
只需更改一行代码, pandarallel库 就可以充分利用CPU性能,并行化所有 Pandas 操作,加速你的数据处理。
pandarallel 还提供漂亮的进度条(在笔记本和终端上可用)以 大致了解要完成的剩余计算量。
没有并行化

并行化
可以看到,使用并行化后,处理速度快了很多。
一、性能对比
cpu有n个核,大概并行化会提升大概n倍。以下是使用和不使用 Pandaral·lel 的比较基准。实验环境:
- 操作系统:Linux Ubuntu 16.04
- 硬件:Intel Core i7 @ 3.40 GHz - 4 核
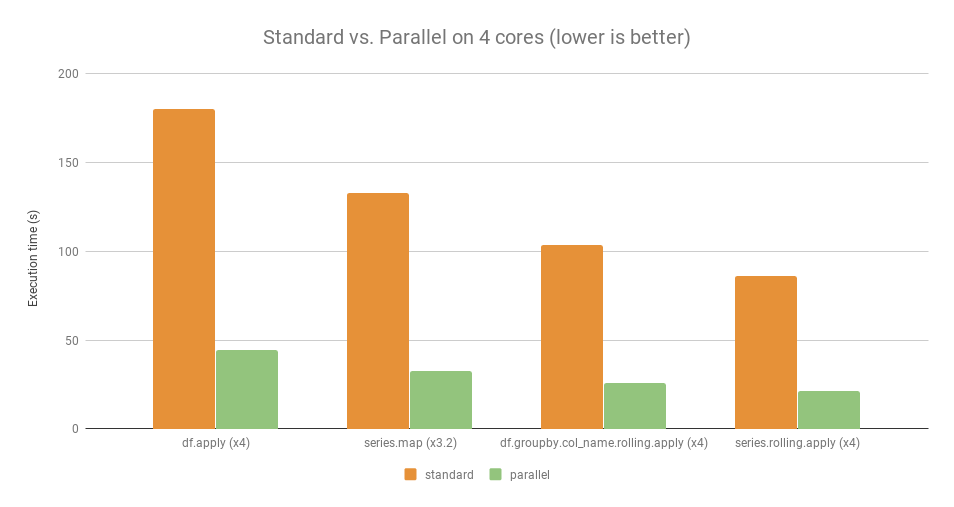
并行操作的运行速度大约是标准操作的 4 倍(除了标准操作的运行速度仅快 3.2 倍)。
二、特性
pandarallel 目前实现以下 API:pandas
| 没有并行化 | 并行化 |
|---|---|
df.apply(func) |
df.parallel_apply(func) |
df.applymap(func) |
df.parallel_applymap(func) |
df.groupby(args).apply(func) |
df.groupby(args).parallel_apply(func) |
df.groupby(args1).col_name.rolling(args2).apply(func) |
df.groupby(args1).col_name.rolling(args2).parallel_apply(func) |
df.groupby(args1).col_name.expanding(args2).apply(func) |
df.groupby(args1).col_name.expanding(args2).parallel_apply(func) |
series.map(func) |
series.parallel_map(func) |
series.apply(func) |
series.parallel_apply(func) |
series.rolling(args).apply(func) |
series.rolling(args).parallel_apply(func) |
三、语法
Mac 和 linux,没有什么特殊的用法, 但在 Windows 上, 您掉用的函数必须是自包含的,并且不应依赖于外部资源。为了降低大家的记忆压力, 咱们假设所有系统,都要满足自包含且不依赖外部资源。
3.1 安装
pip install pandarallel
3.2 错误用法
import pandas as pd
from pandarallel import pandarallel
#初始化,且显示进度条
pandarallel.initialize(progress_bar=True)
import math
def func(x):
# func不能依赖外部资源, math定义在函数体func之外, 会出问题的!
return math.sin(x.a**2) + math.sin(x.b**2)
df = pd.read_csv('实验的csv文件路径')
df['result'] = df['某个数值字段'].parallel_apply(func)
3.3 正确用法
定义好计算函数 func, 标准的 pandas 的计算是在 pd.Series 基础上掉用 apply 方法,即 pd.Series.apply(func)。
而 pandarallel 稍微修改了方法名, pd.Series.parallel_apply(func)。
import pandas as pd
from pandarallel import pandarallel
#初始化,且显示进度条
pandarallel.initialize(progress_bar=True)
def func(x):
import math
# 在函数体func内导入math,掉用math, okay!
return math.sin(x.a**2) + math.sin(x.b**2)
df = pd.read_csv('实验的csv文件路径')
df['result'] = df['某个数值字段'].parallel_apply(func)
四、实验
对一个 xlsx 文件的 text 字段进行词频统计, 结果保存到新字段 wordCount 中。
4.1 读取数据
mda01-22.xlsx数据有55439条记录, 体积573M。
import pandas as pd
df = pd.read_excel('mda01-22.xlsx')
print(len(df))
df.head()
Run
55439

4.2 没有并行
%%time
import pandas as pd
import jieba
def word_count(text):
return len(jieba.lcut(text))
df = pd.read_excel('mda01-22.xlsx')
df['wordCount'] = df['text'].apply(word_count)
df.head()
Run
CPU times: user 11min 56s, sys: 10.5 s, total: 12min 7s
Wall time: 12min 7s

4.3 并行化
%%time
import pandas as pd
from pandarallel import pandarallel
#初始化,且显示进度条
pandarallel.initialize(progress_bar=True)
def parallel_word_count(text):
import jieba
return len(jieba.lcut(text))
df = pd.read_excel('mda01-22.xlsx')
df['wordCount'] = df['text'].parallel_apply(word_count)
df.head()
Run
INFO: Pandarallel will run on 12 workers.
INFO: Pandarallel will use standard multiprocessing data transfer (pipe) to transfer data between the main process and workers.
CPU times: user 12.4 s, sys: 1.41 s, total: 13.8 s
Wall time: 2min 40s
Wow, 运行总时间从 12min 7s 降低 2min 40s 。
4.4 使用场景
并行化是有代价的(实例化新进程、通过共享内存发送数据、 …),只有在并行化的计算量大时才有效足够高。对于小规模的数据,使用并行化并不总是值得的。经过测试, 找了一个61kb的xlsx, 结果并行化反而还慢了。
pandarallel 通过使用计算机cpu所有内核来绕过此限制。 但代价是,需要两倍于标准操作的内存占用。
