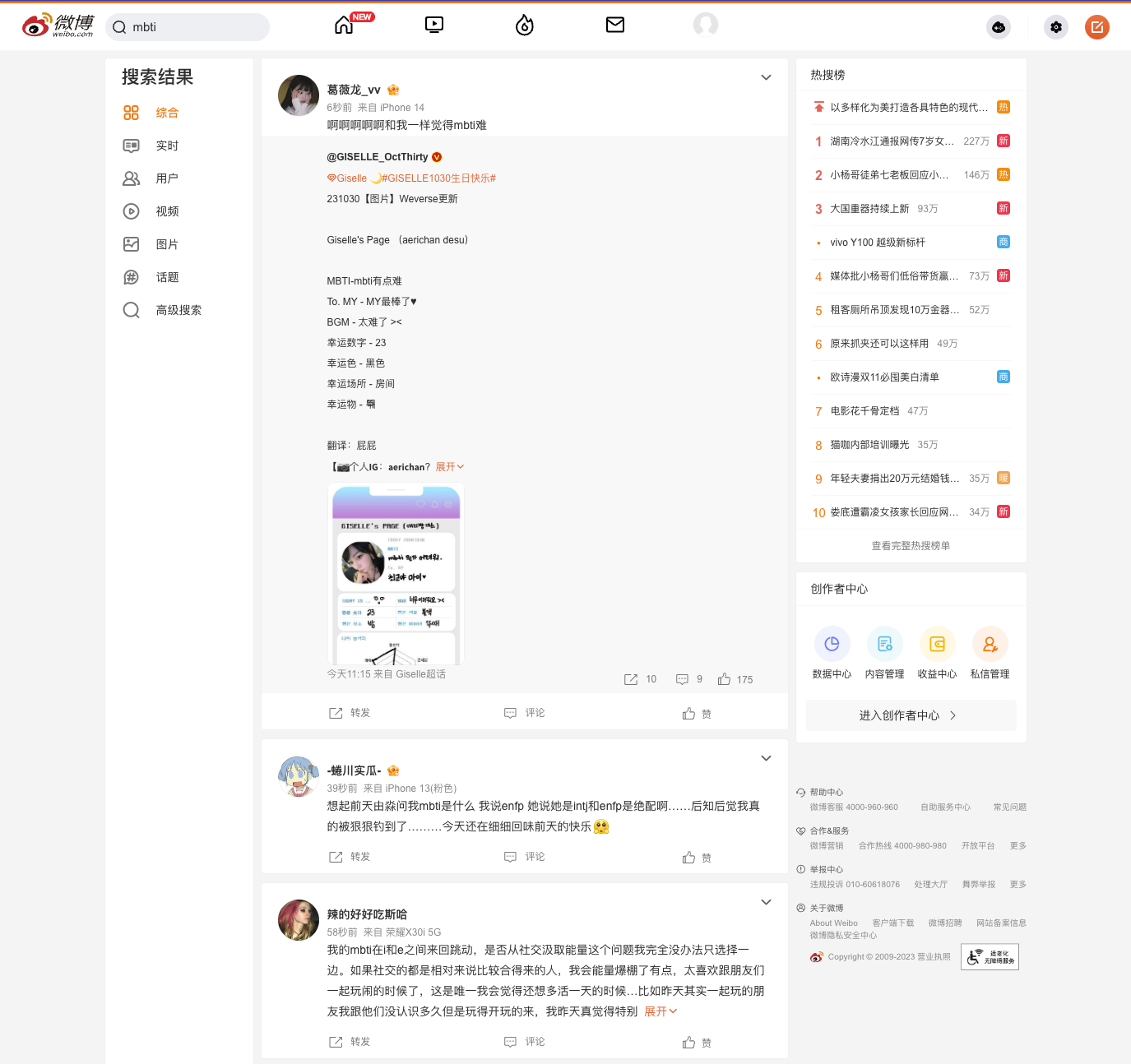
案例代码 | 使用正则表达式判别微博用户mbti类型
...
...
...

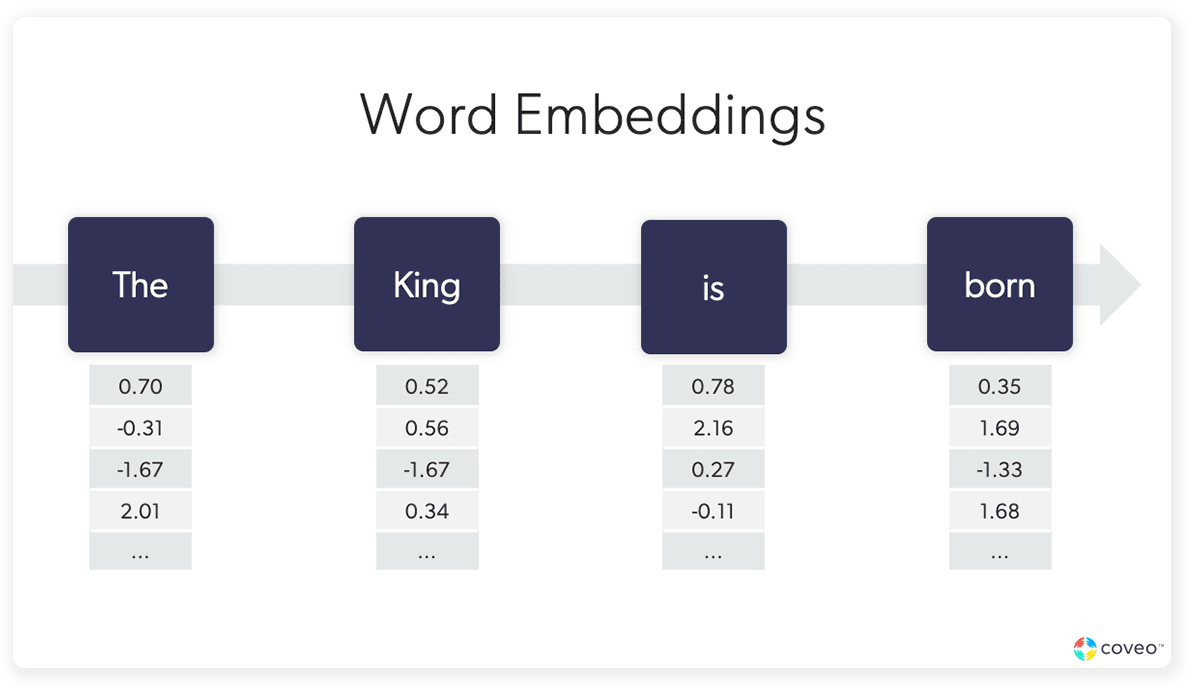
自然语言处理的发展为探究语义距离与创造性思维的关系提供了可靠且有效的研究方法。 近些年关于两者之间关系的研究逐渐增多, 但研究结论并不一致。本研究基于创造力联想理论及扩散激活模型, 通过元分析的方法探讨了语义距离与创造性思维的整体关系, 并且分析了以往研究结论不一致的原因。 结果显示:语义距离与创造性思维存在中等程度的正相关,二者的相关强度受到被试年龄和创造性思维不同测量指标的调节。 研究结果表明语义距离与创造性思维关系 密切, 同时解释了以往研究结论不一致的原因。 上述结果不仅能为更深入地探讨创造性思维的认知神经机制 提供新的研究视角和理论解释, 而且有助于更全面地理解语义距离与创造性思维二者的关系及其边界条件, 为更好地解释、预测和提升创造力提供科学依据和重要启示。...
情感分析从根本上改变了市场营销者评估消费者意见的能力。的确,通过自然语言测量态度已经影响了市场营销在日常实践中的方式。**然而,最近的研究发现,情感分析目前强调测量情感的正负面(即积极或消极)可能会产生不完整、不准确甚至误导性的见解**。从概念上讲,这项研究挑战情感分析超越对情感正负面的侧重。作者识别出消费者情感的确定性或信心是一个特别有力的评估方面。从经验上,**他们开发了一种新的计算语言中确定性的测量工具——确定性词典(Certainty Lexicon)**,并验证了其与情感分析的使用。为了构建和验证这种测量,作者使用了来自1160万人的文本,他们生成了数十亿的词汇,数百万的在线评论,以及在线预测市场的数十万条记录。在社交媒体数据集、实验室实验和在线评论中,作者发现与其他工具相比,确定性词典在其测量中更为全面、可推广和准确。作者还展示了对市场营销者来说,测量情感确定性的价值:确定性预测了广告的实际成功,而传统的情感分析则未能做到这一点。...

机器学习正在深刻改变管理学的研究范式与方法。如何运用机器学习更好地赋能管理学研究已经成为学术界关注的前沿热点议题。然而,机器学习在中国管理学研究中的应用仍处于初级阶段。**本文基于1999~2021年发表在工商管理和会计财务两大研究领域的国内外顶级期刊的学术文献,识别了学术界借助机器学习开展管理学实证研究的4种核心途径:变量测量、事件预测(包括事件分类)、因果推断和理论构建**;梳理了每个途径的代表性文献的研究主题、研究问题、数据集、机器学习算法和研究结论;提出了使用机器学习赋能管理学研究的主要策略,并讨论了中国学者运用机器学习开展中国特色管理理论研究的未来机会。本文显示:将机器学习与传统计量经济学相结合有助于做出更加精准的因果推断;机器学习能够在模式发现这一理论构建的关键步骤中发挥重要作用;将机器学习与多案例分析相结合有助于富有成效地开展理论构建。本文为如何采用机器学习提升管理学研究质量、推进管理学研究范式变革和构建中国特色管理理论提供了方法论指引和方向性启示。...