
一、上市公司专利数据集
上市公司数: 4393
专利记录数: 2083784
专利申请日: 1991-01-30 ~ 2022-12-31
原始来源: 国家知识产权局
声明
科研用途;如有问题, 请加微信372335839,备注「姓名-学校-专业」
二、数据探索
2.1 读取数据
import pandas as pd
#df = pd.read_csv('上市公司-专利明细数据1991-2022.csv')
df = pd.read_csv('上市公司-专利明细数据1991-2022.csv.gz', compression='gzip')
#剔除重复的
df.drop_duplicates(inplace=True)
df.head(1)

2.2 上市公司数 & 记录数
print(f"上市公司数: { df['股票代码'].nunique() }")
print(f"专利申请数: { len(df) }")
Run
上市公司数: 4393
专利申请数: 2083784
2.3 字段缺失率
print('字段缺失率统计', end='\n\n')
for col in df.columns:
ratio = round(100 * df[col].isna().sum()/len(df), 2)
#print(f"{col}: {ratio}%")
print(f"{col:<{10}}: {ratio}%")
Run
字段缺失率统计
股票代码 : 0.0%
原始企业名称 : 0.0%
专利申请主体 : 0.0%
专利名称 : 0.0%
发明人 : 0.0%
地址 : 0.04%
专利类型 : 0.04%
专利申请号 : 0.04%
申请公布号 : 58.61%
授权公布号 : 41.43%
专利申请日 : 0.0%
公开公告日 : 58.61%
授权公告日 : 41.43%
专利申请年份 : 0.0%
原始来源 : 0.0%
统计截至日期 : 0.0%
更新时间 : 0.0%
2.4 记录的日期范围
df['专利申请日'] = pd.to_datetime(df['专利申请日'], errors='ignore')
df['公开公告日'] = pd.to_datetime(df['公开公告日'], errors='ignore')
df['授权公告日'] = pd.to_datetime(df['授权公告日'], errors='ignore')
print("专利申请日范围: {start} ~ {end}".format(start=str(df['专利申请日'].min())[:10],
end=str(df['专利申请日'].max())[:10]))
print("公开公告日范围: {start} ~ {end}".format(start=str(df['公开公告日'].min())[:10],
end=str(df['公开公告日'].max())[:10]))
print("授权公布日范围: {start} ~ {end}".format(start=str(df['授权公告日'].min())[:10],
end=str(df['授权公告日'].max())[:10]))
Run
专利申请日范围: 1991-01-30 ~ 2022-12-31
公开公告日范围: 1994-08-31 ~ 2023-08-25
授权公布日范围: 1993-12-01 ~ 2023-08-25
日期的三种字段, 专利申请日 缺失率为0, 而 公开公告日 、 授权公告日 都分别高达 58.61%、 41.43%。 个人认为数据集涵盖的日期范围,使用专利申请日 更合适一些。
import matplotlib.pyplot as plt
import matplotlib
import matplotlib_inline
matplotlib_inline.backend_inline.set_matplotlib_formats('png', 'svg')
import scienceplots
import platform
plt.style.use(['science', 'no-latex', 'cjk-sc-font'])
system = platform.system() # 获取操作系统类型
if system == 'Windows':
font = {'family': 'SimHei'}
elif system == 'Darwin':
font = {'family': 'Arial Unicode MS'}
else:
font = {'family': 'sans-serif'}
matplotlib.rc('font', **font) # 设置全局字体
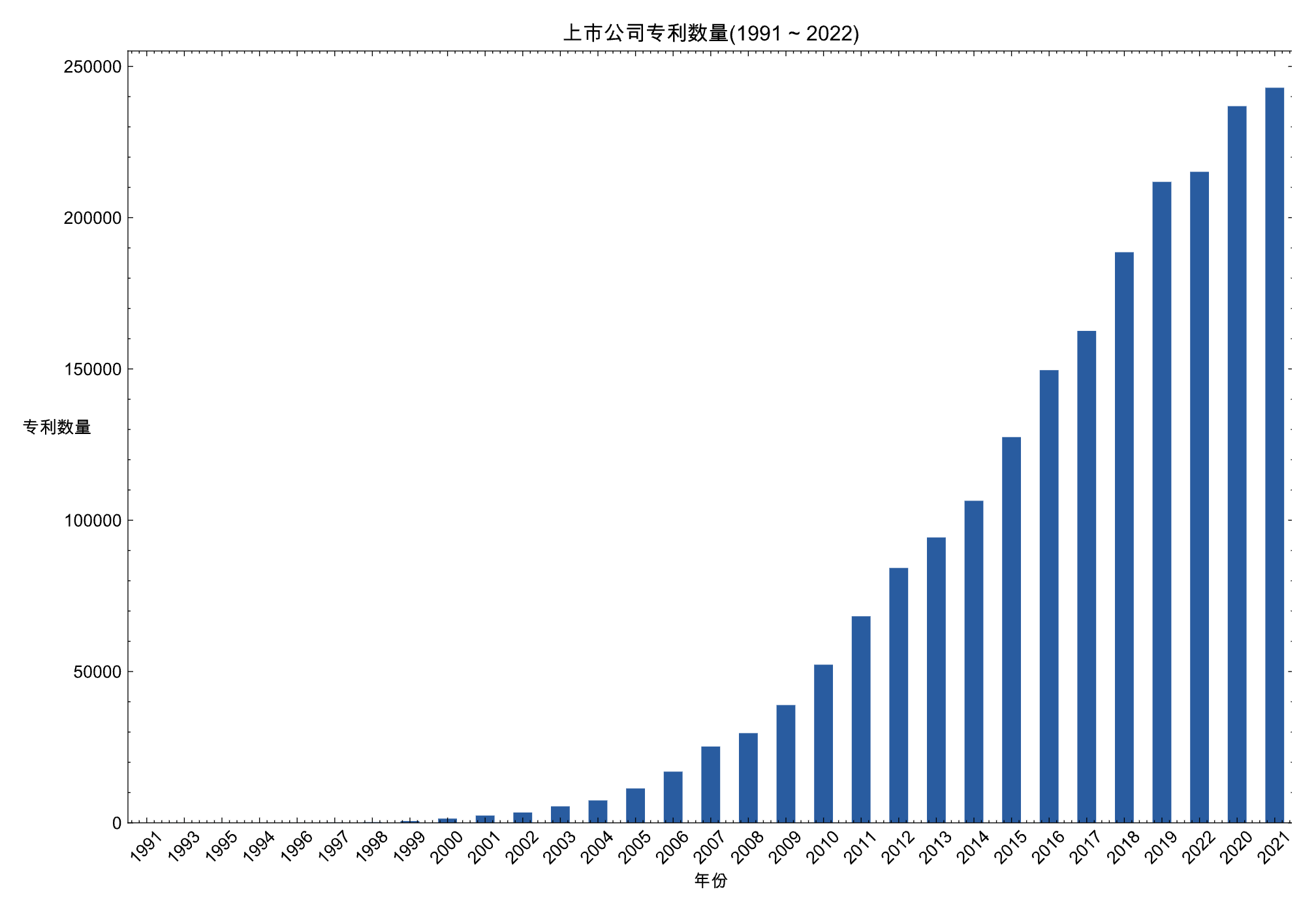
plt.figure(figsize=(12, 8))
df['专利申请日'].dt.year.value_counts(ascending=True).plot(kind='bar')
plt.title('上市公司专利数量(1991 ~ 2022)')
plt.xticks(rotation=45)
plt.xlabel('年份')
plt.ylabel('专利数量', rotation=0)
2.5 多个申请主体
申请主体可以是多个人,只要在 专利申请主体 中出现了 ; , 则表示申请主体是对方的。
import numpy as np
#专利申请人主体可以是单个人(组织),也可以是多人(组织)
df[np.where(df['专利申请主体'].str.contains(';'), True, False)]['专利申请主体']
Run
4 浙江南都电源动力股份有限公司; 杭州南都能源科技有限公司; 杭州南都电池有限公司
8 中国海洋石油总公司; 中海油能源发展股份有限公司
9 格力电器(武汉)有限公司; 珠海格力电器股份有限公司
10 广东美的制冷设备有限公司; 美的集团股份有限公司
13 中国石油化工股份有限公司; 中国石油化工股份有限公司石油化工科学研究院
...
2085560 新疆大全新能源股份有限公司; 内蒙古大全新能源有限公司
2085562 大族激光科技产业集团股份有限公司; 深圳市大族鼎盛智能装备科技有限公司
2085572 中国石油化工股份有限公司; 中国石油化工股份有限公司胜利油田分公司物探研究院
2085573 广东工业大学; 中船海洋与防务装备股份有限公司
2085574 平高集团有限公司; 河南平高电气股份有限公司; 国家电网公司
Name: 专利申请主体, Length: 516473, dtype: object
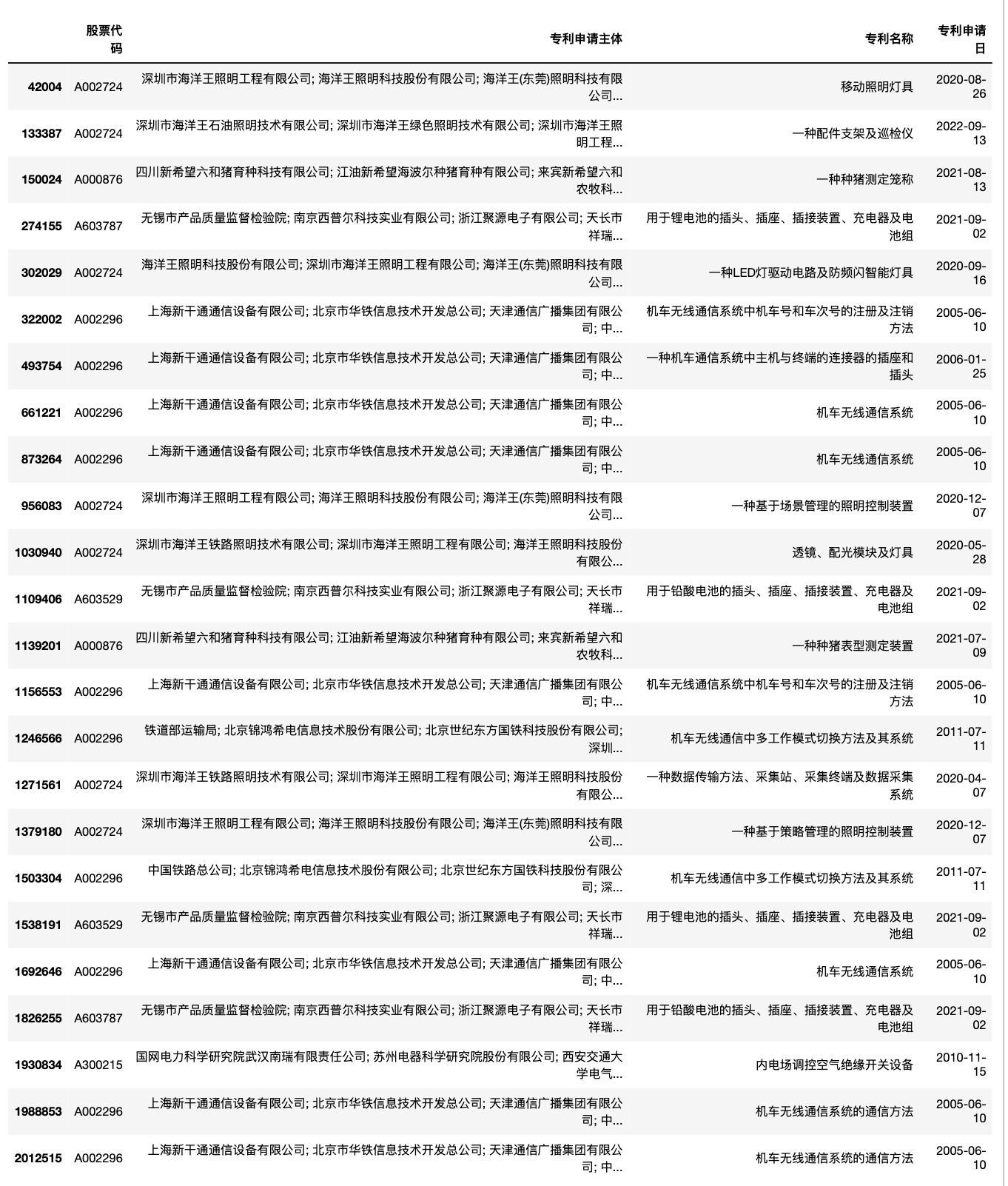
申请主体超过10个的记录,为了展示方便,这里只显示 ['股票代码', '专利申请主体', '专利名称', '专利申请日']这四个字段。
df[df['专利申请主体'].str.count(';')>9][['股票代码', '专利申请主体', '专利名称', '专利申请日']]
申请主体数
df['专利申请主体'].str.count(';')+1
Run
0 1.0
1 1.0
2 1.0
3 1.0
4 3.0
...
2085572 2.0
2085573 2.0
2085574 3.0
2085575 1.0
2085576 1.0
Name: 专利申请主体, Length: 2083784, dtype: float64
申请主体数的汇总
(df['专利申请主体'].str.count(';')+1).value_counts()
Run
专利申请主体
1.0 1567311
2.0 428833
3.0 67820
4.0 13130
5.0 4364
6.0 1894
7.0 282
8.0 59
10.0 27
9.0 23
11.0 14
16.0 9
12.0 7
19.0 4
13.0 2
14.0 2
Name: count, dtype: int64
均值和方差
mainbody_mean = (df['专利申请主体'].str.count(';')+1).mean()
mainbody_std = (df['专利申请主体'].str.count(';')+1).std()
print('申请主体数均值:', mainbody_mean)
print('申请主体数标准差:',mainbody_std)
中学学过正态分布, 在一个正负标准差范围内, 能落下大部分的记录数。咱们看看 均值加减一个标准差 占总体的比例
mask1 = (df['专利申请主体'].str.count(';')+1) > (mainbody_mean-mainbody_std)
mask2 = (df['专利申请主体'].str.count(';')+1) < (mainbody_mean+mainbody_std)
#落在 均值加减一个标准差范围内的数据占比75%
len(df[mask1 & mask2])/len(df)
Run
0.7521465756527548
三、相关文献
使用专利数据的相关文献
[1]Bellstam, Gustaf, Sanjai Bhagat, and J. Anthony Cookson. "A text-based analysis of corporate innovation." _Management Science_ 67, no. 7 (2021): 4004-4031.
[2]Arts, Sam, Bruno Cassiman, and Jianan Hou. "Position and Differentiation of Firms in Technology Space." Management Science (2023).
