
一、数据概况
数据集名称: 国家社会科学基金立项名单
格式: xlsx
年份:2010~2023
科研用途;需要的请加微信 372335839, 备注「姓名-学校-专业」
二、读取数据
import pandas as pd
df = pd.read_excel('2010-2023年国家社会科学基金立项名单.xlsx')
df['所在学科'] = df['所在学科'].fillna('')
df.head()
df['所在学科'].unique()
Run
array(['马列·科社', '管理学', '政治学', '外国文学', '人口学', '图书馆、情报与文献学', '新闻学与传播学',
'中国文学', '世界历史', '语言学', '民族问题研究', '哲学', '理论经济', '体育学', '国际问题研究',
'中国历史', '党史·党建', '法学', '应用经济', '社会学', '统计学', '宗教学', '', '教育学',
'考古学', '图书馆、情报与档案学', '其他', '图书情报', '军事学', '艺术学', '党史•党建', '马列•科社',
'新闻传播学', '中国历史、', '民族学', '国际问题', '法学、医学、公共卫生学', '灾害学、社会学、管理学、系统科学',
'法学、医学、社会学', '应用经济学 法学', '宏观经济、计量经济、管理学等', '智能技术、电子商务、人工智能、信',
'管理学、经济学、地理学', '艺术学、人类学、计算机科学', '文化人类学、非遗保护、考古学、影',
'文学艺术、文化人类学、计算机科学', '计算机科学与技术、社会学、公共管', '电气工程;产业经济学;管理学;热',
'城市规划学、计算机学、信息网络学', '心理学、认知和行为科学、脑科学、', '产业经济学、管理学、信息技术及应',
'法学、社会学、信息科学、计算机科', '管理科学与工程、控制科学与工程、', '智能技术、产业经济、经济学、管理',
'语言学、计算机科学、生态学、社会', '理论经济学、应用经济学、法学、公', '语言学、人类学、信息科学',
'宏观经济、计量经济、管理学、统计', '管理学、 经济学 、环境科学、', '语言学、计算机科学、统计学等',
'城乡规划学、管理学、地理学、经济', '语言文学、心理学、教育学', '人类学、社会心理学、认知神经科学',
'应用经济、管理学、资源环境科学、', '电气工程、管理学、产业经济、能源', '产业经济、生态学、系统科学、管理', '马列科社',
'党史党建', '综合研究', '民族问题', '图书·情报与文献', '新闻学', '跨学科', '民族问题 研究',
'新闻与传播学', '新闻学与 传播学', '马列.科社', '系列丛书', '图书馆·情报与文献学', '重点项目',
'一般项目', '学术期刊', '理论经济学', '应用经济学', '国际问题研\n究', '新闻学与传\n播学',
'图书馆、情\n报与文献学'], dtype=object)
三、简单分析
3.1 可视化准备
import matplotlib.pyplot as plt
import matplotlib
import matplotlib_inline
matplotlib_inline.backend_inline.set_matplotlib_formats('png', 'svg')
import scienceplots
import platform
plt.style.use(['science', 'no-latex', 'cjk-sc-font'])
system = platform.system() # 获取操作系统类型
if system == 'Windows':
font = {'family': 'SimHei'}
elif system == 'Darwin':
font = {'family': 'Arial Unicode MS'}
else:
font = {'family': 'sans-serif'}
matplotlib.rc('font', **font) # 设置全局字体
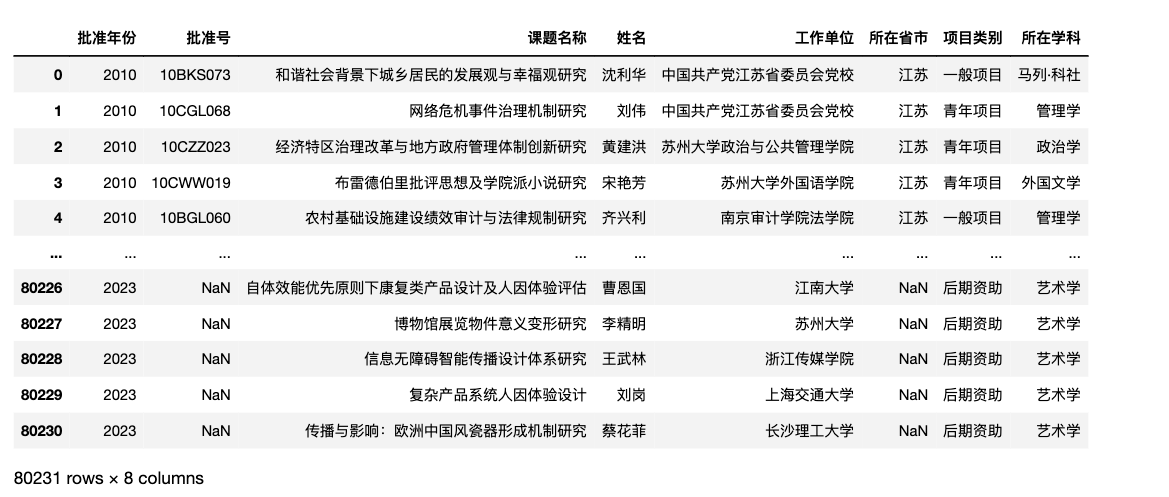
3.2 立项数量
df['批准年份'].value_counts(ascending=True).plot(kind='bar', figsize=(8, 4))
plt.xticks(rotation=0)
plt.ylabel('立项数量', rotation=0)
plt.title('国社科立项数量(2010-2023)')
3.3 经管学科
management_economic_displines = [d for d in df['所在学科'].unique() if ('经济' in d) or ('管理' in d)]
management_economic_displines
Run
['管理学',
'理论经济',
'应用经济',
'灾害学、社会学、管理学、系统科学',
'应用经济学 法学',
'宏观经济、计量经济、管理学等',
'管理学、经济学、地理学',
'电气工程;产业经济学;管理学;热',
'产业经济学、管理学、信息技术及应',
'管理科学与工程、控制科学与工程、',
'智能技术、产业经济、经济学、管理',
'理论经济学、应用经济学、法学、公',
'宏观经济、计量经济、管理学、统计',
'管理学、 经济学 、环境科学、',
'城乡规划学、管理学、地理学、经济',
'应用经济、管理学、资源环境科学、',
'电气工程、管理学、产业经济、能源',
'产业经济、生态学、系统科学、管理',
'理论经济学',
'应用经济学']
3.4 经管立项
eco_man_df = df[df['所在学科'].isin(management_economic_displines)]
eco_man_df
经管类国社科立项数量占比
df['所在学科'].isin(management_economic_displines).sum() / len(df)
Run
0.18713464870187335
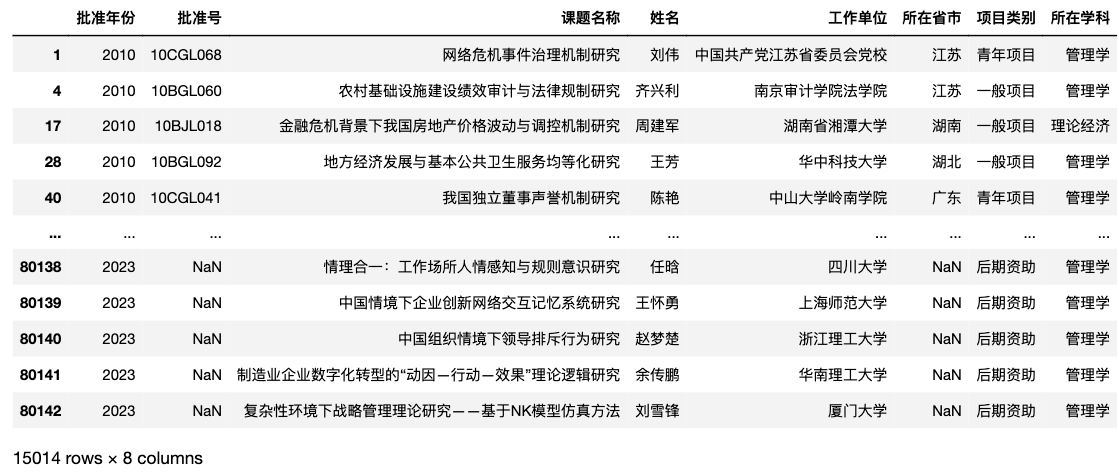
3.5 经管立项数量
eco_man_with_ds_df = eco_man_df[eco_man_df['课题名称'].fillna('').str.contains('大数据|数据挖掘|机器学习|人工智能|AIGC')]
eco_man_with_ds_df['批准年份'].value_counts(ascending=True).plot(kind='bar', figsize=(8, 4))
plt.xticks(rotation=0)
plt.ylabel('立项数量', rotation=0)
plt.title('国社科基金中结合数据科学的经济、管理类立项数量(2010-2023)')
3.6 经管立项占比
按年度查看, 国社科中经管类立项占比
year_ratios = []
for year, year_df in df.groupby('批准年份'):
ratio = year_df['所在学科'].isin(management_economic_displines).sum() / len(year_df)
year_ratios.append((year, ratio))
year_ratio_df = pd.DataFrame(year_ratios)
year_ratio_df.columns = ['year', 'ratio']
year_ratio_df.set_index('year', inplace=True)
year_ratio_df.plot(kind='bar', figsize=(8, 4))
plt.ylabel('立项占比', rotation=0)
plt.title('国社科基金中经济、管理类立项占比(2010-2023)')
