
科研用途,仅供展示;如有任何问题,加微信372335839,备注「姓名-学校-专业」
一、Github
GitHub 是一个具有代表性的开发者社区,帮助了软件的在线开发,吸引了全球超过 3100 万开发者。 GitHub 将每个用户活动视为一个事件,例如新存储库或创建的分支的创建事件。 GitHub 总共支持 42 种事件类型。 典型的用户活动包括创建新存储库、克隆现有存储库、从 GitHub 提取存储库的最新更改以及提交本地所做的更改并将其推送到共享存储库。
通过 GitHub,开发人员可以相互交流,通过在存储库下发布问题来分配和领取编程任务。 此外,还支持常规的“关注”功能,允许用户接收该平台上任何用户的状态更新通知。 在这些在线社区中,开发者之间的互动主要集中在协作开发和代码共享上,形成了一种特殊的社交网络。这些特点使得github数据可用于广泛的研究领域,包括但不限于科技创新、组织管理、社交媒体等。
二、GH Archive
获取github数据,我们最容易想到是利用网站提供的api。 github提供了免费的api接口, 每小时的请求数量是有限制的(匿名用户60次,授权用户5000次)。 这对于想做大数据分析的我们而言, 限制太多, 短时间内难以获得大规模的数据。
- GHArchive活动档案自 2011 年 2 月 12 日起提供。
- 2011 年 2 月 12 日至 2014 年 12 月 31 日之间的活动档案是通过(现已弃用)时间线 API 记录的。
- 从 2015 年 1 月 1 日开始的活动档案是通过事件 API 记录的。
可供下载GH Archive数据集体积远超 2T, 按年度
4.6G 2011
13G 2012
26G 2013
57G 2014
75G 2015
112G 2016
145G 2017
177G 2018
254G 2019
420G 2020
503G 2021
657G 2022
很大 2023
2.1 资源网址规律
GH Archive 是一个开源的一个项目,用于记录公共GitHub时间轴,对其进行存档,并使其易于访问以进行进一步分析。GitHub Archive获取所有的GitHub events信息存储在一组JSON文件中,以便根据需要下载并脱机处理。GH Archive数据是以小时为粒度,
| 数据获取任务 | 命令行下载命令 |
|---|---|
| 获取2021.11.21下午4点(世界标准时间)的数据 | wget https://data.gharchive.org/2021-11-21-16.json.gz |
| 获取2021.11.21的数据 | wget https://data.gharchive.org/2021-11-21-{0..23}.json.gz |
| 获取2021.11月的数据 | wget https://data.gharchive.org/2021-11-{0..30}-{0..23}.json.gz |
每个下载下来的数据都是.gz的压缩文件,解压后会得到 .json文件。 需要注意, 一个小时的数据大概百兆级别, 如果是整天、正月,json的文件会非常大。 建议按小时为粒度进行数据采集。
2.2 构造urls
假设我要批量自动下载数据, 可以用python生成有规律的url列表, 然后用requests方式存储对应的.gz文件数据。 假设我们需要采集 2021年11月21日全天的数据, 使用小时粒度存储数据集。 需要注意, 本文教程默认是在jupyter notebook中撰写运行。
import requests
date = '2021-11-21'
urls = []
for hour in range(0, 24):
url = f'https://data.gharchive.org/{date}-{hour}.json.gz'
urls.append(url)
urls
Run
https://data.gharchive.org/2021-11-21-0.json.gz
https://data.gharchive.org/2021-11-21-1.json.gz
https://data.gharchive.org/2021-11-21-2.json.gz
...
...
https://data.gharchive.org/2021-11-21-20.json.gz
https://data.gharchive.org/2021-11-21-21.json.gz
https://data.gharchive.org/2021-11-21-22.json.gz
https://data.gharchive.org/2021-11-21-23.json.gz
2.3 python下载
使用requests库下载一个数据集
import requests
def download(url):
file = url.split('/')[-1]
with open(file, 'wb') as gf:
resp = requests.get(url)
gf.write(resp.content)
#尝试下载
url = 'https://data.gharchive.org/2021-11-21-0.json.gz'
download(url)
批量下载2021年11月21日全天的数据, 使用小时粒度存储数据集。
for url in urls:
download(url)
三、读取操作
3.1 数据解压
得到的 .gz数据可以使用以下代码进行解压,解压后会得到 .json 数据文件。
import os
import gzip
gz_fs = [f for f in os.listdir('.') if '.gz' in f]
for gz_f in gz_fs:
file = gz_f.replace('.gz', '')
content = gzip.GzipFile(gz_f).read()
with open(file, 'wb') as jsonf:
jsonf.write(content)
3.2 读取json
因为数据文件都很大,一次性读取会很消耗时间, 推荐阅读 如何处理远超电脑内存的csv文件 。
pd.read_json(jsonf, nrows, lines, chunksize)
- jsonf: 文件路径
- nrows: 读取前nrows行
- lines: 以行的方式读取,默认False
- chunksize: 分批次读取,每批次的规模是chunksize行
3.2.1 读取前n行
使用pandas读取 2021-11-21-0.json 前5条数据, 了解下数据集的字段
import pandas as pd
df = pd.read_json('2021-11-21-0.json', lines=True, nrows=5)
df

3.2.2 查看折叠的字段
乍一看好像没啥数据,其实都折叠在字段之中。以actor为例,我们看看内部会折叠哪些字段
df['actor'].values
Run
array([
{'id': 5355937,
'login': 'austinkregel',
'display_login': 'austinkregel',
'gravatar_id': '',
'url': 'https://api.github.com/users/austinkregel',
'avatar_url': 'https://avatars.githubusercontent.com/u/5355937?'},
{'id': 89859977,
'login': 'Nicoperez19',
'display_login': 'Nicoperez19',
'gravatar_id': '',
'url': 'https://api.github.com/users/Nicoperez19',
'avatar_url': 'https://avatars.githubusercontent.com/u/89859977?'},
{'id': 46858494,
'login': 'kapone3047',
'display_login': 'kapone3047',
'gravatar_id': '',
'url': 'https://api.github.com/users/kapone3047',
'avatar_url': 'https://avatars.githubusercontent.com/u/46858494?'},
{'id': 1843851,
'login': 'DerekEdwards',
'display_login': 'DerekEdwards',
'gravatar_id': '',
'url': 'https://api.github.com/users/DerekEdwards',
'avatar_url': 'https://avatars.githubusercontent.com/u/1843851?'},
{'id': 94767098,
'login': 'hectorapweb',
'display_login': 'hectorapweb',
'gravatar_id': '',
'url': 'https://api.github.com/users/hectorapweb',
'avatar_url': 'https://avatars.githubusercontent.com/u/94767098?'}
],dtype=object)
3.2.3 恢复一个折叠的信息
以actor为例
df['actor'].apply(lambda x: pd.Series(x))

3.2.4 合并结果
_ = df['actor'].apply(lambda x: pd.Series(x))
df = pd.concat([df, _], axis=0)
df
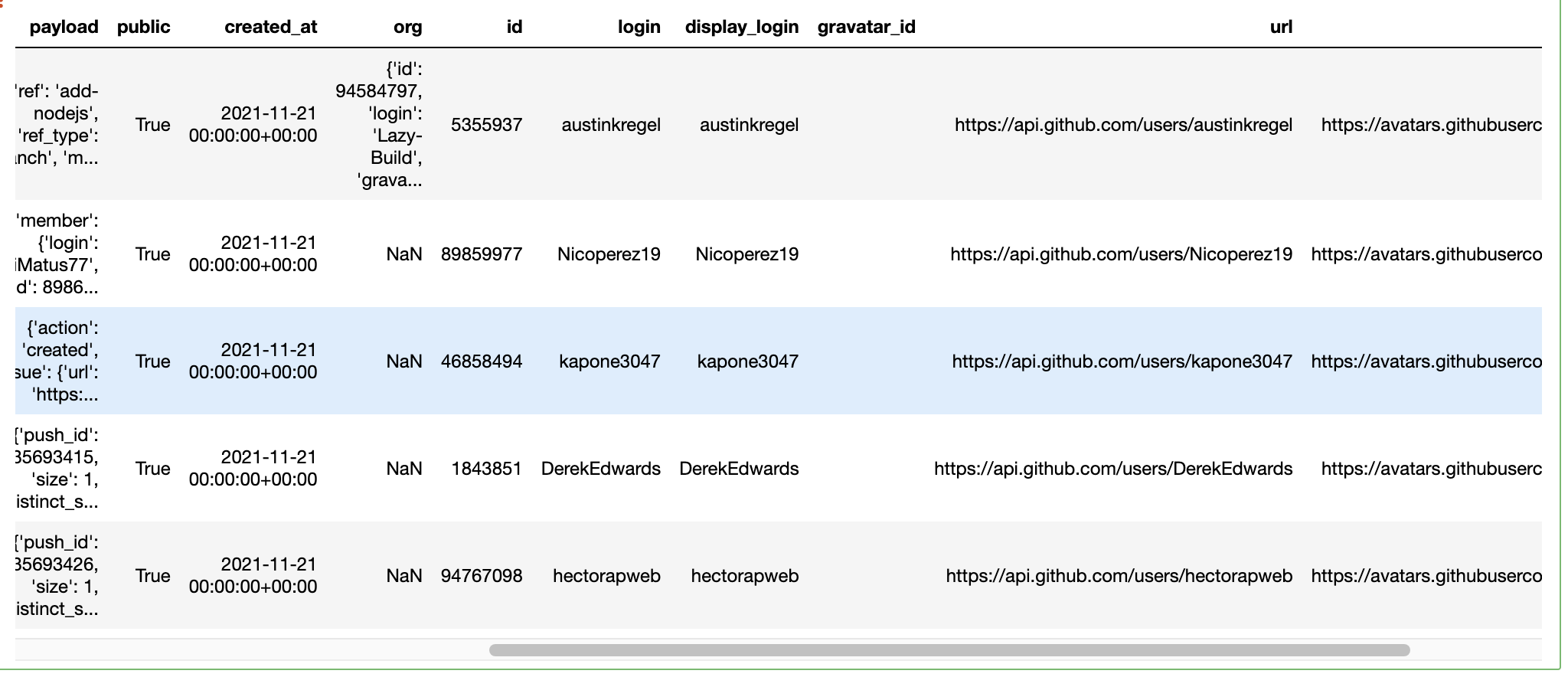
更新后的df含有的字段有
df.columns
Run
Index(['id', 'type', 'actor', 'repo', 'payload', 'public', 'created_at', 'org',
'id', 'login', 'display_login', 'gravatar_id', 'url', 'avatar_url'],
dtype='object')
四、相关数据集
Github 1000万用户
Gong, Q., Zhang, J., Chen, Y., Li, Q., Xiao, Y., Wang, X. & Hui, P., Nov 2019, CIKM ‘19:Proceedings of the 28th ACM International Conference on Information and Knowledge Management. ACM, p. 1251-1260 (ACM International Conference on Information & Knowledge Management).
使用 GitHub API,我们构建了超过 1000 万 GitHub 用户的无偏见数据集。该数据收集于2018年7月20日至8月27日期间,涵盖10,649,574名用户、118,602,740次提交和20,999,258个存储库。每个数据条目都以 JSON 格式存储,代表一个 GitHub 用户,并包含用户个人资料页面中的描述信息、她的提交活动以及创建/分叉的公共存储库的信息。
数据集下载地址 https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/T6ZRJT
