一、文献
张楠,黄梅银,罗亚,马宝君.全国政府网站内容数据中的知识发现:从注意力分配到政策层级扩散[J].管理科学学报,2023,26(05):154-173.
摘要:价值不断提升的政府网站内容数据不仅可以描绘政策注意力,也为中央政策向地方层级扩散的测量与评估提供了新的机遇.在我国多层级政府组织治理模式下,地方政府对中央政策的贯彻落地是政策生效的前提条件.对纵向政策扩散的有效测量和评估将有助于理解政策扩散机制,提升政策落地效果.本文基于全国省、市级政府门户网站每日内容更新数据,通过概率主题建模方法建构主题概率矩阵,刻画政府对不同主题的注意力分配差异,并基于概率主题建模结果构建函数测量地方政府对中央政策的扩散速度与扩散程度。本文讨论了测度建构的原理和细节,并引入机器学习方法进行鲁棒性检验,通过多政策主题扩散的混合回归分析了影响短周期政策层级扩散的因素.研究以测度建构为突破口打通文本数据挖掘到有价值公共管理知识的“中间层”,对政策信息学在政策扩散及评估监测中的应用前景进行了初步探索.
二、数据处理
2.1. 数据准备
基于获取到的 170 万余条政府网站内容数据, 本文选择潜在狄利克雷分配模型 (LDA)进行数据分析,以获取网络政府的政策议题注意力分布情况,数据处理路径见图 1.
数据抓取单位为政府门户网站每一个页面的内容信息, 包括页 面 URL 地址、标题、发布时间、文章发布单位或转载来源、关键词、作者、摘要、具体内容等. 数据入库前,还通过元素提取(如网页名称、大小、日期、 标题、文字内容等)、数据排重和信息过滤(广告过滤、URL 过滤等)等前期处理工作.
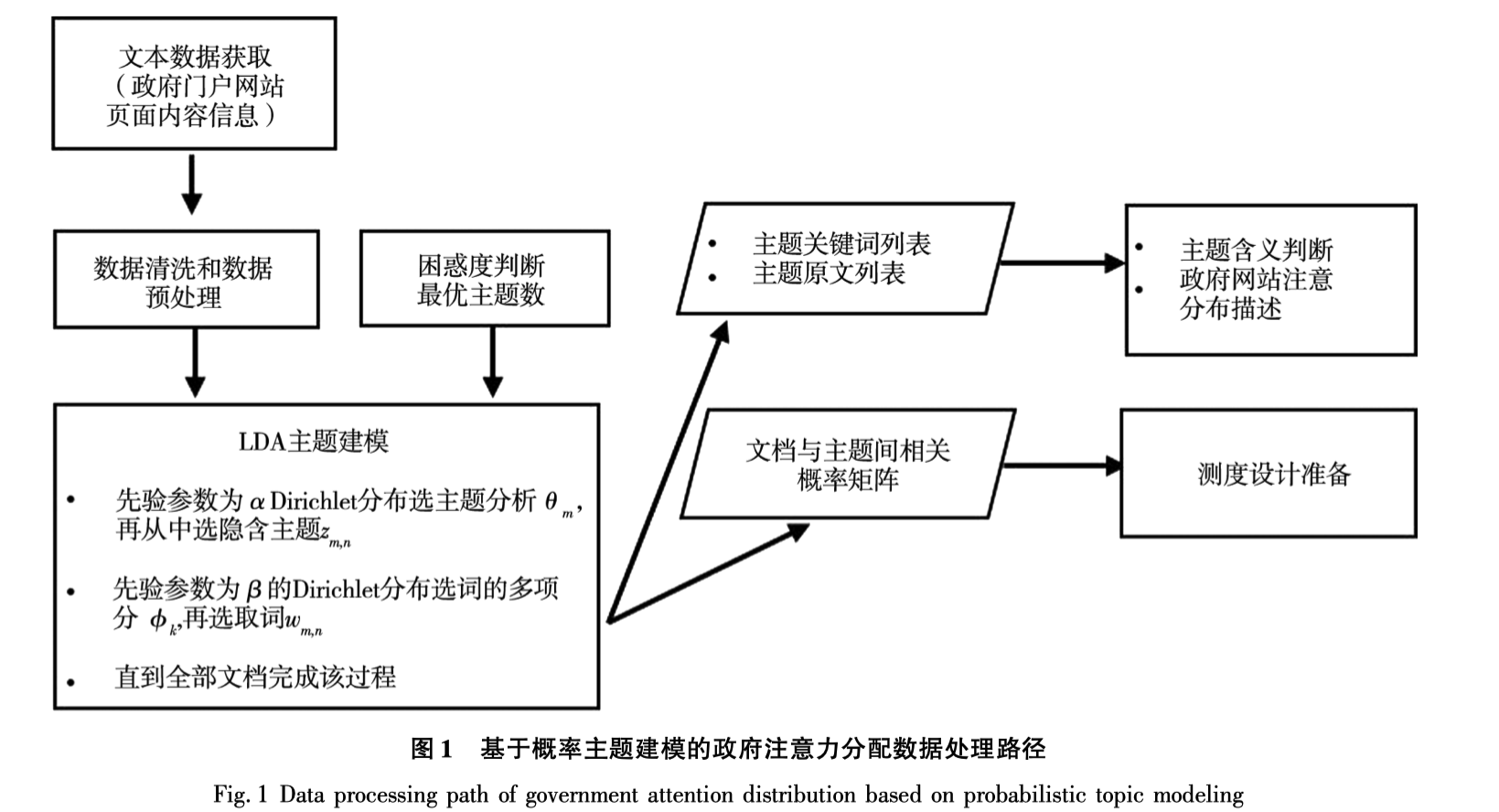
2.2. LDA建模
LDA建模有两个步骤
- 首先最关键的是确定文档主题数,即平均困惑度。论文中平均困惑度为120。
- 确定好文档主题数即可开展LDA训练, 对170w训练出LDA模型,同时得到文档-主题概率矩阵, 该矩阵的形状,有120列, 170多万行。
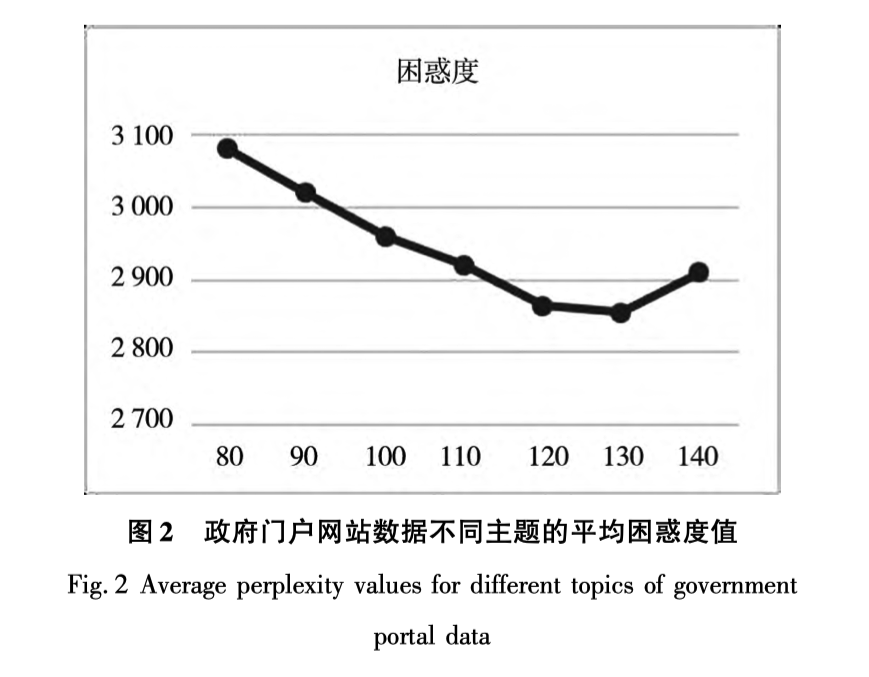
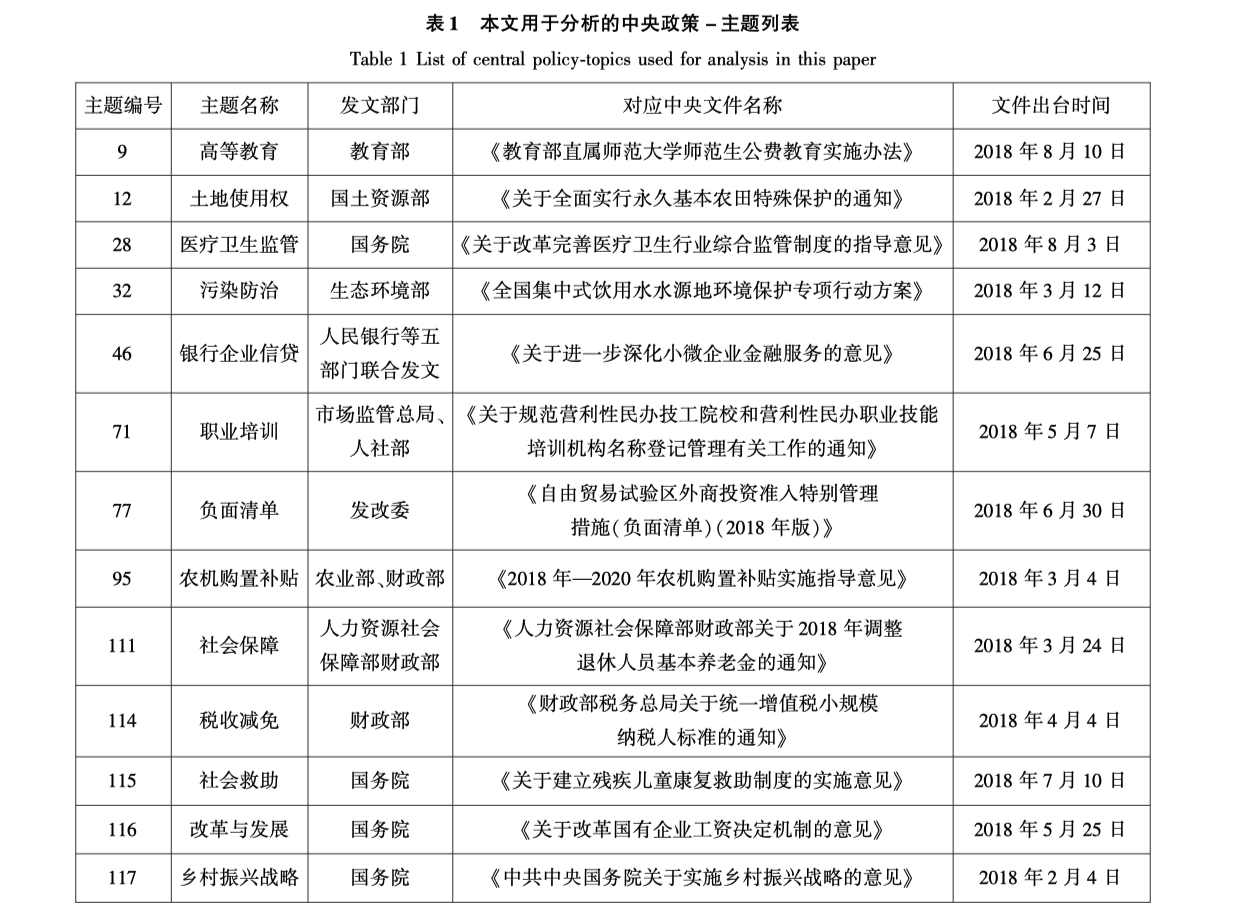
训练完LDA模型,虽然文档主题数设置为120, 但经过甄别,最终确定有112个主题具有可解释性。
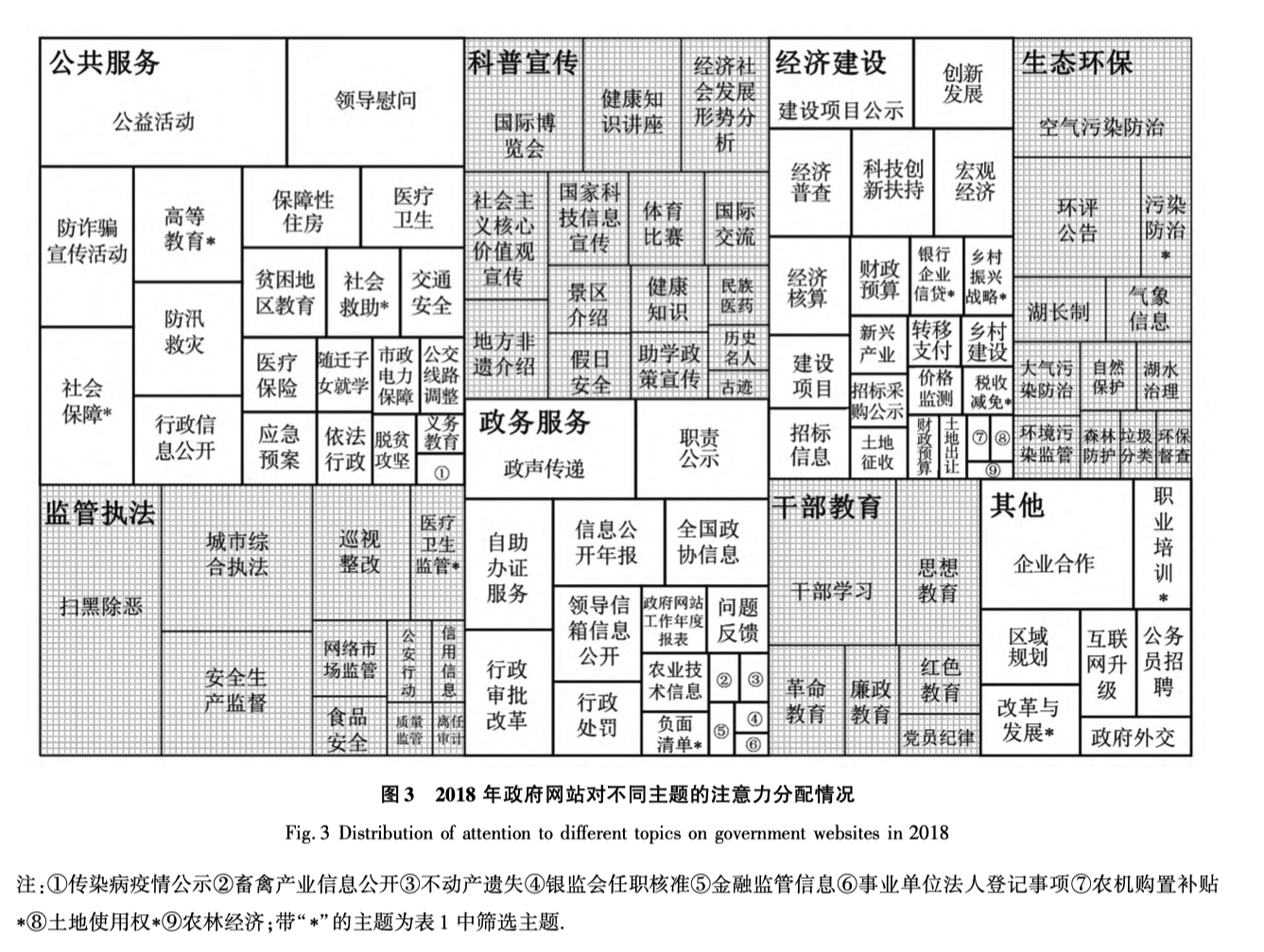
下图是主题含义,及概率占比(面积大小)。
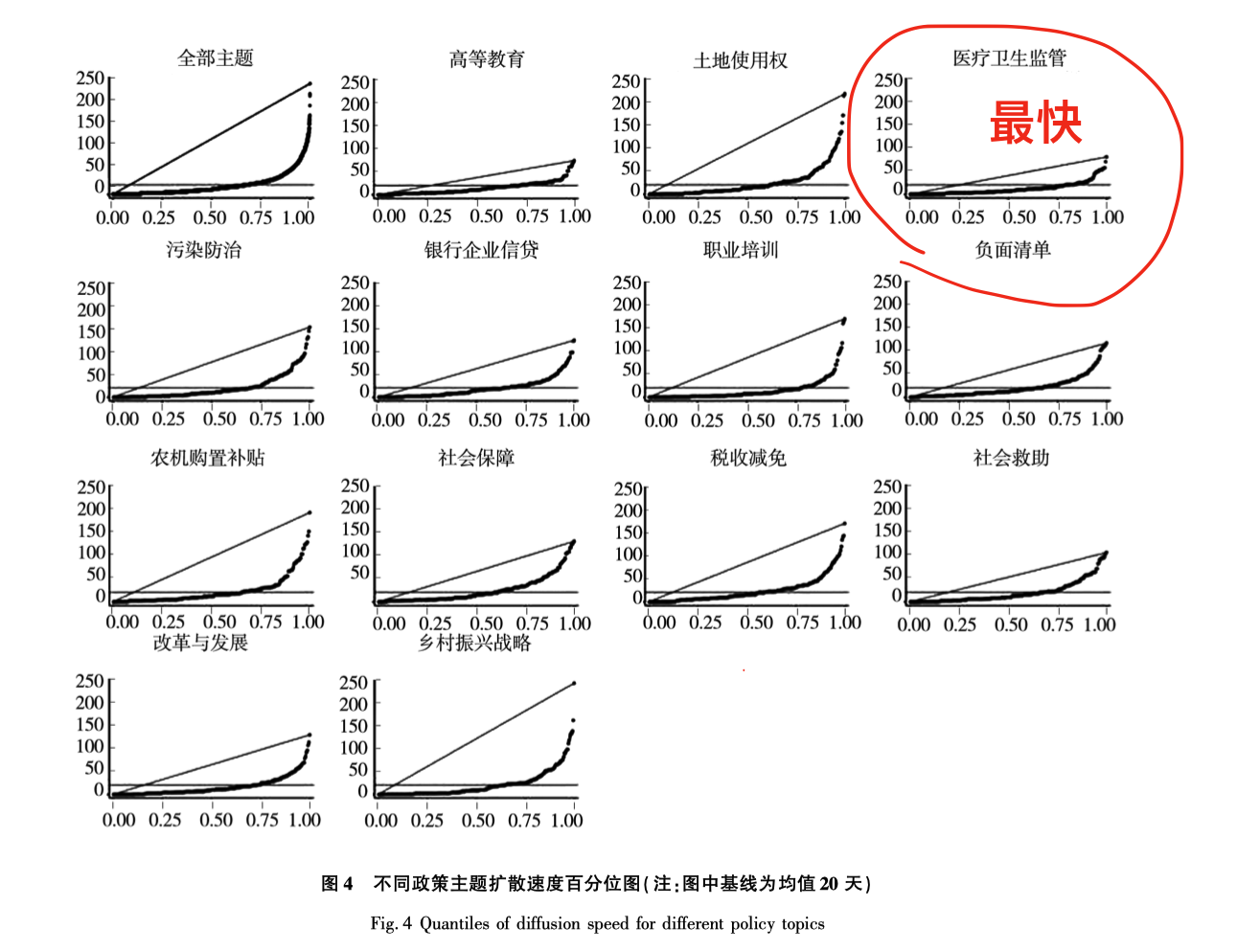
2.3. 扩散速度与扩散程度函数构建



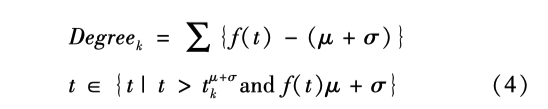
面对中央政府希望通过政府网站和其他网络政府入口监测政策落实、督查政府履职、评估回应能力的一系列需求, 本文尝试基于网络政 府大数据的对中央政策扩散情况展开分析. 图4 展示了 2018 年地级市对中央 13 项政策的回应扩散速度情况. 曲线越扁平,地级市政府扩散响应 时间越短, 层级扩散速度越快. 平均扩散速度为 20.04 天,意味着中央出台政策后地级市政府网站 上平均 20 天就会对中央政策予以回应. 其中, 地 级市政府回应最快的是医疗卫生监管主题, 平均 扩散时间为 12.07 天,最慢的是土地使用权主题,达 25.11 天. 从 0.5 分位数来看,当不同政策主题的中央政策激励产生后, 超过一半的城市在 20 天内快速响应中央政策, 不同政策主题扩散速度存在差异.