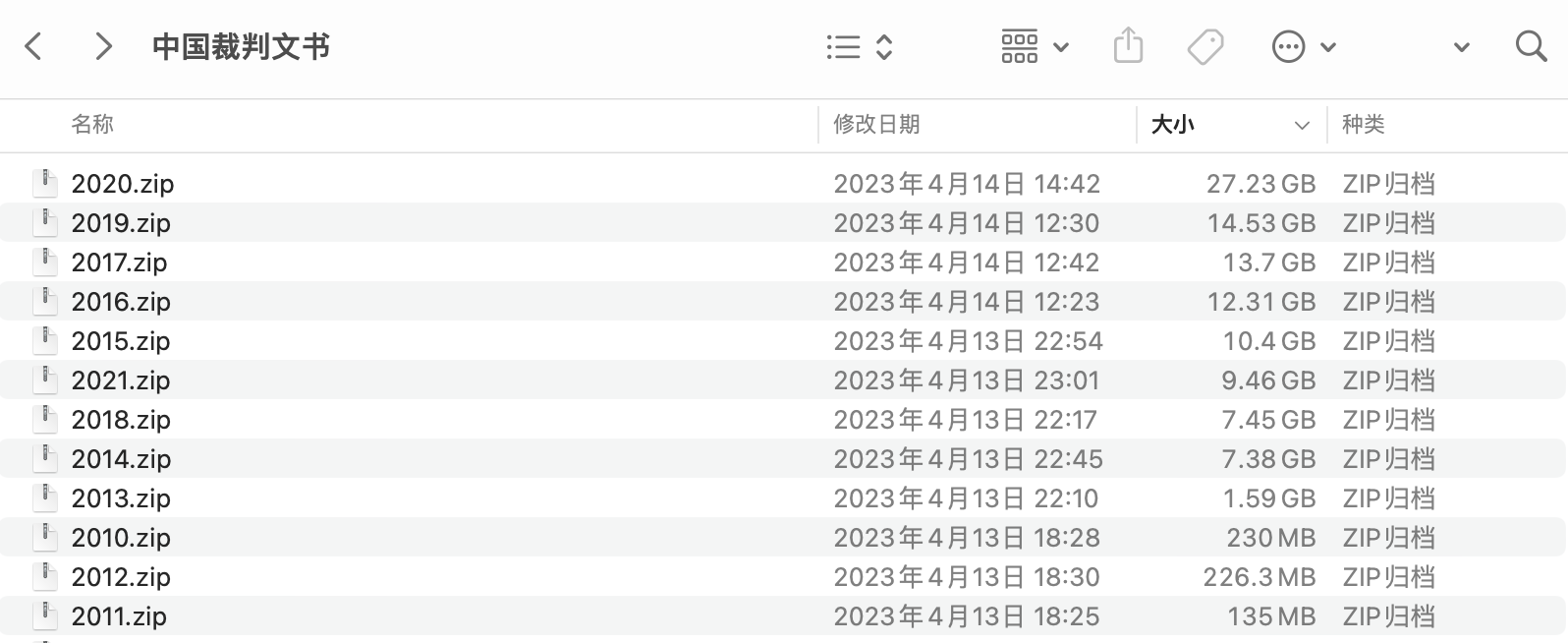
本数据集适合电脑内存16G及以上的同学购买和练习使用。 以2021年为例,打开数据集,可以看到每个数据文件都是很大的。
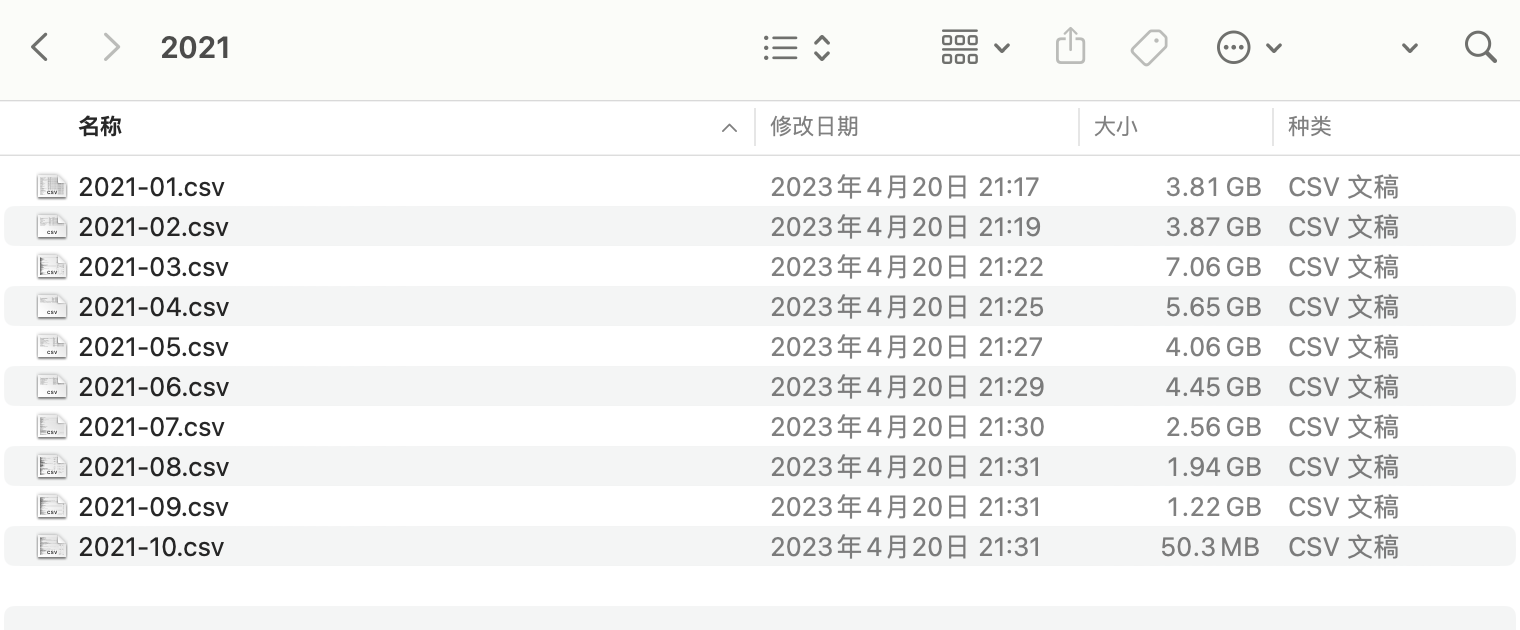
内存8G以下的使用这些大体量数据需要参考这篇文章, 将大文件拆分成多个小文件,再分别读取分析。
这类数据集体量很大,几乎不可能用Excel等软件打开, 建议大家系统学习pandas库, 掌握该库后就能很方便的进行数值和文本类的数据分析。
import pandas as pd
df = pd.read_csv('2021/2021-10.csv')
#随机抽5条显示
df.sample(5)

裁判文书网, 2021年1月份数据量有
len(df)
Run
1158489
字段 「文书内容」 Nan数据占比
len(df[df['文书内容'].isna()])/len(df)
Run
0.2687681971947943
显示第一条非Nan的**「文书内容」**
df[-df['文书内容'].isna()].head(1)
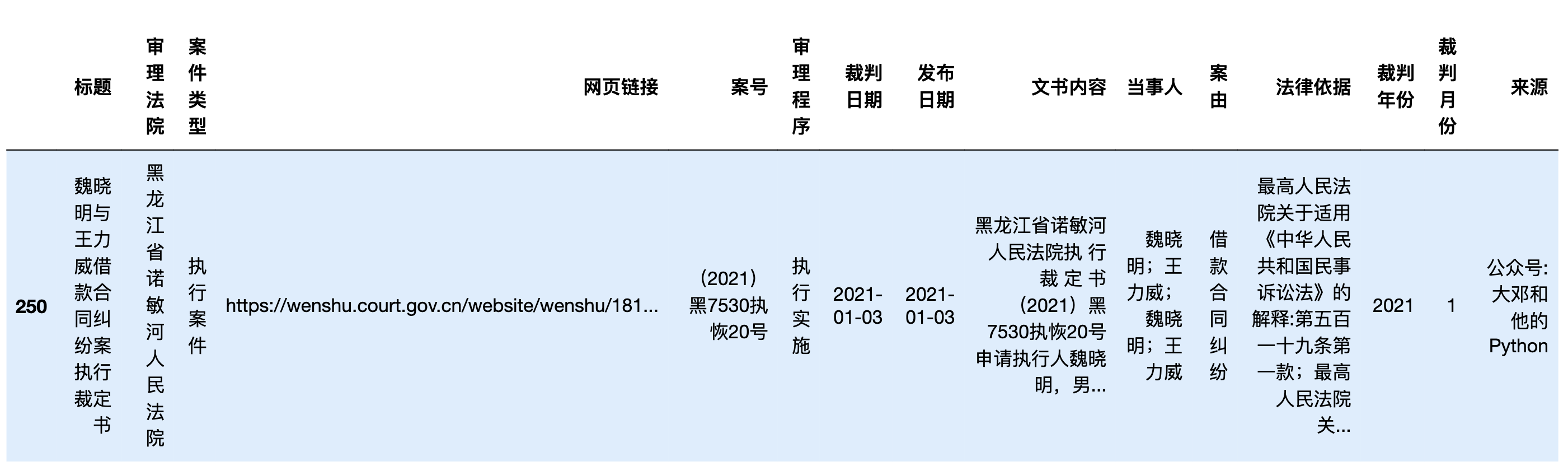
df[-df['文书内容'].isna()].head(1).to_dict()
Run
{'标题': {250: '魏晓明与王力威借款合同纠纷案执行裁定书'},
'审理法院': {250: '黑龙江省诺敏河人民法院'},
'案件类型': {250: '执行案件'},
'网页链接': {250: 'https://wenshu.court.gov.cn/website/wenshu/181107ANFZ0BXSK4/index.html?docId=789c47e53b1f421eaf18aca500f71309'},
'案号': {250: '(2021)黑7530执恢20号'},
'审理程序': {250: '执行实施'},
'裁判日期': {250: '2021-01-03'},
'发布日期': {250: '2021-01-03'},
'文书内容': {250: '黑龙江省诺敏河人民法院执 行 裁 定 书(2021)黑7530执恢20号申请执行人魏晓明,男,1964年1月1日出生,汉族,住沾河林业局。被执行人王力威,男,1977年8月18日出生,汉族,住沾河林业局。本院在执行魏晓明与王力威借款合同纠纷一案中,被执行人应履行债务80000元,执行回款50000元。未发现被执行人有其他财产可供执行。依照《最高人民法院关于适用〈中华人民共和国民事诉讼法〉的解释》第五百一十九条之规定,裁定如下:终结本次执行程序。申请执行人发现被执行人有可供执行财产的,可以再次申请执行。本裁定送达后立即生效。审判长\u3000\u3000谭国军审判员\u3000\u3000丁树桓审判员\u3000\u3000范颖杰二〇二一年一月三日书记员\u3000\u3000张晶洁'},
'当事人': {250: '魏晓明;王力威;魏晓明;王力威'},
'案由': {250: '借款合同纠纷'},
'法律依据': {250: '最高人民法院关于适用《中华人民共和国民事诉讼法》的解释:第五百一十九条第一款;最高人民法院关于适用《中华人民共和国民事诉讼法》的解释:第五百一十九条第二款'},
'裁判年份': {250: 2021},
'裁判月份': {250: 1},
'来源': {250: '公众号: 大邓和他的Python'}}
三、小实验
针对 2021-01.csv 数据,做下面三个小实验
- 案件类型统计
- 前10类案由
- 涉及公司主体的案件占比
- 不同地域案件量的分布情况;
3.1 案件类型统计
pd.DataFrame(df['案件类型'].value_counts(ascending=False))
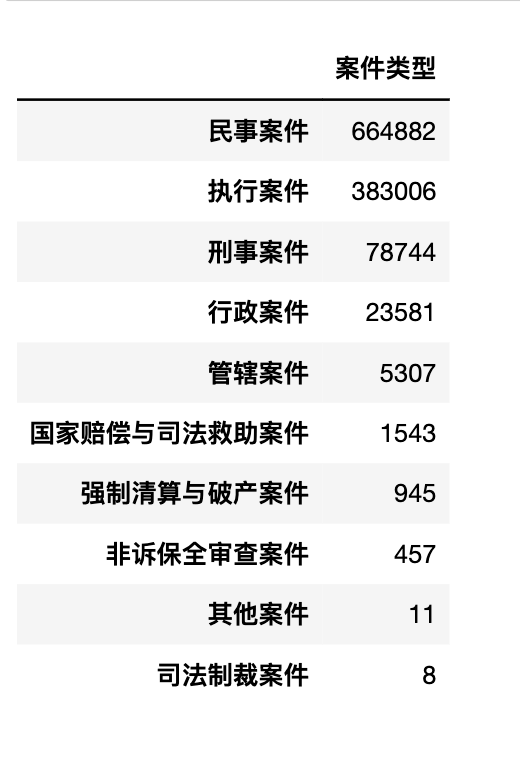
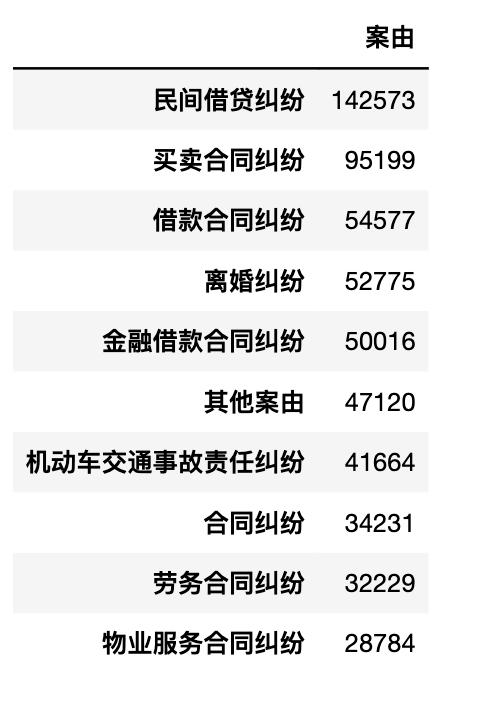
3.2 前10类案由
pd.DataFrame(df['案由'].value_counts(ascending=False)[:10])
3.3 涉及公司主体的案件占比
根据「当事人」是否含「公司」字眼
df['当事人'].str.contains('公司').sum()/len(df)
Run
0.43124190216739217
3.4 不同地域案件量的分布
案号,命名地域+编号,应该可以通过案号计算出不同地域案件量的分布情况。
#slice是字符串切片操作,根据观察感觉是第7个字符是省份简称。
provinces_ratio = df['案号'].str.slice(6, 7).value_counts(normalize=False, ascending=False)
pd.DataFrame(provinces_ratio)
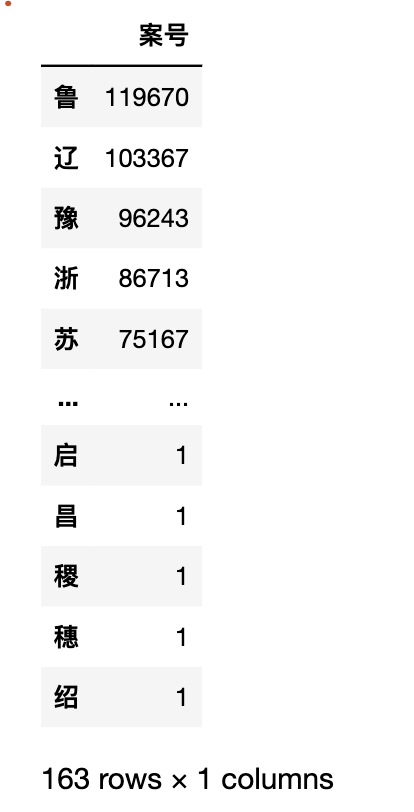
但经过实验,发现地域可以是省,也可以是地级市, 所以刚刚切片的实验鲁莽了。。。 不过以省份命名的案件量排名还是占据前列。
print(pd.DataFrame(provinces_ratio).index.tolist())
Run
['鲁', '辽', '豫', '浙', '苏', '川', '皖', '粤', '湘', '沪', '黔', '鄂', '京', '陕', '新', '吉', '渝', '冀', '赣', '闽', '黑', '云', '晋', '津', '桂', '内', '甘', '宁', '青', '兵', '藏', '最', '琼', '0', '1', '初', ')', ' ', '2', '7', '年', '5', '', '4', '凌', '执', '8', '3', '恢', '特', '9', '温', '刑', '6', '临', '保', '莱', '峄', '东', '郯', '神', '缙', '丽', '泗', '金', '(', '单', '[', '南', '聊', '问', '鱼', '﹝', '长', '乳', '芝', '嘉', '应', '立', '齐', '岚', '湖', '衢', '台', '射', '浦', '民', '号', '晥', '伊', '荣', '柳', '\u200c', '市', '善', '盱', '华', '瑶', '宿', '柯', '垦', '河', '?', '溧', '怀', '中', '右', '司', '西', '微', '异', '行', '集', '乐', '薛', '北', '上', '沂', '沭', '烟', '额', '杭', '甬', '蓟', '永', '济', '诸', '受', '×', '开', '财', '诉', '淅', '枣', '从', '锡', '呈', '滕', '阳', '太', '宜', '峰', '坊', '滨', '德', '淮', '正', '牟', '佛', '运', '威', '兰', '栖', '古', '包', '人', '依', '康', '启', '昌', '稷', '穗', '绍']
