代码下载
本文B站视频
https://www.bilibili.com/video/BV1AE411r7ph
一、知识准备
- python语法基本知识 https://www.bilibili.com/video/BV1eb411h7sP/
- python网络爬虫 https://www.bilibili.com/video/BV1AE411r7ph/
二、网址规律分析
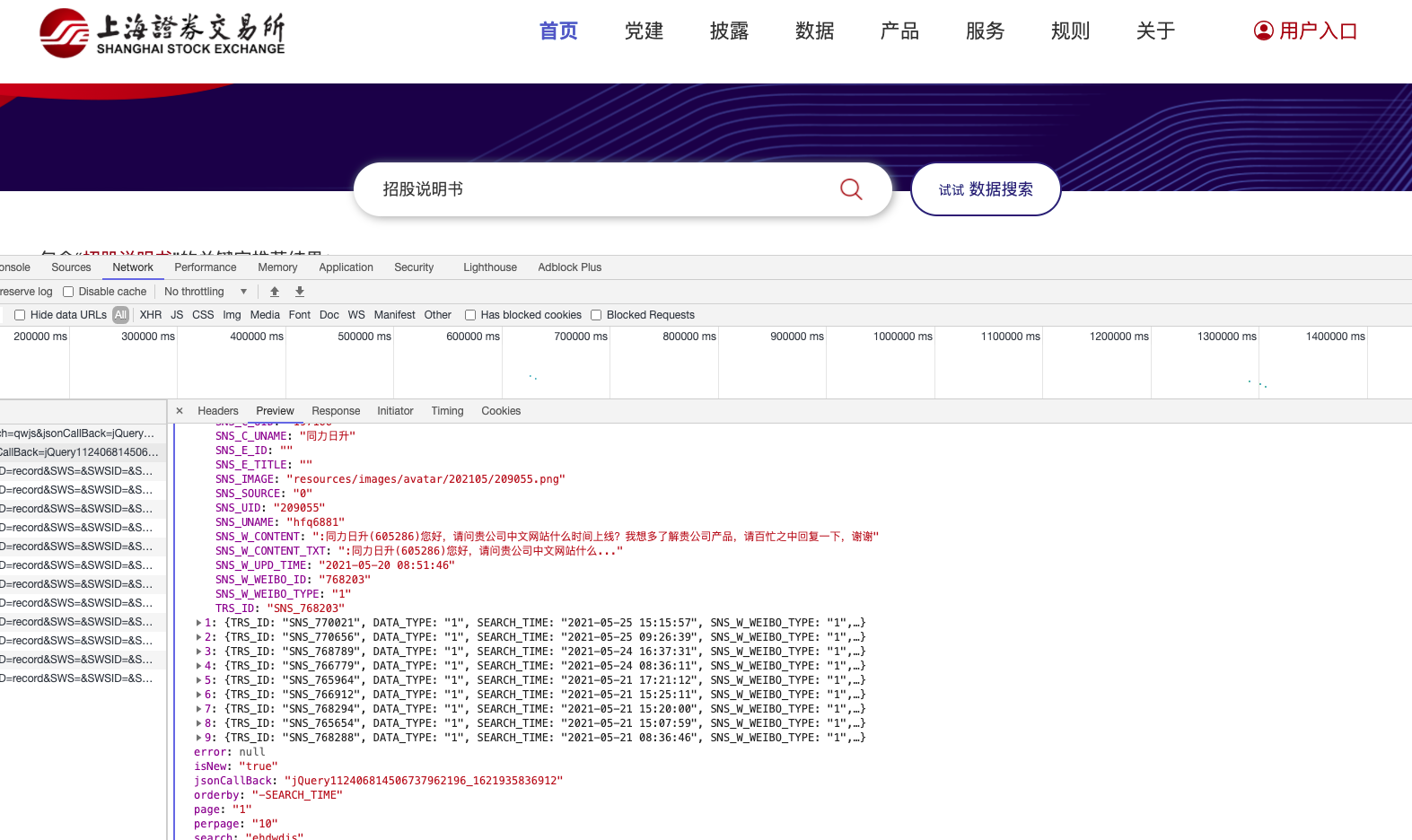
2.1 上交所
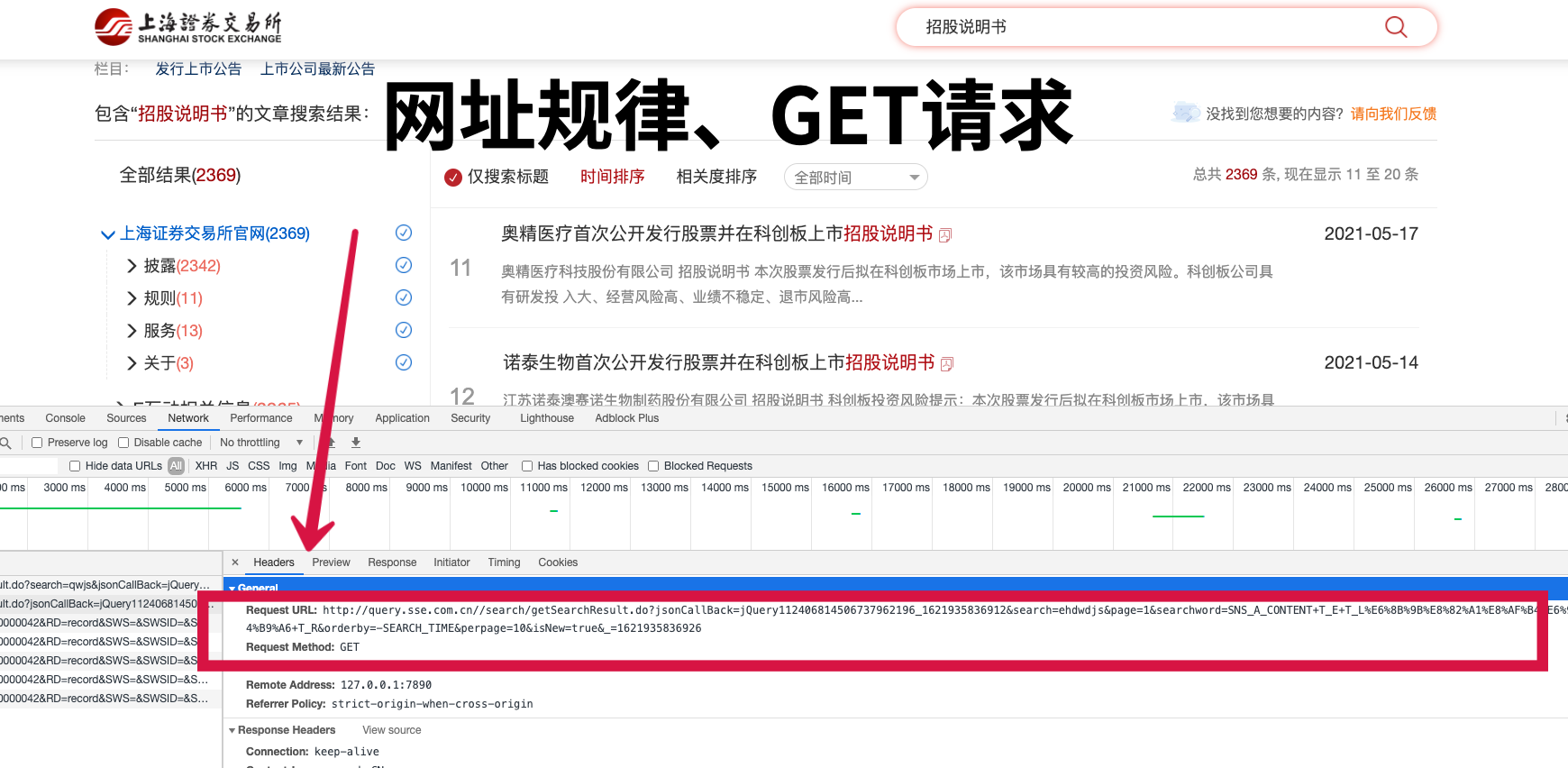
上交所多为GET请求方法,伪码
import requests
url = '上交所网址规律'
headers = '你的浏览器useragent(带referer)'
cookies = '你的cookies'
resp = requests.get(url,
headers=headers,
cookies=cookies)
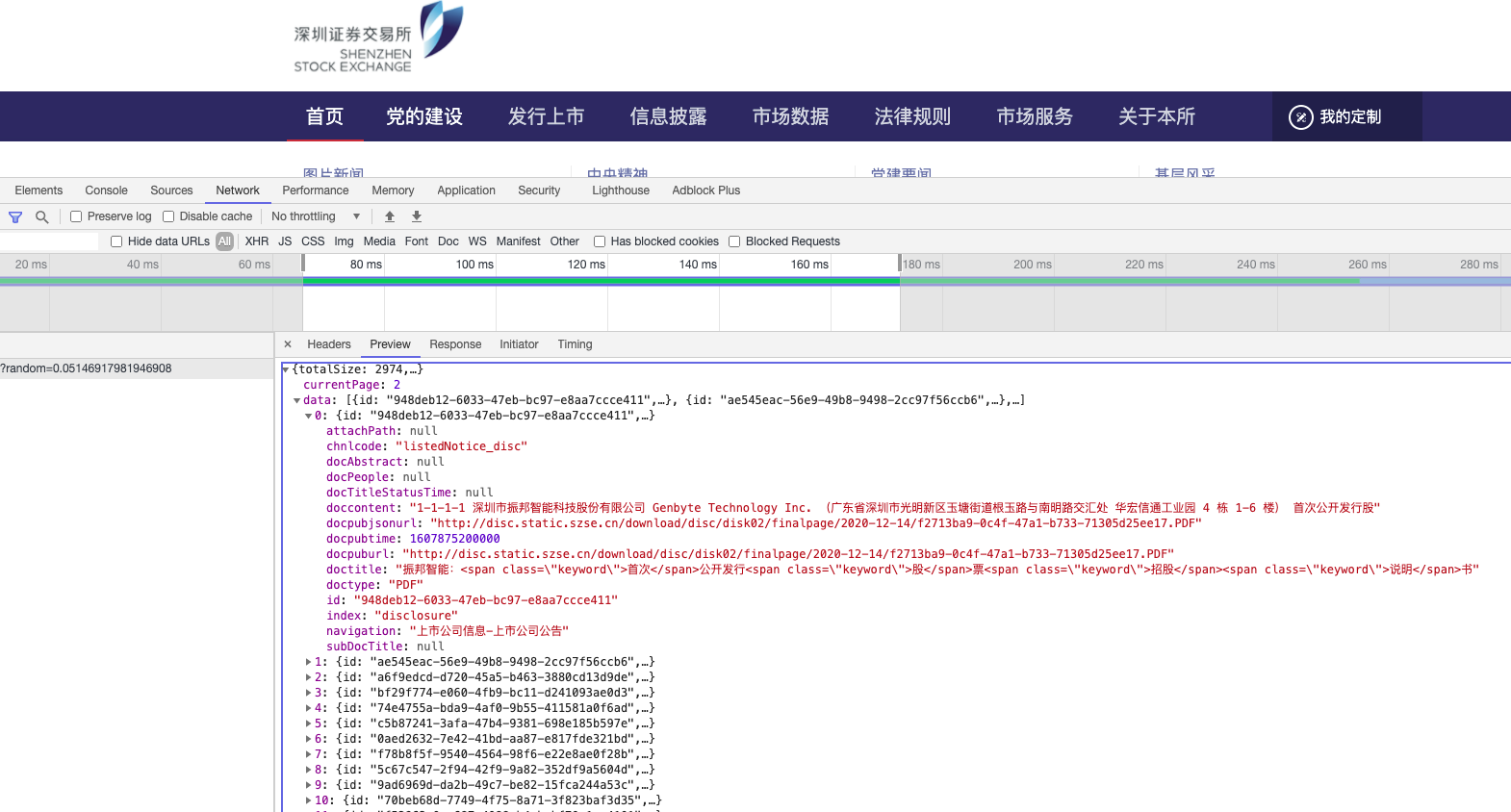
2.2 深交所
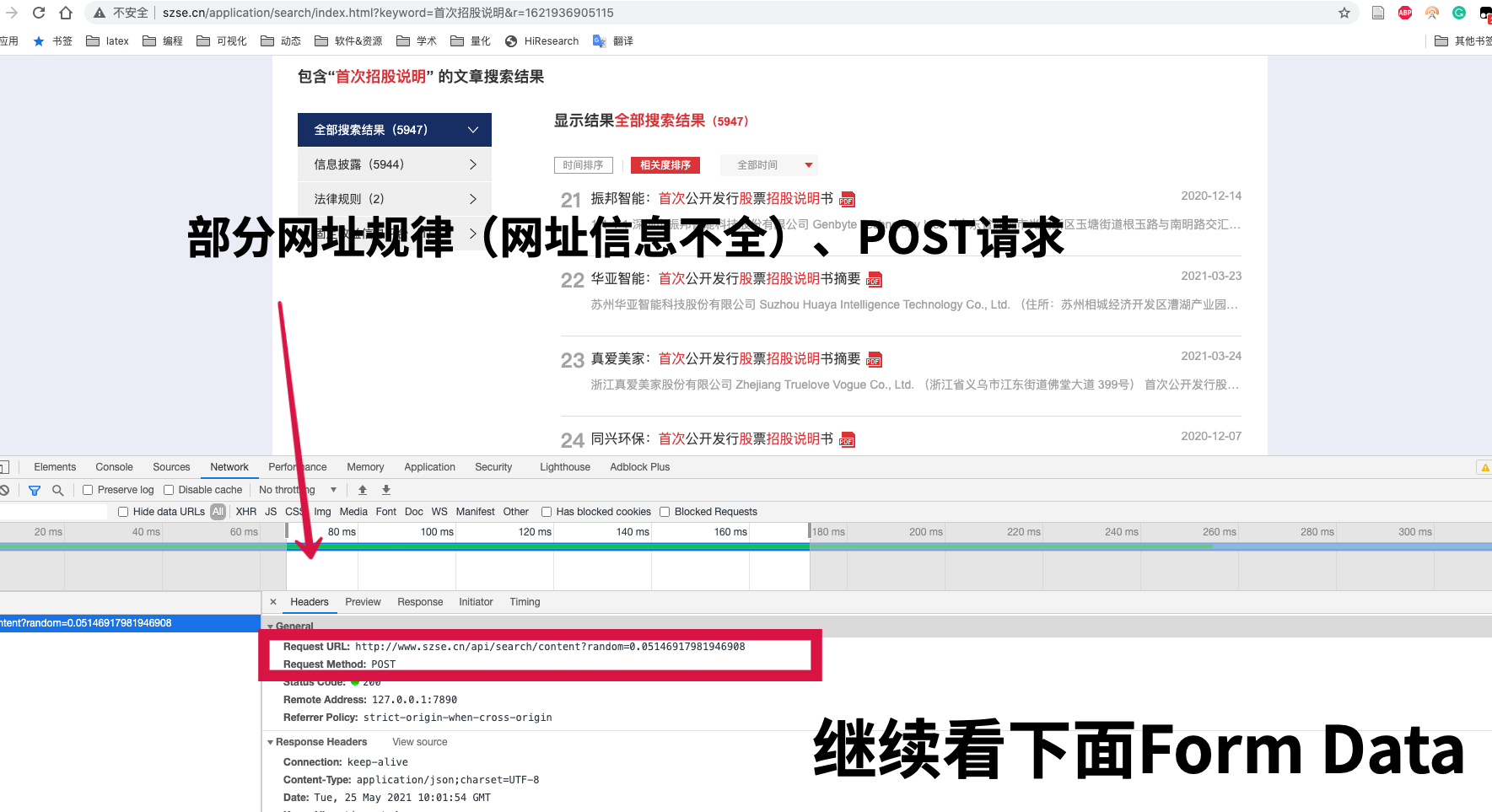
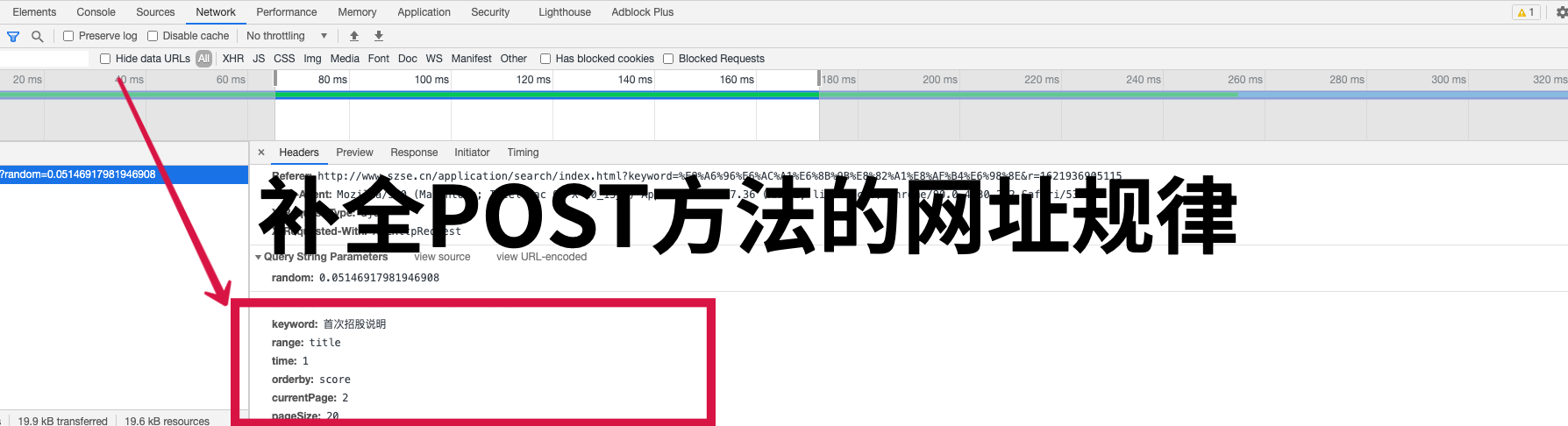
深交所多为POST请求方法,伪码
import requests
url = '深交所网址规律'
headers = '你的浏览器useragent(带referer)'
cookies = '你的cookies'
param = 'form data构造的字典,补全网址规律'
resp = requests.get(url,
headers=headers,
cookies=cookies,
data=param)
三、定位pdf相关数据
访问得到的结果均为json数据,解析定位方法可使用python的字典方法。
四、存储数据
几千个pdf数据量很容易达到1000+M,如果长时间自动下载容易失败。
建议先获取所有公司相关信息,存储到csv中。
后续再单独使用pandas读取,逐一下载pdf。
注意,这里推荐使用csv新的语法
with open('你的csv文件路径', 'w', encoding='utf-8', newline='') as csvf:
#csv文件内的字段名
fieldnames = ['title', 'date', 'link', 'content']
writer = csv.DictWriter(csvf, fieldnames=fieldnames)
writer.writeheader()
#访问
url = '网址'
resp = requests.get(url,....)
#定位
for company in resp.json()['data']:
#解析数据
row = dict()
row['title'] = '采集到的标题'
row['date'] = '采集到的日期'
row['link'] = '采集到的pdf链接'
row['content'] = '采集到的内容'
#写入csv
writer.writerow(row)
五、批量下载pdf
以深交所为例,已经采集到深圳交易所.csv,现在下载只需要执行
## 下载
import requests
import pandas as pd
def download(link, fpath):
"""
下载多媒体及文件
link: 多媒体文件链接(结尾有文件格式名)
fpath: 存储文件的路径(结尾有文件格式名)
"""
resp = requests.get(link)
#获取到二进制数据
binarydata = resp.content
#以二进制形式将数据流存入fname中
with open(fpath, 'wb') as f:
f.write(binarydata)
df = pd.read_csv('深圳交易所.csv')
for title, link in zip(df['title'], df['link']):
fpath = '深圳/{title}.PDF'.format(title=title)
download(link, fpath)
