大邓和他的PYTHON
关于
博文
搜索
归档
标签
课程
文献
数据
cntext
RSS
Home
»
Tags
词向量
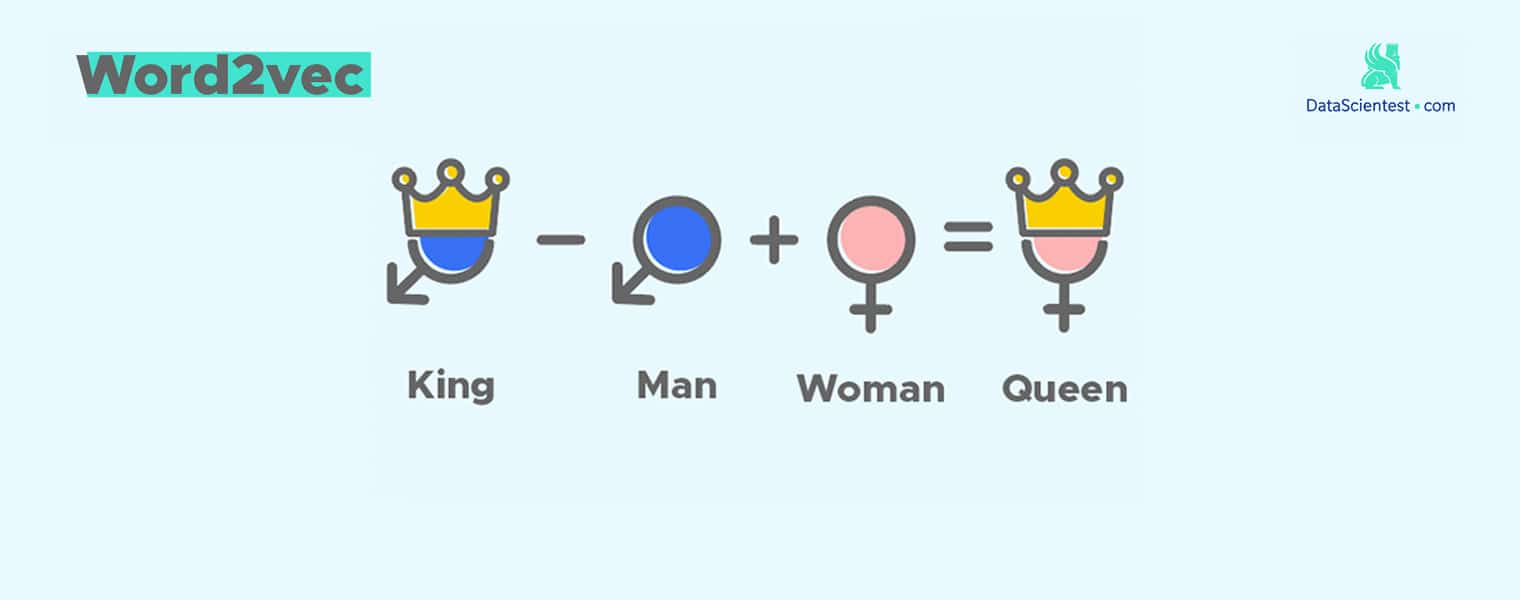
豆瓣影评 | 探索词向量妙处
使用cntext训练、使用词向量。...
数据集 | 使用 1000w 条豆瓣影评训练 Word2Vec
...
以聚类为例 | 使用大语言模型LLM做文本分析
...
OS2022 | 概念空间 | 词嵌入模型如何为组织科学中的测量和理论提供信息
...
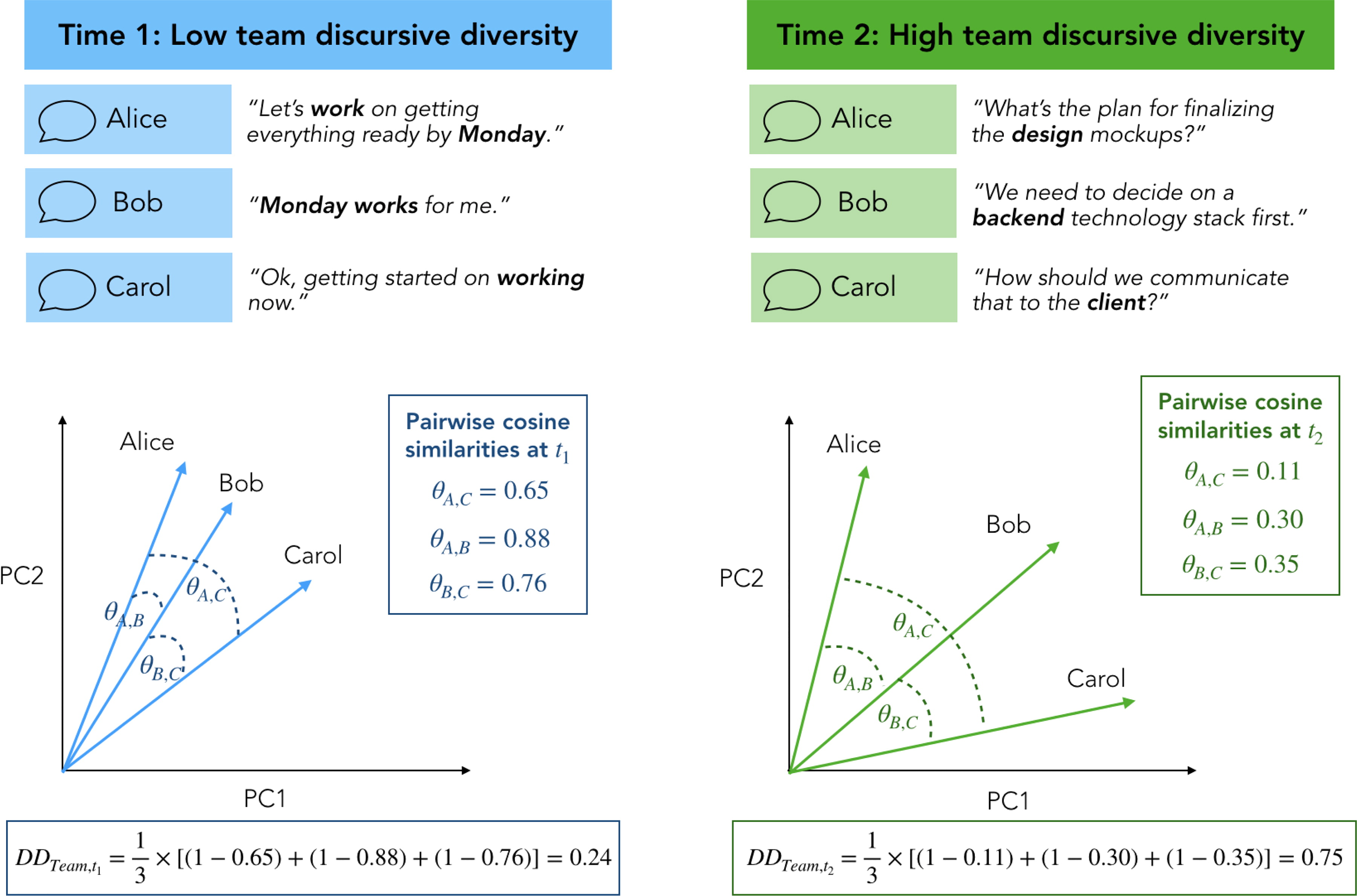
MS2022 | 使用语言差异性测量团队认知差异性
...