
一、问题
之前分享过 数据集(付费) | 3571万条专利申请数据集(1985-2022年) , 没有涉及匹配数据的问题。 有学员反映,该数据集是否支持匹配上市公司。或者上市公司的专利数量等信息能否从该数据集中抽取, 答案是可以的。 如果对数据集了解,可以直接看第二部分,不熟悉的建议看下数据集大致信息。
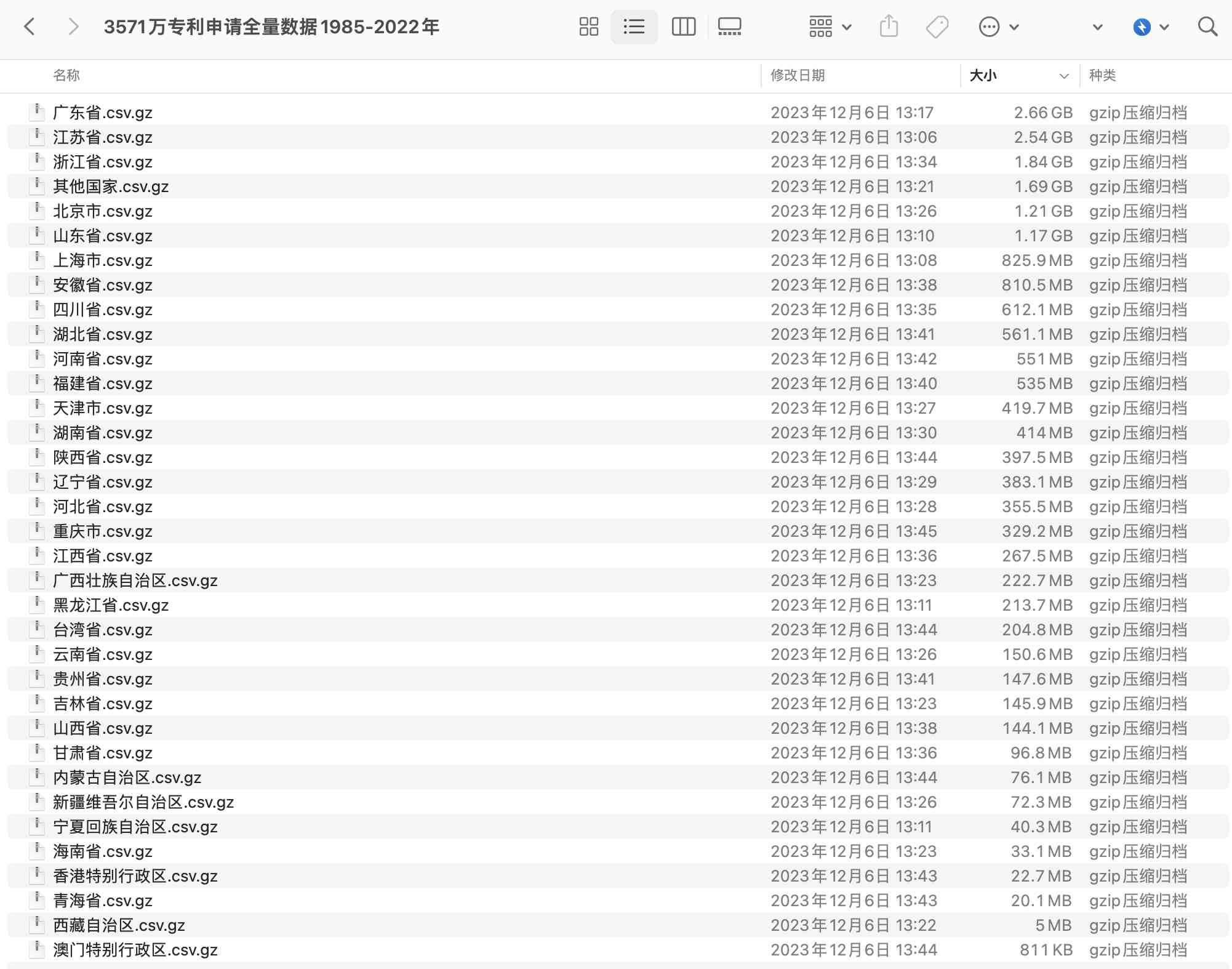
1.1 专利申请数据集
- 数据集名称:省份版知识产权局专利
- 时间跨度:1985-2022,专利申请总量3571万
- 文件格式: csv
- 数据来源:『国家知识产权局』
- 数据整理: 『公众号:大邓和他的Python』
1.2 字段
- 专利公开号
- 专利名称
- 专利类型
- 专利摘要
- 【申请人】
- 专利申请号
- 申请日
- 申请公布日
- 授权公布号
- 授权公布日
- 申请地址
- 主权项
- 发明人
- 分类号
- 主分类号
- 代理机构
- 分案原申请号
- 优先权
- 国际申请
- 国际公布
- 代理人
- 省份或国家代码
- 法律状态
- 专利领域
- 专利学科
- 多次公布
1.3 数据集大小
把所有的 gz 压缩文件解压后, 数据集大概70G,
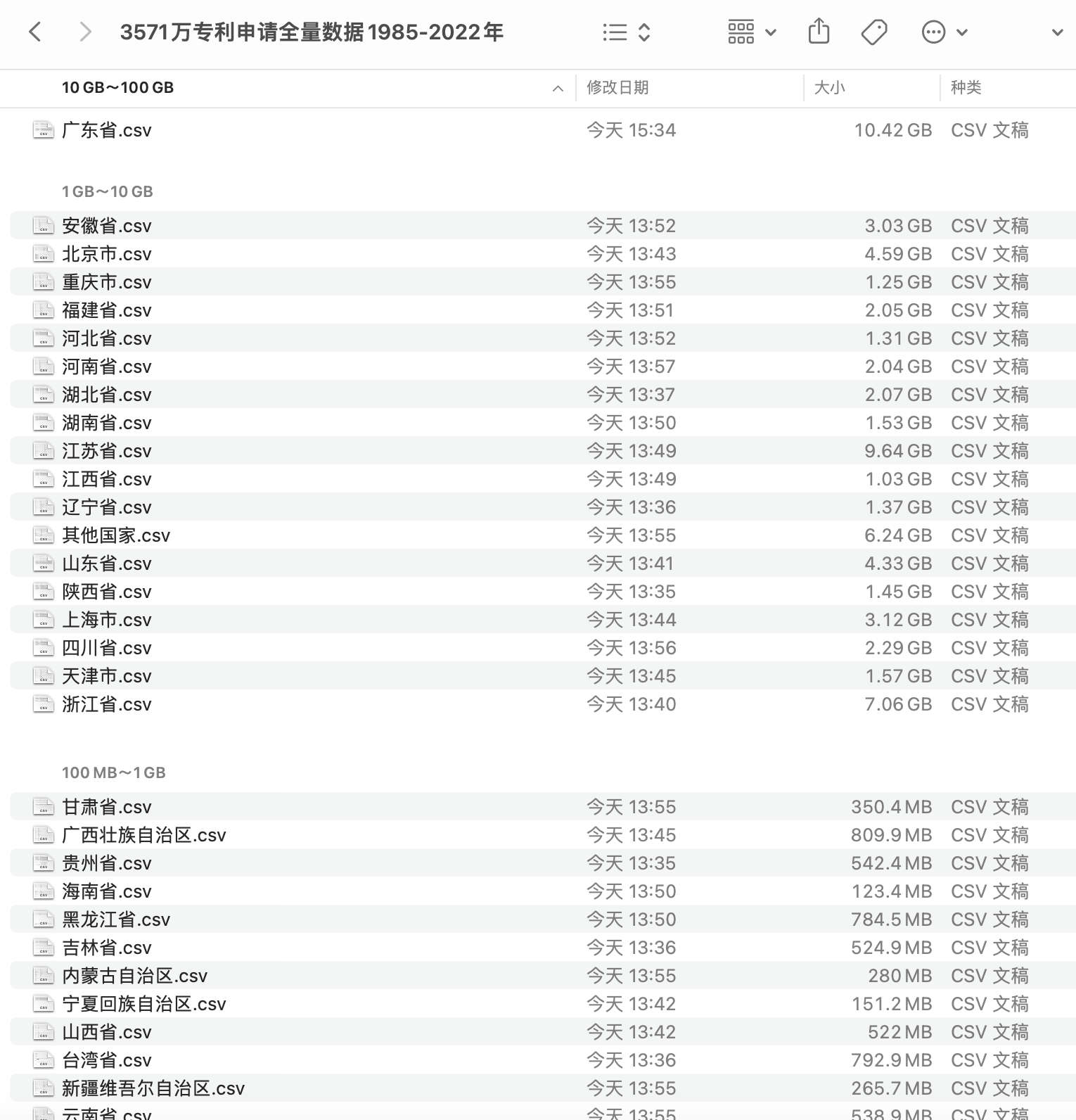
1.3 分省统计
| 省份(区域) | 专利数 |
| :---------------| :------ |
| 广东省 | 5728705 |
| 江苏省 | 4879171 |
| 浙江省 | 3706820 |
| 山东省 | 2064446 |
| 北京市 | 2069913 |
| 四川省 | 1159551 |
| 天津市 | 712932 |
| 上海市 | 1548278 |
| 贵州省 | 265512 |
| 陕西省 | 655837 |
| 吉林省 | 232264 |
| 辽宁省 | 637853 |
| 湖北省 | 966384 |
| 山西省 | 233418 |
| 宁夏回族自治区 | 66919 |
| 西藏自治区 | 9911 |
| 广西壮族自治区 | 377658 |
| 江西省 | 519584 |
| 湖南省 | 743828 |
| 黑龙江省 | 357881 |
| 海南省 | 59202 |
| 福建省 | 1046473 |
| 安徽省 | 1342364 |
| 河北省 | 645420 |
| 重庆市 | 592382 |
| 内蒙古自治区 | 133277 |
| 云南省 | 252407 |
| 甘肃省 | 164274 |
| 新疆维吾尔自治区 | 124734 |
| 河南省 | 966477 |
| 青海省 | 34127 |
| 台湾省 | 401555 |
| 香港特别行政区 | 61636 |
| 澳门特别行政区 | 2010 |
| 其他国家 | 2948557 |
二、读取数据
数据集中的个别csv文件较大,例如 广东省.csv 体积10G。 我们就以建议分析的时候, 电脑内存大于等于16G的, 每次分析时不要开其他软件。
为了演示, 我选择用较小的 黑龙江省.csv 为例。
import pandas as pd
df = pd.read_csv('黑龙江省.csv.gz', compression='gzip', encoding='utf-8', low_memory=False)
#解压后,读取csv的方法
#df = pd.read_csv('黑龙江省.csv', encoding='utf-8', low_memory=False)
df.head()
Run
print('黑龙江省专利数量: ', len(df))
Run
河北省: 357881
#数据集中的字段含
df.columns
Run
Index(['专利公开号', '专利名称', '专利类型', '专利摘要',
'申请人', '专利申请号', '申请日', '申请公布日',
'授权公布号', '授权公布日', '申请地址', '主权项', '发明人',
'分类号', '主分类号', '代理机构', '分案原申请号', '优先权',
'国际申请', '国际公布', '代理人', '省份或国家代码',
'法律状态', '专利领域', '专利学科', '多次公布'],
dtype='object')
大邓现在在大东北,知道黑龙江的上市公司有哈药集团和北大荒。 我们就查一下 「黑龙江省.csv」 专利申请的数据中是否有北大荒和哈药集团。
print('北大荒专利数: ', df['申请人'].str.contains('北大荒集团').sum())
print('哈药集团专利数: ', df['申请人'].str.contains('哈药集团').sum())
Run
北大荒专利数: 4
哈药集团专利数: 712
还真有!!! so, 这个 数据集 | 3571万条专利申请数据集(1985-2022年) 是真的可以匹配上市公司,做一些有价值的变量。 感叹完毕, 继续写点没营养的代码。
三、匹配公司
从上面可以看出哈药集团专利数很多,咱们继续检查哈药集团的专利数据。那么如何筛选出某公司的所有专利申请记录数据呢?这里会用到DataFrame的布尔条件筛选,把值为True的筛选出来。
- 宽松条件
「申请人」含「哈药集团」字眼的 - 严格条件
「申请人」所含字眼就是「哈药集团」四个字
3.1 宽松条件
把「申请人」含「哈药集团」字眼的记录筛选出来
df2 = df[df['申请人'].str.contains('哈药集团')==True]
print(len(df2))
df2.head()
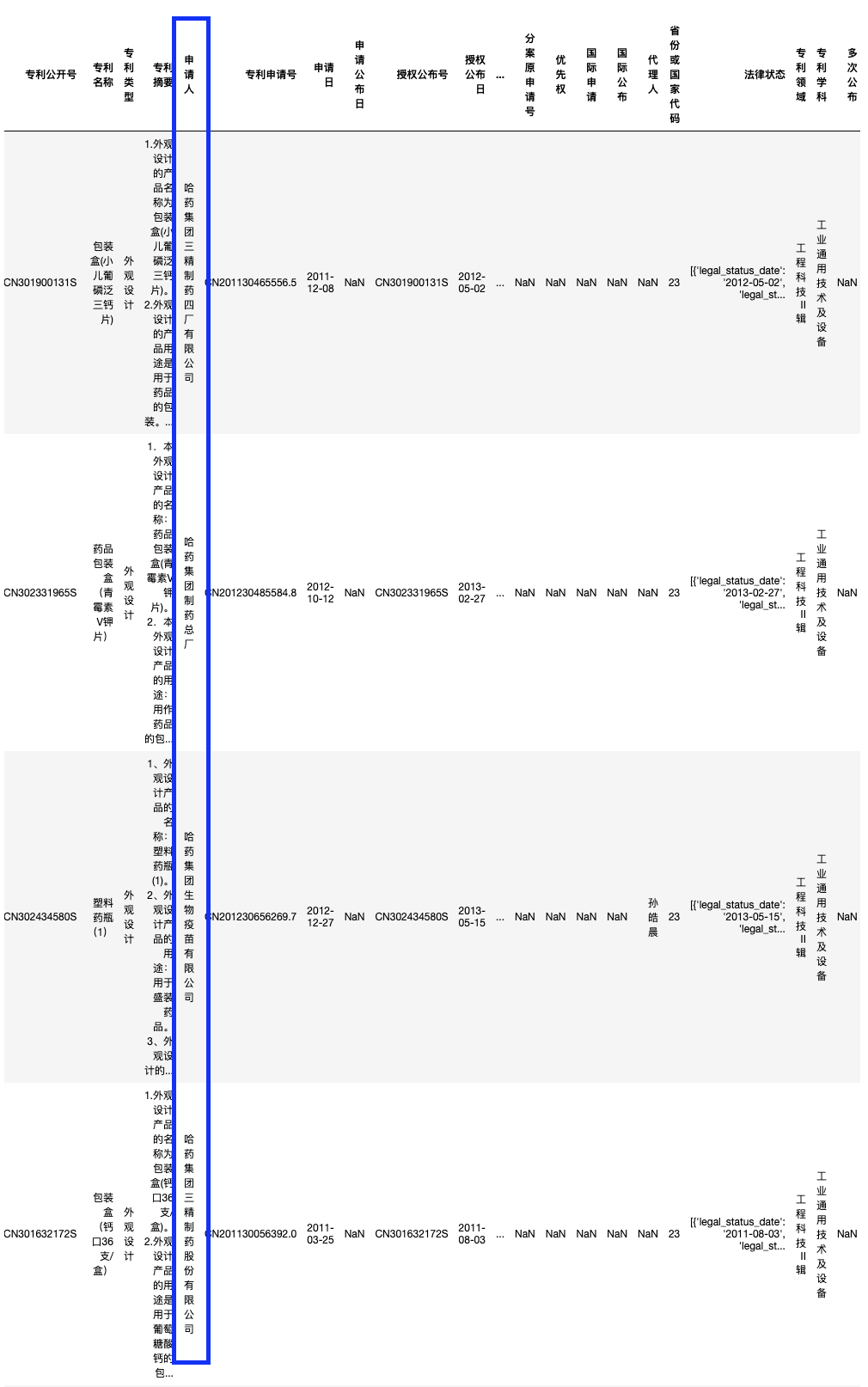
返回结果可以看到,申请人主体是有很多个不同的主体,都是「哈药集团」附属的子公司或分厂。
3.1 严格条件
「申请人」所含字眼就是「哈药集团」四个字
df3 = df[df['申请人']=='哈药集团']
df3.head()

严格条件筛选后,符合的记录数量为0 。 「哈药集团」这四个字是上市公司名称的缩写简写,所以直接这样做筛选,一般得到的结果都是0。 实际上,一个完整的公司名一般是 「属地+公司名+股份有限公司」。例如,
df4 = df[df['申请人']=='哈药集团三精制药四厂有限公司']
print(len(df4))
df4
Run
28
四、其他操作
4.1 类型字段
想了解「哈药集团」相关公司「专利领域」的分布情况
df3 = df[df['申请人']=='哈药集团']
df3['专利领域'].value_counts()
Run
工程科技Ⅱ辑 265
医药卫生科技 250
工程科技Ⅰ辑 157
基础科学 34
农业科技 5
工程科技Ⅰ辑; 工程科技Ⅱ辑 1
Name: 专利领域, dtype: int64
可以看到 「哈药集团」 在医药相关的领域布局较多,农业科技只有5个,从中可以看出 「哈药集团」还是一个技术很专注的企业。
4.2 如何剔除Nan
如果对某个字段感兴趣, 比如「国际申请」
df['国际申请']
Run
0 NaN
1 NaN
2 NaN
3 NaN
4 NaN
...
357876 NaN
357877 NaN
357878 NaN
357879 NaN
357880 NaN
Name: 国际申请, Length: 357881, dtype: object
但肉眼所见全是Nan, 如何剔除掉Nan, 显露出非Nan的记录呢?
解决办法依然是使用DataFrame的逻辑布尔筛选数据。
df[~df['国际申请'].isna()]
五、获取3751w专利数据集
该数据集为付费数据集, 如需数据,点击该链接 数据集(付费) | 3571万条专利申请数据集(1985-2022年) 进行购买。
