
问题
大多数学员电脑内存是8G和16G,但最近分享的数据集都是体量较大,下图是数据集 | 3571万条专利申请数据集(1985-2022年) 截图,单个csv文件体积很容易过G,个别文件10+G 。
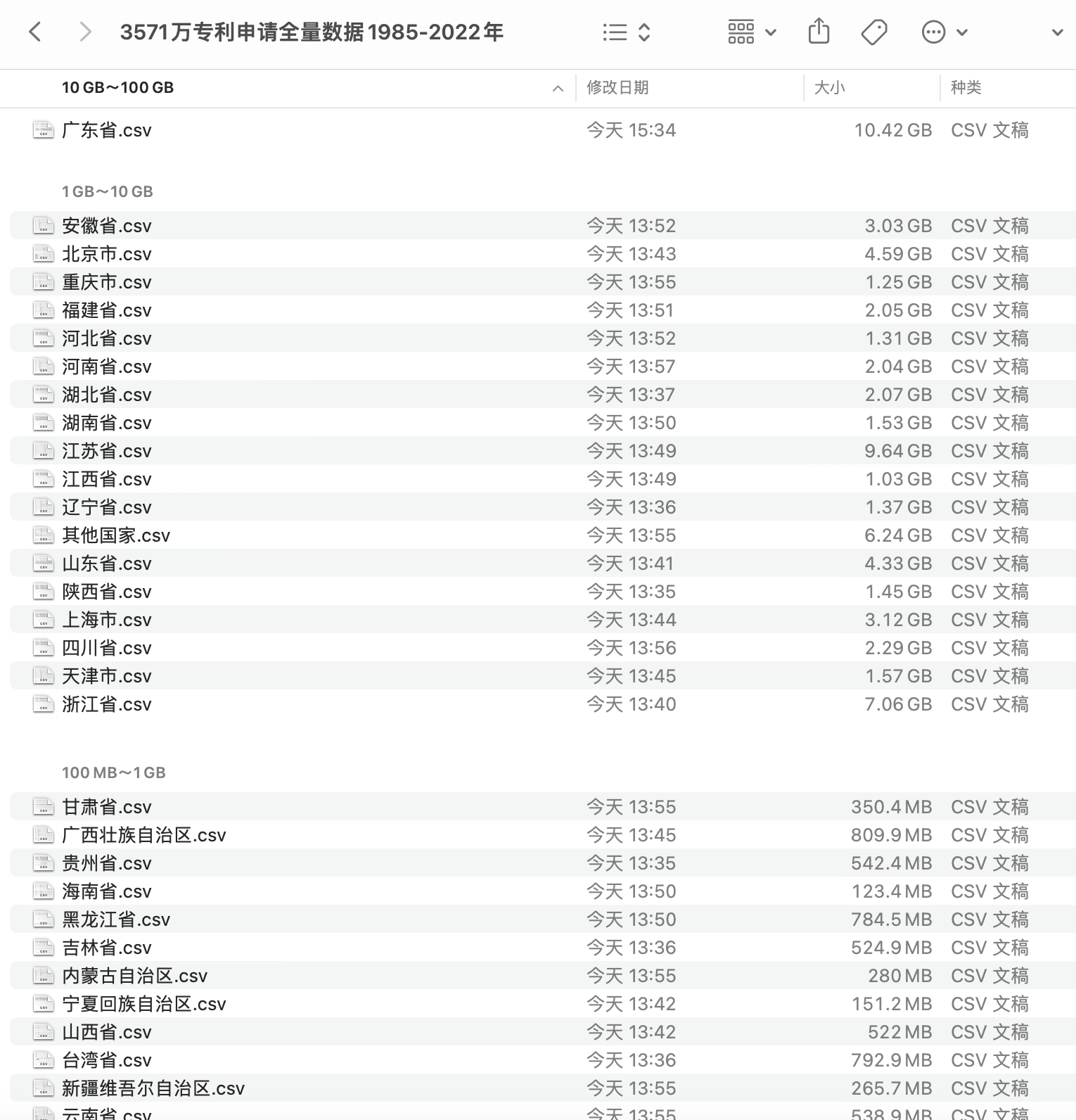
那小内存电脑如何导入这种超过内存大小的csv文件呢?
解决办法是将文件拆分为更小的csv文件。拆分步骤
- 按照chunksize行将csv分成很多块,内存每次只读取其中一块。
- 对任意的块, 导出为小体量的csv文件。
之后, 小内存电脑也能使用之前分享的大体量数据集。
代码
import pandas as pd
# 块dataframe的体量
chunksize = 10000
# 原csv路径和新csv文件前缀
csv_file = 'large_file.csv'
new_csv_prefix = 'small_file_'
# 定义计数器和文件编号
count = 0
file_number = 1
# 读取csv文件并拆分成多个小块的DataFrame
for chunk in pd.read_csv(csv_file, chunksize=chunksize):
# 将每块DataFrame保存为一个单独的csv文件
chunk.to_excel(f'{new_csv_prefix}{file_number}.xlsx', index=False)
file_number += 1
上述代码会将大型CSV文件拆分成多个小块的DataFrame,每个DataFrame包含10000行数据。
然后,它将每个小DataFrame保存为单独的csv文件,文件名以“small_file_”作为前缀,后面跟着一个编号。