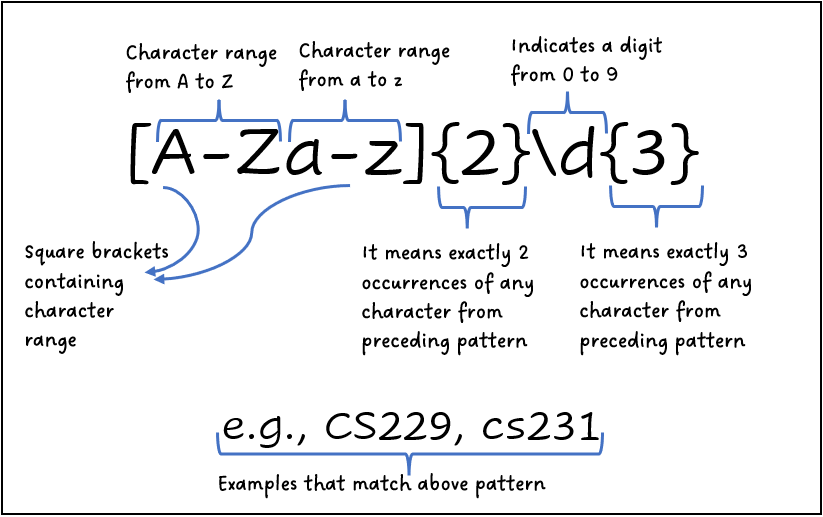
一、统计某类词出现次数
import re
# 定义词语列表
word_list = ['融资', '资金', '筹资', '投资', '投入资金']
# 将词语列表转换为正则表达式模式
pattern = r'|'.join(word_list)
# 定义待匹配的中文文本
text = "今年公司的融资计划受到了资金压力的影响,筹资难度较大。"
# 使用 re.findall() 方法统计出现次数
count = len(re.findall(pattern, text))
# 打印结果
print(count)
3
注意:
使用正则表达式统计某类词的出现次数的效率取决于正则表达式的复杂度和文本的大小。对于较小的文本和简单的正则表达式,使用正则表达式可以提供一个简单的解决方案。但是对于较大的文本和复杂的正则表达式,可能会导致性能问题。
如果需要更快的实现方法,可以考虑使用字符串查找和替换函数,例如Python中的str.count()方法,该方法可以计算一个字符串中出现子字符串的次数。通过遍历所有需要查找的词汇并分别计算其出现次数,可以得出所有词汇的出现次数。这种方法可以避免正则表达式的匹配成本,并且通常比使用正则表达式更快。
# 定义词语列表
words = ['融资', '资金', '筹资', '投资', '投入资金']
# 定义待匹配的中文文本
text = "今年公司的融资计划受到了资金压力的影响,筹资难度较大。"
#words类词 出现次数
count = sum(text.count(word) for word in words)
二、 情感分析
正则表达式也可以用于情感分析。下面是一个使用正则表达式实现情感分析的示例代码:
- 首先定义了一个包含积极情感词和消极情感词的列表。
- 然后,使用正则表达式识别文本中出现的积极情感词和消极情感词,并计算它们出现的次数。
- 最后,通过比较积极词和消极词的出现次数来确定情感分析结果。
import re
# 情感词列表,这里只列出了一些示例
positive_words = ['喜欢', '赞', '棒', '好', '美', '赏心悦目']
negative_words = ['讨厌', '踩', '差', '烂', '丑', '不满意']
# 使用正则表达式识别文本中的情感词
def sentiment_analysis(text):
positive_count = len(re.findall(r'|'.join(positive_words), text))
negative_count = len(re.findall(r'|'.join(negative_words), text))
return positive_count - negative_count
# 测试示例
text1 = '我很喜欢这个餐厅,菜品棒极了!'
text2 = '这部电影很烂,演员演得太差了。'
text3 = '这个景点很美,值得去看看。'
text4 = '这家店的服务太差了,不满意。'
print(sentiment_analysis(text1)) # 输出 2
print(sentiment_analysis(text2)) # 输出 -2
print(sentiment_analysis(text3)) # 输出 1
print(sentiment_analysis(text4)) # 输出 -1
2
-2
1
-2
import re
nouns = ['GDP', 'CPI', 'PPI', '利率', '政策']
pos_adj = ['增长', '提高', '优化']
neg_adj = ['下降', '降低', '恶化']
def sentiment_analysis(text):
score = 0
for noun in nouns:
matches = re.findall(noun, text)
for match in matches:
for adj in pos_adj:
if adj in text:
score += 1
for adj in neg_adj:
if adj in text:
score -= 1
return score
text = '中国GDP增长预期下调,影响市场情绪'
score = sentiment_analysis(text)
print(score)
1
三、融资约束
3.1 识别融资约束句子
姜付秀,王运通,田园,吴恺.多个大股东与企业融资约束——基于文本分析的经验证据[J].管理世界,2017,(12):61-74.
摘要: 本文采用文本分析方法构建了融资约束指标,在此基础上,实证检验了多个大股东对企业融资约束的影响以及相应的作用机理。我们发现,多个大股东的公司有着较低的融资约束水平。该结论在控制内生性情况下依然成立。中介效应模型的检验结果表明,其他大股东通过抑制控股股东的掏空行为降低了企业融资约束。进一步的研究结果表明,在其他大股东具有较强的监督动机和监督能力(大股东数量更多、持股数量之和更大、大股东之间不容易合谋)、及更好的外部环境(信息环境、法律环境)时,公司的融资约束水平更低,这些发现在逻辑上为其他大股东的监督假说提供证据支持的同时,也表明大股东发挥监督作用降低企业融资约束需要一定条件。本文为完善中国情景下的融资约束指标构建、更好度量中国企业融资约束提供了有益参考;同时,为股权结构安排的经济后果提供了新的证据支持。
import re
# 融资不足情况:
regex1 = r"(?:融资|资金|筹资)[^。]{0,6}?(?:难以|不能|无法|不足以)[^。]*"
# 融资成本或压力过大情况:
regex2 = r"(?:融资|资金|筹资)[^。]{0,6}?(?:成本|压力|难度)[^。]{0,4}?(?:升|增|高|大)[^。]*"
# 使用“或”运算符, 将这些正则表达式组合成一个大的正则表达式
pattern = r"(" + regex1 + r")|(" + regex2 + r")"
text = "这是一段融资方面的文本,其中提到了资金不足的情况,还提到了融资成本过高的问题。"
matches = re.findall(pattern, text)
print(matches)
[('', '融资成本过高的问题')]
3.2 出现融资约束句子的数量
pattern可以应用的A股上市公司md&a部分的融资压力句子的识别,其实稍微改动就可以测量md&a中企业关于融资压力句子的出现次数。
import re
def finance_constrain(text):
# 融资不足情况:
regex1 = r"(?:融资|资金|筹资)[^。]{0,6}?(?:难以|不能|无法|不足以)[^。]*"
# 融资成本或压力过大情况:
regex2 = r"(?:融资|资金|筹资)[^。]{0,6}?(?:成本|压力|难度)[^。]{0,4}?(?:升|增|高|大)[^。]*"
# 使用“或”运算符, 将这些正则表达式组合成一个大的正则表达式
pattern = r"(" + regex1 + r")|(" + regex2 + r")"
# 将 pattern 编译成正则表达式对象
regex = re.compile(pattern)
count = 0
for line in f:
match = regex.findall(line)
count += len(match)
return count
