数据集| NOS.nl荷兰新闻数据集(2015~2025.2.28)
媒体数据集研究价值大, 您可从中提取丰富的指标,包括但不限于经济政策不确定性指数EPU 、 媒体关注度指数、文本相似度、情感分析。而且可训练词向量,构建新的词典,开发新的指标指数。计算机自然语言处理、经济学、管理学、新闻传播学、公共管理等领域均可使用。...
媒体数据集研究价值大, 您可从中提取丰富的指标,包括但不限于经济政策不确定性指数EPU 、 媒体关注度指数、文本相似度、情感分析。而且可训练词向量,构建新的词典,开发新的指标指数。计算机自然语言处理、经济学、管理学、新闻传播学、公共管理等领域均可使用。...
python爬虫, 黑猫投诉tousu.sina.com.cn...
...
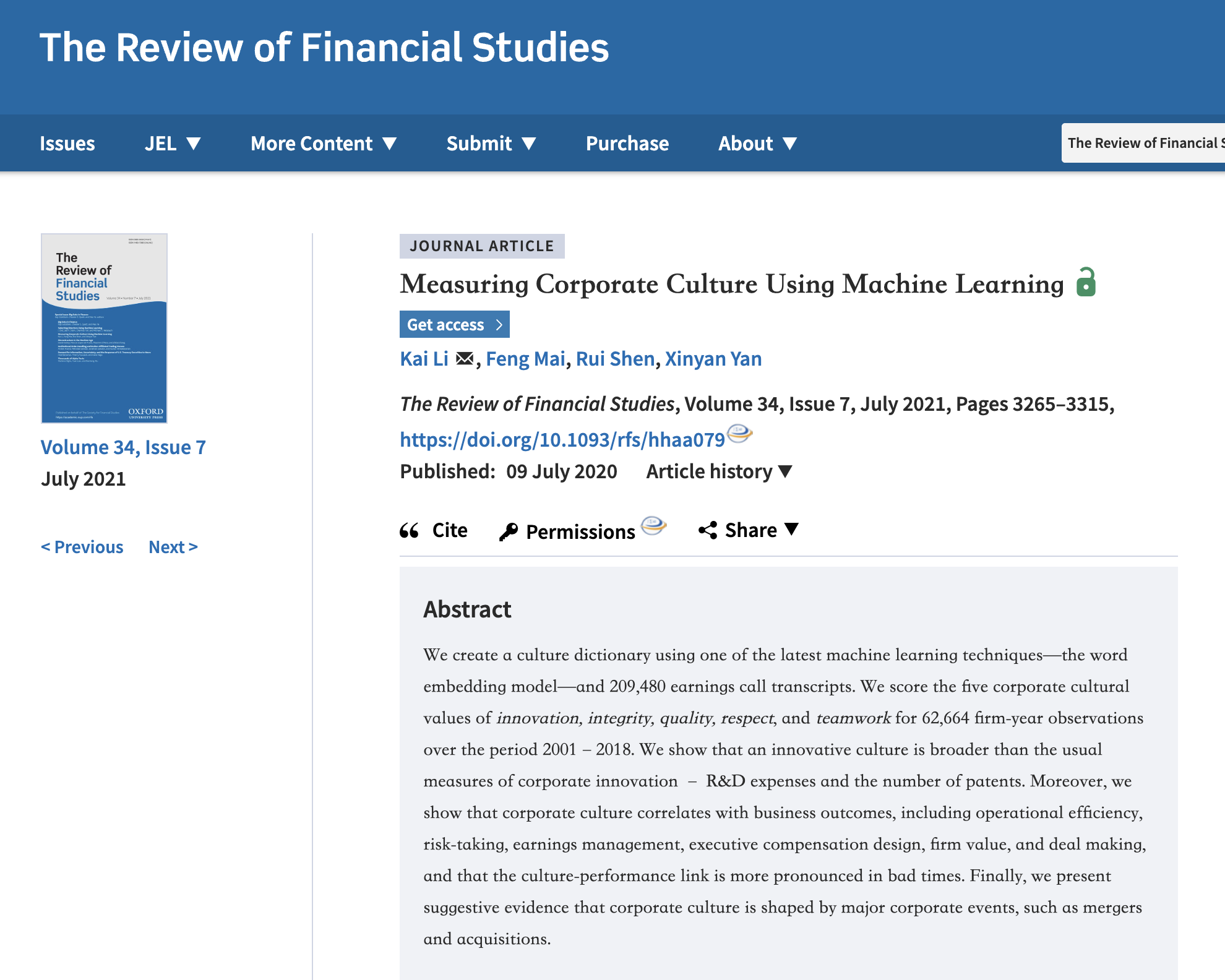
我们使用最新的机器学习技术——**词嵌入模型**——和209,480份盈利电话会议记录创建了一本文化词典。我们对2001年至2018年期间的62,664个公司年度观察数据的**五个公司文化价值——创新、诚信、质量、尊重和团队合作**进行评分。结果表明,创新文化比公司创新的通常衡量标准——研发支出和专利数量——更广泛。此外,我们还表明,企业文化与业务结果相关,包括运营效率、风险承担、盈利管理、高管薪酬设计、企业价值和交易等,并且文化-绩效联系在困难时期更加显著。最后,我们提供了初步证据,表明企业文化受到重大公司事件(如合并和收购)的影响。...

数据科学家花费 80% 以上的时间来准备数据,这其中主要是数据清洗、数据标注。随着 GPT-4 等大型语言模型 (LLM)的兴起,现在我们可以更高效的准备工作。在本文中,我们将探讨如何使用 LLM 进行数据标注,以提高文本注释的准确性、效率和可扩展性,并最终为 ML 项目带来更好的结果。 Data scientists spend over 80% of their time preparing data, including data labeling. With the rise of Large Language Models (LLMs) like GPT-4, we now have the tools to streamline this process significantly.In this article, we’ll explore how to use LLM for data labeling to enhance the accuracy, efficiency, and scalability of text annotations and ultimately drive better outcomes for ML projects....