cpca库, 可提取简体中文字符串中 **省、市和区(县)**区划信息,且能够进行映射,检验和简单绘图。
一、安装
pip3 install jinja2==3.0.1
pip3 install pyecharts==0.5.11
pip3 install echarts-countries-pypkg
pip3 install pyecharts-snapshot
pip3 install cpca
二、快速上手
import cpca
location_str = ["徐汇区虹漕路461号58号楼5楼",
"泉州市洛江区万安塘西工业区",
"北京朝阳区北苑华贸城"]
df = cpca.transform(location_str)
df
| | 省 | 市 | 区 | 地址 | adcode |
|---:|:-------|:------|:-------|:--------------------|---------:|
| 0 | 上海市 | 市辖区 | 徐汇区 | 虹漕路461号58号楼5楼 | 310104 |
| 1 | 福建省 | 泉州市 | 洛江区 | 万安塘西工业区 | 350504 |
| 2 | 北京市 | 市辖区 | 朝阳区 | 北苑华贸城 | 110105 |
import cpca
cpca.transform(["朝阳区汉庭酒店大山子店"])
Run
| | 省 | 市 | 区 | 地址 | adcode |
|---:|:-------|:-------|:-------|:-----------------|---------:|
| 0 | 吉林省 | 长春市 | 朝阳区 | 汉庭酒店大山子店 | 220104 |
中国的区级行政单位非常的多,经常有重名的情况,比如 “北京市朝阳区”和“吉林省长春市朝阳区”,当有上级地址信息的时候,cpca 能够根据上级地址推断出这是哪个区。但是如果没有上级地址信息,只有一个区名的时候, cpca 就没法推断了,只能随便选一个, 通过 umap 参数你可以指定这种情况下该选择哪一个:
cpca.transform(["朝阳区汉庭酒店大山子店"], umap={"朝阳区":"110105"})
Run
| | 省 | 市 | 区 | 地址 | adcode |
|---:|:-------|:-------|:-------|:-----------------|---------:|
| 0 | 北京市 | 市辖区 | 朝阳区 | 汉庭酒店大山子店 | 110105 |
三、案例
cpca运行速度很快,这里提供了案例数据 addr.csv , 有 18367 条地址记录。
https://github.com/DQinYuan/chinese_province_city_area_mapper/blob/master/cpca/resources/adcodes.csv
3.1 读取数据
import pandas as pd
raw_addr_df = pd.read_csv('addr.csv')
raw_addr_df

3.3 地址操作
生成标准地址信息
import cpca
addr_df = cpca.transform(raw_addr_df['原始地址'])
addr_df

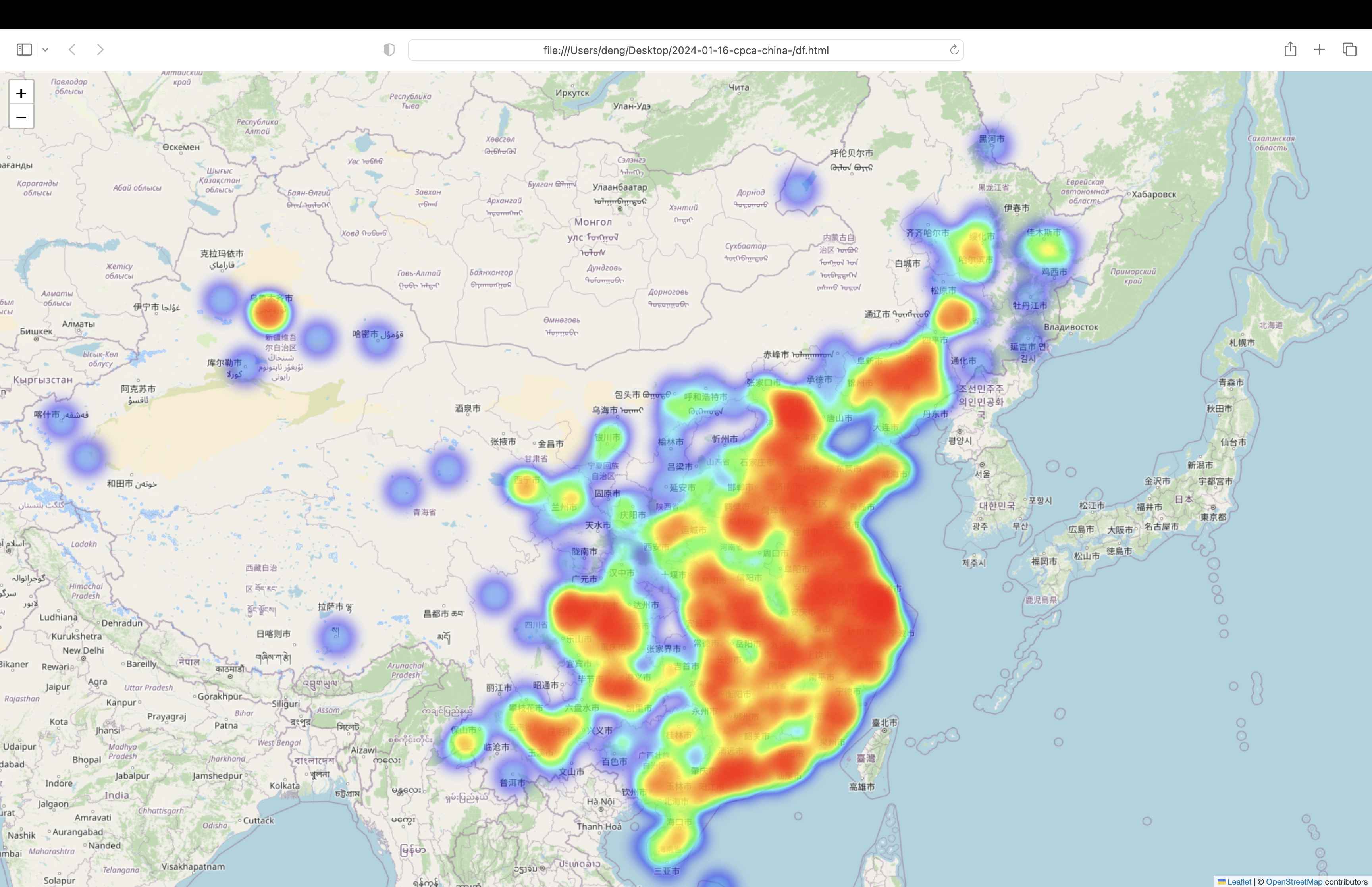
3.3 绘制热力图
使用 folium库绘热力图(需要注意,打开 html时,需要有梯子的网络环境)
from cpca import drawer
#df为上一段代码输出的df
drawer.draw_locations(addr_df['adcode'], "df.html")
这一段代码运行结束后会在运行代码的当前目录下生成一个df.html文件,用浏览器打开即可看到 绘制好的地图(如果某条数据’省',‘市’或’区’字段有缺,则会忽略该条数据不进行绘制),速度会比较慢,需要耐心等待,绘制的图像如下:

