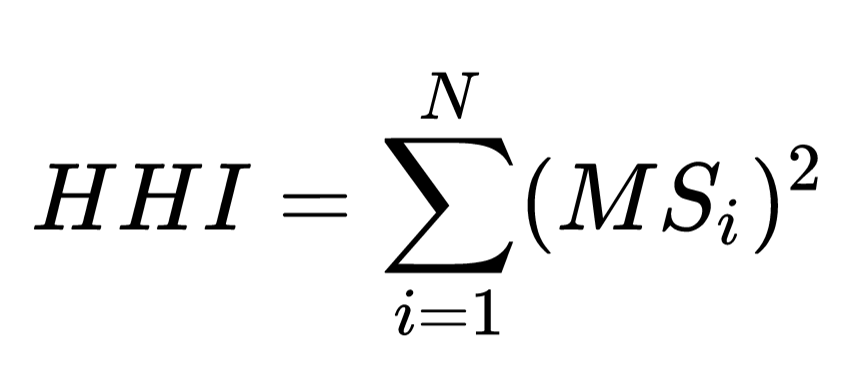
一、相关概念
1.1 赫芬达尔-赫希曼指数
**赫芬达尔-赫希曼指数(Herfindahl-Hirschman Index)**作为一种衡量市场集中度的经济指标,通常用于分析产业或市场中企业份额的分布情况。近年来有学者使用HHI算法测量专利的所涉领域的集中程度,反应专利的知识宽度。
知识宽度是指在特定领域或跨领域中,个人或组织掌握的知识的多样性和广度。
假设某行业有N家公司,每家公司的市场份额为MSi, 则该行业的HHI指数计算公式

1.2 、专利IPC号
IPC号是国际专利分类体系(International Patent Classification, IPC)的缩写,它是一个用于将专利归类到特定技术领域的全球性标准。IPC系统由世界知识产权组织(WIPO)维护,旨在标准化专利文献的分类,以便于检索和分析。

IPC号的结构如下:
1. 部(Section): 用大写字母A到H表示,共分8个部,每个部覆盖特定的技术领域。
2. 大类(Class): 用两位数字表示;每个部下面进一步细分为大类。
3. 小类(Subclass): 用大写字母表示, 大类下面再细分为小类,。
4. 大组(Main Group) 和 小组(Sub-Group):小类下面进一步细分,用斜杠(/)分隔的数字表示。
- 大组:用两位数字表示。
- 小组:大组后面跟着的两位数字。
1.3 专利与HHI
在创新领域,使用hhi计算专利质量,最小粒度是大组(Group)。举例说明
|专利序号| IPC号 |
| 1 | A01B01/00;A01B01/01 |
| 2 | A01B01/00;A01C01/01 |
如果用HHI计算
#1种知识,份额1/1
patent1_HHI = (1/1)*(1/1) = 1
#2种知识,份额各1/2
patent2_HHI = (1/2)*(1/2) + (1/2)*(1/2) = 1/2
从知识集中程度(HHI),专利1 知识更聚焦。
衡量一个人的知识有广度和深度两种不同的角度, 在创新创业领域, 习惯用专利的(1-hhi)来表示专利质量(广度)。
二、实验: 衡量专利质量
准备了三个专利,
"A01B01/00"
"A01B01/00;B01D01/01"
"A01B01/00;B01D01/01;C01B01/01"
"A01B01/00;B01D01/01;C01B01/01;D01B01/01"
"A01B01/00;B01D01/01;C01B01/01;D01B01/01;F01B01/01"
从上到下,知识宽度越来越大, 集中程度(HHI)越来越小。
import numpy as np
def ipc_hhi(ipc_text):
#ipc_text字符串,形如"A01B01/00;B01D01/01;F01B01/01"
ipc_list = [group.split('/')[0] for group in ipc_text.split(';')]
ipc_group_counts = list(Counter(ipc_list).values())
ipc_props = np.array(ipc_group_counts)/sum(ipc_group_counts)
hhi_value = sum(ipc_prop**2 for ipc_prop in ipc_props)
return hhi_value
print(ipc_hhi("A01B01/00"))
print(ipc_hhi("A01B01/00;B01D01/01"))
print(ipc_hhi("A01B01/00;B01D01/01;C01B01/01"))
print(ipc_hhi("A01B01/00;B01D01/01;C01B01/01;D01B01/01"))
print(ipc_hhi("A01B01/00;B01D01/01;C01B01/01;D01B01/01;F01B01/01"))
Run
1.0
0.5
0.3333333333333333
0.25
0.20000000000000004
print(1-ipc_hhi("A01B01/00"))
print(1-ipc_hhi("A01B01/00;B01D01/01"))
print(1-ipc_hhi("A01B01/00;B01D01/01;C01B01/01"))
print(1-ipc_hhi("A01B01/00;B01D01/01;C01B01/01;D01B01/01"))
print(1-ipc_hhi("A01B01/00;B01D01/01;C01B01/01;D01B01/01;F01B01/01"))
Run
0.0
0.5
0.6666666666666667
0.75
0.7999999999999999
知识宽度(1-hhi)越来越大。
三、语言的HHI
3.1 联想
本节语言是使用的大模型,未查阅文献。通义千问,提问[赫芬达尔-赫希曼指数(Herfindahl-Hirschman Index)是否可以测量一个人用语(表达)的特质]
前人类比市场集中程度,用于测量专利质量(知识宽度)。 那放在文本语言中,我们是否可能利用HHI来量化某个语料库中不同词汇的使用频率分布,以此来分析个人、群体或时代的语言风格、词汇丰富度、或是语言标准化与变化的趋势。
- 如果词汇分布非常均匀,表明语言使用中的词汇多样性高,HHI值就会较低;
- 反之,如果少数词汇占据了大部分文本空间,表明词汇使用集中,HHI值则较高。
结合其他语言学指标一起使用,比如TTR(Type-Token Ratio,类型-标记比率)、Shannon entropy(香农熵)等,共同评估语言表达的复杂度和多样性。不过,这类研究的文献相对较少,因为语言学领域有自己一套成熟且专业的分析工具和方法,HHI更多地被视为跨学科应用的一个创新尝试。
3.2 词语的HHI
from collections import Counter
import numpy as np
import jieba
def word_hhi(text):
"""计算文本词汇使用的HHI"""
word_counts = list(Counter(jieba.lcut(text)).values())
word_props = np.array(word_counts)/sum(word_counts)
hhi_value = sum(w_prop**2 for w_prop in word_props)
return hhi_value
personA = '这场音乐会太嗨了'
personB = '这场音乐会说出来令你不敢相信,主办方策划有方,群众激情满满,我印象深刻,体验感拉满'
print('A-hhi', word_hhi(personA))
print('B-hhi', word_hhi(personB))
print('A词汇多样性', 1-word_hhi(personA))
print('B词汇多样性', 1-word_hhi(personB))
Run
A-hhi 0.20000000000000004
B-hhi 0.07024793388429751
A词汇多样性 0.7999999999999999
B词汇多样性 0.9297520661157025
#pip3 install cntext --upgrade
import cntext as ct
personA = '这场音乐会太嗨了'
personB = '这场音乐会说出来令你不敢相信,主办方策划有方,群众激情满满,我印象深刻,体验感拉满'
print('A-hhi', ct.word_hhi(personA))
print('B-hhi', ct.word_hhi(personB))
print('A词汇多样性', 1 - ct.word_hhi(personA))
print('B词汇多样性', 1 - ct.word_hhi(personB))
Run
A-hhi 0.20000000000000004
B-hhi 0.07024793388429751
A词汇多样性 0.7999999999999999
B词汇多样性 0.9297520661157025
