
采购合同数据集 | 政府采购何以牵动企业创新
中国地方政府采购合同数据是中国政府采购网中国政府购买服务信息平台披露的政府采购合同信息,主要囊括了采购人(甲方)、采购人所属行政区、供应商(乙方)以及合同金额等关键信息。数据自 2008-06-12 ~ 2021-02-03, 共有 648538 条 。如果某个政府采购合同的以上三项信息中包含关键词库内任意一个关键词,那么该合同就被认定为政府创新采购合同。...
中国地方政府采购合同数据是中国政府采购网中国政府购买服务信息平台披露的政府采购合同信息,主要囊括了采购人(甲方)、采购人所属行政区、供应商(乙方)以及合同金额等关键信息。数据自 2008-06-12 ~ 2021-02-03, 共有 648538 条 。如果某个政府采购合同的以上三项信息中包含关键词库内任意一个关键词,那么该合同就被认定为政府创新采购合同。...

Mac VSCode+TinyTex环境, 将 elegantbook.cls 文件放在 TeX 发行版的搜索路径中,这样就可以在任何地方使用 ElegantBook 模板了。执行完以上操作后,就可以在任何 .tex 文件中使用导入命令引用 ElegantBook 模板了。其他的.cls文件,如果也有其他 .cls 文件, 使用频率较高,可以考虑添加到 TeX 的搜索路径中。...
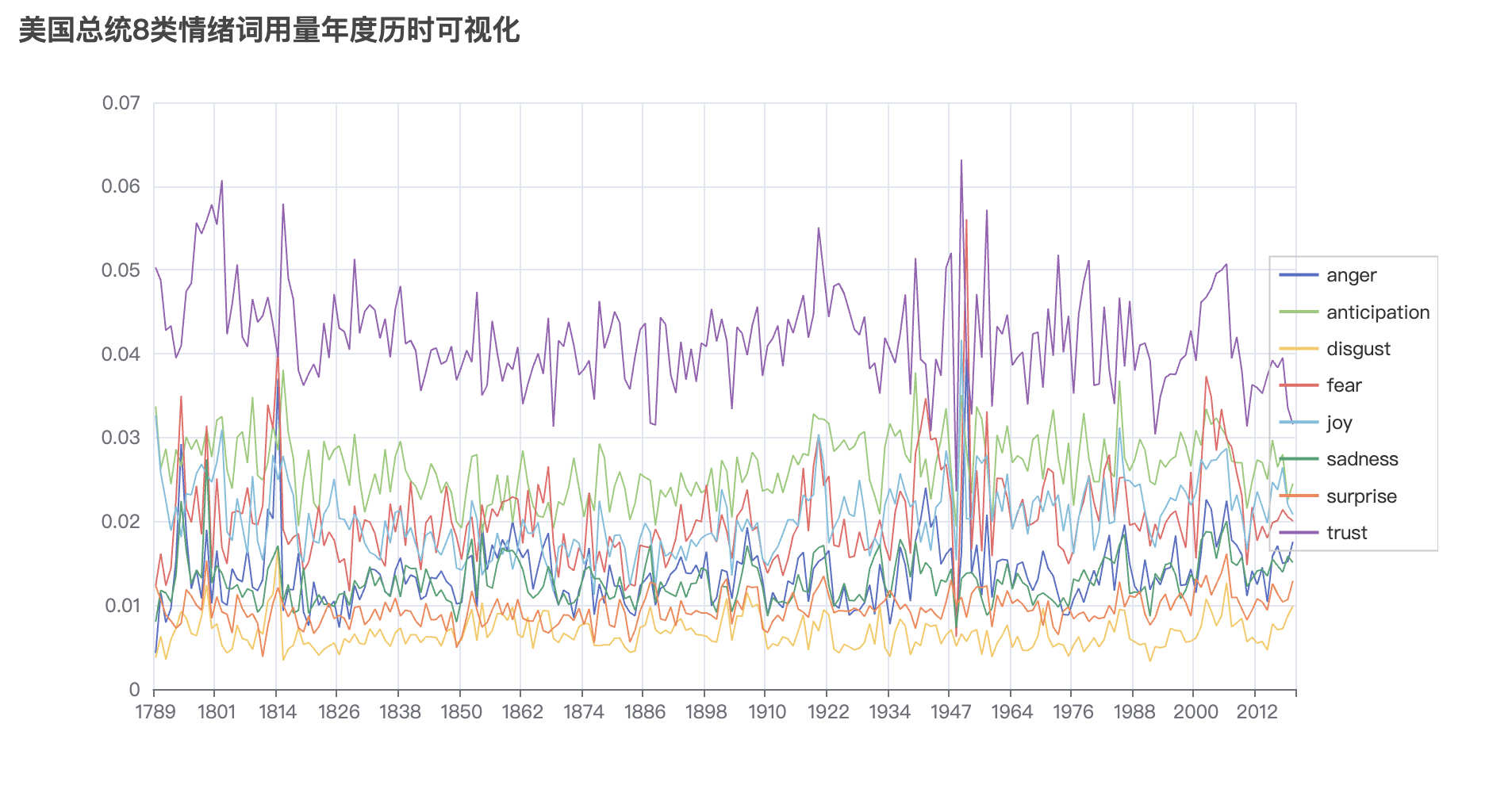
Linguistic positivity in historical texts reflects dynamic environmental and psychological factors历史文本中的语言积极性反映了动态的环境和心理因素...
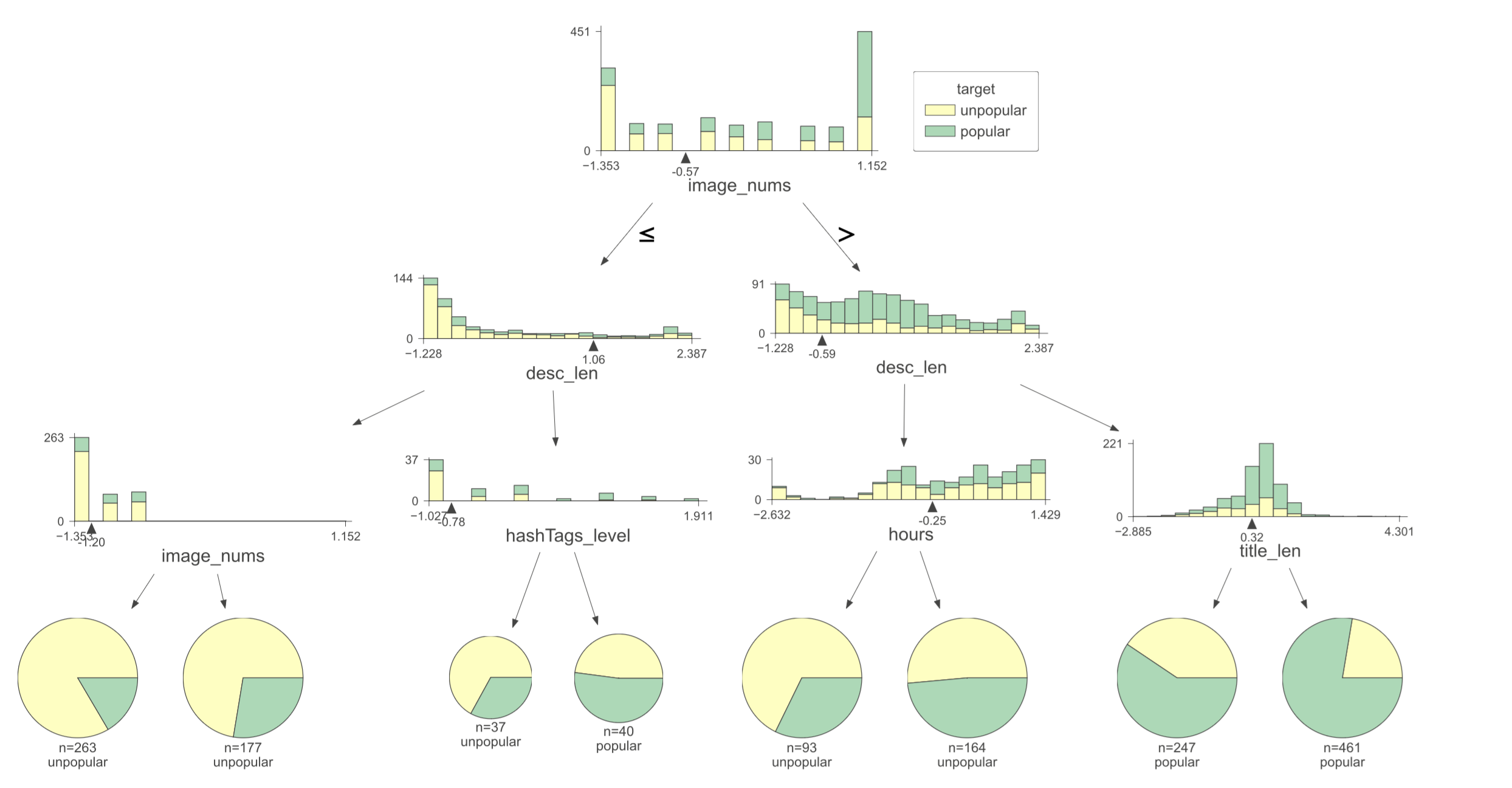
使用决策树分析小红书热门帖的特点,如何成为热帖。...

词嵌入是自然语言处理的一项基础技术。 其核心理念是根据大规模语料中词语和上下文的联系, 使用神经网络等机器学习算法自动提取有限维度的语义特征, 将每个词表示为一个低维稠密的数值向量(词向 量), 以用于后续分析。 心理学研究中, 词向量及其衍生的各种语义联系指标可用于探究人类的语义加工、认知判断、发散思维、社会偏见与刻板印象、社会与文化心理变迁等各类问题。 未来, 基于词嵌入技术的心理 学研究需要区分心理的内隐和外显成分, 深化拓展动态词向量和大型预训练语言模型(如 GPT、BERT)的应用, 并在时间和空间维度建立细粒度词向量数据库, 更多开展基于词嵌入的社会变迁和跨文化研究。 As a fundamental technique in natural language processing (NLP), word embedding quantifies a word as a low-dimensional, dense, and continuous numeric vector (i.e., word vector). Word embeddings can be obtained by using machine learning algorithms such as neural networks to predict the surrounding words given a word or vice versa (Word2Vec and FastText) or by predicting the probability of co-occurrence of multiple words (GloVe) in large-scale text corpora. Theoretically, the dimensions of a word vector reflect the pattern of how the word can be predicted in contexts; however, they also connote substantial semantic information of the word. Therefore, word embeddings can be used to analyze semantic meanings of text. In recent years, word embeddings have been increasingly applied to study human psychology, including human semantic processing, cognitive judgment, divergent thinking, social biases and stereotypes, and sociocultural changes at the societal or population level. Future research using word embeddings should (1) distinguish between implicit and explicit components of social cognition, (2) train fine-grained word vectors in terms of time and region to facilitate cross-temporal and cross-cultural research, and (3) apply contextualized word embeddings and large pre-trained language models such as GPT and BERT. To enhance the application of word embeddings in psychology。