
应用价值
对于大量散落在网络中的文本数据, 可以度量用户在视觉、运动、社交、情感、时间和空间等维度上心理、认知、抽象层面的信息。
Wang, S., Zhang, Y., Shi, W. et al. A large dataset of semantic ratings and its computational extension. Sci Data 10, 106 (2023). https://doi.org/10.1038/s41597-023-01995-6

一、摘要
来自心理学和认知神经科学的证据表明,人类大脑的语义系统包含几个特定的子系统,每个子系统都代表语义信息的特定维度。对这些不同语义维度上的词语评分可以帮助研究语义维度对语言处理的行为和神经影响,并根据人类认知系统的语义空间建立语言含义的计算表示。现有的语义评分数据库提供了数百到数千个词语的评分,但这无法支持对自然文本或语音的全面语义分析。本文报告了一个大型数据库——六维语义数据库(SSDD, 后文「数据库」均用「词典」代替),其中包含对 17,940 个常用汉语词语在六个主要语义维度上的主观评分:视觉、运动、社交、情感、时间和空间。此外,使用计算模型学习主观评分和词嵌入之间的映射关系,我们在SSDD中包括了1,427,992个汉语和1,515,633个英语词语的估计语义评分。SSDD将有助于自然语言处理、文本分析和大脑中的语义表示研究。
二、背景
大量行为和神经证据表明,单词语义表示分布在不同的神经子系统中, 每个子系统代表着特定的语义信息维度。这些语义子系统和维度为人类语义系统的组织提供了重要线索。为了研究单词在人脑中的 意义表示 和 信息加工, 许多研究基于心理和神经生物学可行的语义维度,通过人员标准构建了单词的词典。与现有NLP领域的embeddings相比, 基于特定意义维度所构建的词典可以在经验语义纬度上提供量化的评分, 使得研究者可以调查语义维度对语言处理的行为和神经影响, 并建立语言含义的(表示)计算。
然而现有的词典只包含数百、数钱个词,不足以支持自然文本或语音的全面语义分析。该研究提供了一个大型的语义评分语义词典, 名为六维语义(Six Semantic Dimension Database,SSDD)词典, 每个中英文词语含六个维度的得分(可以理解为效价valence),分别是视觉、运动、社交、情感、时间、空间。 其中视觉和运动维度反映了感觉运动体验对语义表示的影响。感觉和运动维度可能是最常研究的语义维度之一,它们对于对象和动作概念的重要性已经得到了很好的确认。在与语义表示相关的多个感官维度中,我们选择了视觉维度,因为视觉是主导的感觉模态。视觉和运动语义对认知处理的行为和神经影响已经被许多研究证实。社交和情感维度反映了社会情感体验对语义表示的影响。这些维度具有可分离的神经相关性,并且对于心理和抽象概念的表示尤其重要。Huth等人采用数据驱动方法研究了大脑中的语义表示组织,并发现社交情感和感官运动语义与最重要的数据驱动语义维度的两端相关联。因此,社交和情感维度可以作为视觉和运动维度的重要补充,以反映语义表示。时间和空间维度对于事件和情境的表示尤为重要。神经心理学和神经影像研究也表明这些维度具有可分离的神经相关性。Binder等人对经验语义属性进行了全面的综述,反映了六个维度的代表性。Binder等人总结了属于14个领域的65个语义维度,其中超过2/3的维度属于视觉、运动、社交、情感、时间和空间领域。SSDD将这六个领域作为粗粒度语义维度,并为每个维度提供了一般评分。
三、构建方法
3.1 标准者(被试人员)
该研究找了85位心理、神经都正常的本硕中国学生, 通过数据质量评估,最终保留了80位学生的数据标注结果。
3.2 待标注的17940中文词
待标注中文词,一共有17940个, 是由三种数据源筛选得来
- 中文维基百科12814高频词
- fMRI领域研究(发表&未发表)的4915个中文词
- 最后一组项目是来自Binder等人和Tamir等人的语义评分实验中英文刺激词的211个汉语翻译。
3.3 标注过程
- 该研究对17980个词进行了6个标注实验的, 每个实验聚焦于一个语义维度(视觉、运动、社交、情感、时间、空间)。
- 每个标注实验会分成18个session,每个session含1000个词(最后一个session有940个词)
- 标准过程使用问卷星
- 情绪维度标注的时候,使用13-point scale标准标注(-6表示非常负面, 0表示中性, 6表示非常积极)
- 剩下的5维(视觉、运动、社交、时间、空间)使用7-point scale标准标注(1表示非常低, 7表示非常高)
- 每次标注前, 标注者需要阅读标注指南,指南会含有一些语义例子。
- 为了控制标准数据质量, 保证每位标注者与所有标准者的相关性大于0.5,最终拒绝了28个session大概0.87%的数据量。
3.4 扩充词典
标准的17940个中文词的六维度数据,可以认为是标准数据。用机器学习方法,想办法扩充词典。
该团队检验了语义上下文不敏感的词嵌入算法(word2vec/Glove)和 对上下文语义敏感的嵌入算法(GPT2, BERT ERNIE, and MacBERT) ,让这6类嵌入模型分别预测, 确定下表现效果较好的Word2vec和MacBERT算法。
使用Word2vec和MacBERT预测剩下所有的中文词,共扩展出1427992个中文词。
人类在视觉、运动、社交、情感、时间、空间六个维度上是共通的,结合语言嵌入模型可以在不同语言中进行语义空间对齐,该研究根据英文嵌入语言模型,也预测出了1,515,633个词。
四、SSDD
SSDD包含两个数据集:
- 第一个是17,940个常用汉语词语在六个语义维度上的主观评分。
- 第二个是主观评分数据的计算扩展。我们将主观评分与计算模型相结合,然后估算出1,427,992个汉语和1,515,633个英语单词的语义评分。
该研究标准、训练的源代码数据均已开源,https://osf.io/n5vke/
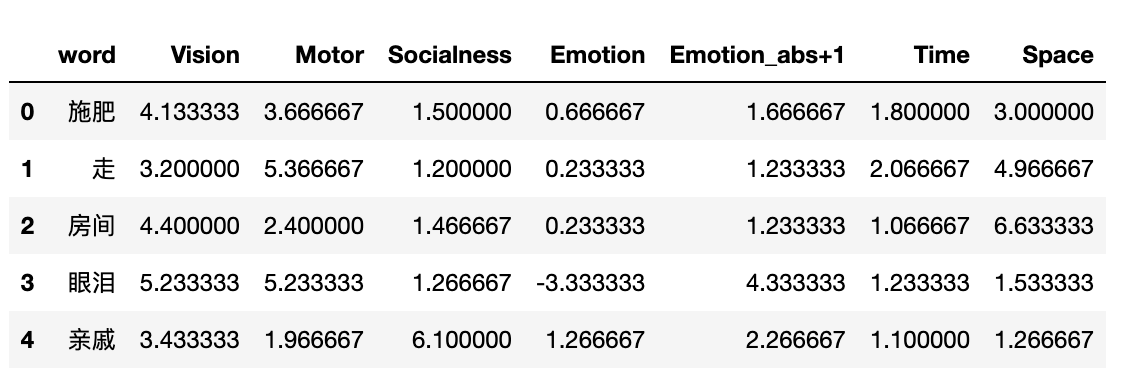
由于数据量太大, 这里只给大家读取并显示17940个标注的6维语义数据, 其实对于经管社科研究, 标注的 17940个词 已经是很大的情感词典了。
import pandas as pd
df = pd.read_csv('Rated_semantic_dimensions.csv')
df.head()
#词汇量
len(df)
Run
17940
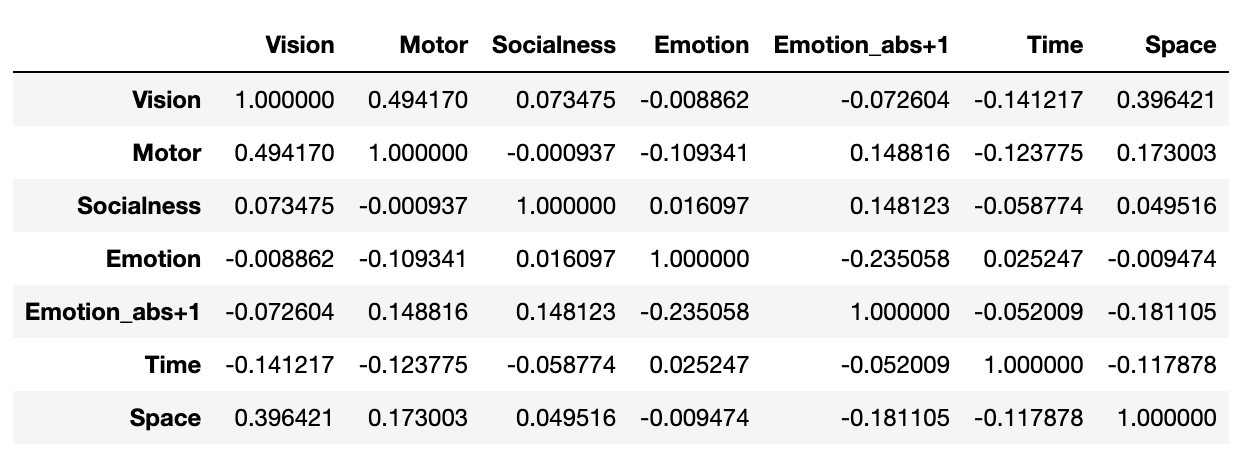
# 计算相关性矩阵
df.corr()
corr_df = df.corr()
mark = lambda cell: 'background-color: %s' % 'red' if cell > 0.4 else ''
color_matrix = corr_df.style.applymap(mark)
color_matrix
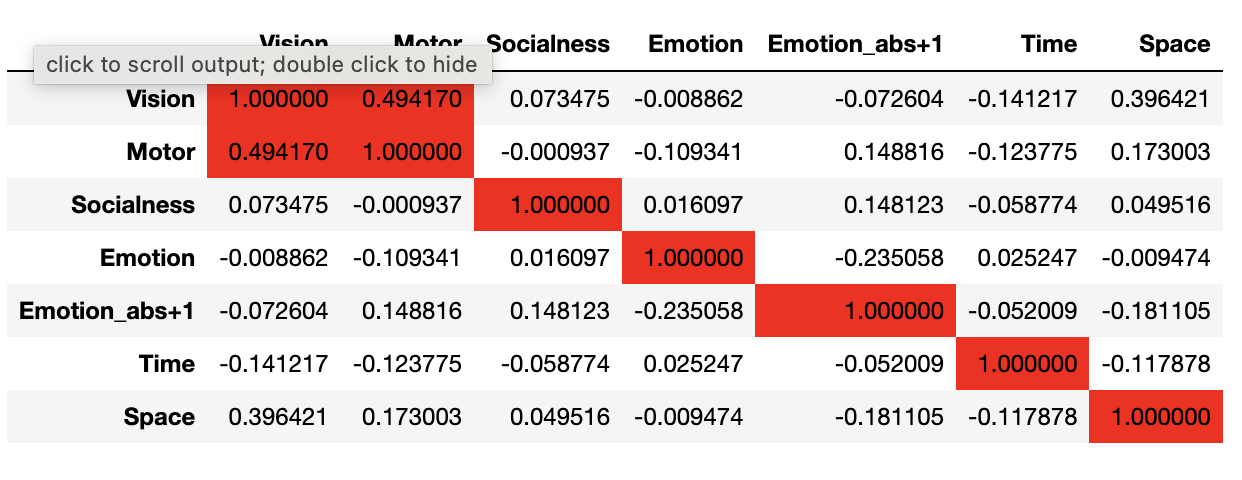
相关性最高的单元格是Motor与Vision, 6个维度相关性均小于0.5 , 六维的选择是很合理。
