相关代码
一、数据集
1.1 数据简介
国级(guo wu yuan)工作报告1954-2024, 记录数71
省级zf工作报告2002-2024, 记录数744
市级zf工作报告2003-2024, 记录数6204
1.2 说明
本文内容仅为科研分享, 不代表本人的政治立场。如有问题, 加微信 372335839, 备注「姓名-学校-专业-政府工作报告」。
1.3 文件树目录
|- 代码.ipynb
|- GovReportData
|-nation
|-1954.txt
|-1955.txt
|-...
|-2023.txt
|-2024.txt
|-prov
|-安徽省2001.txt
|-...
|-安徽省2024.txt
|-...
|-浙江省2024.txt
|-city
|-安康市2003.txt
|-...
|-安庆市2003.txt
|-...
|-安庆市2024.txt
二、查看数据
2.1 国级报告
import pandas as pd
ndf = pd.read_csv('GovReportData/nation.csv')
ndf

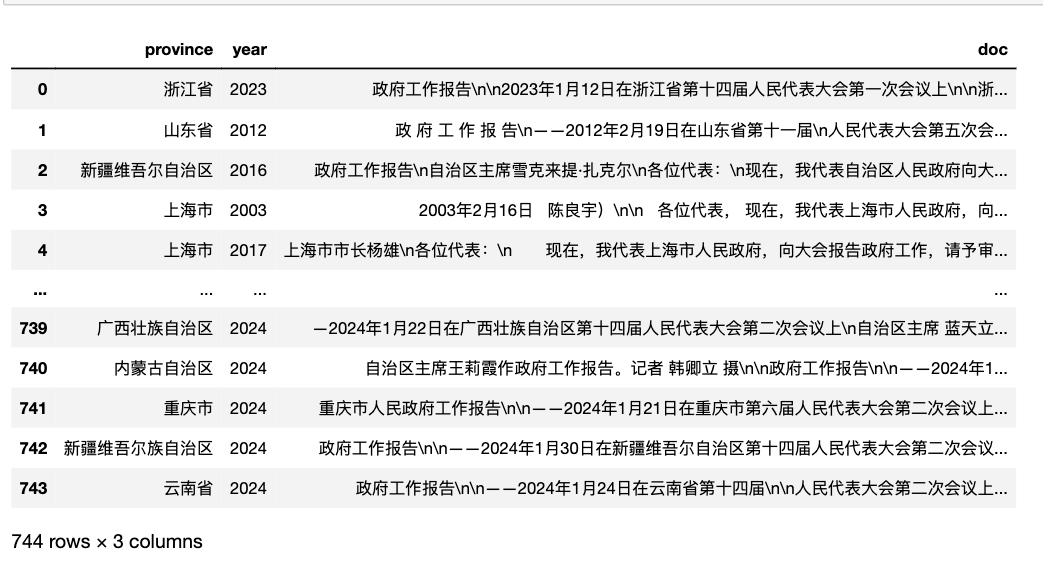
2.2 省级报告
pdf = pd.read_csv('GovReportData/province.csv')
pdf
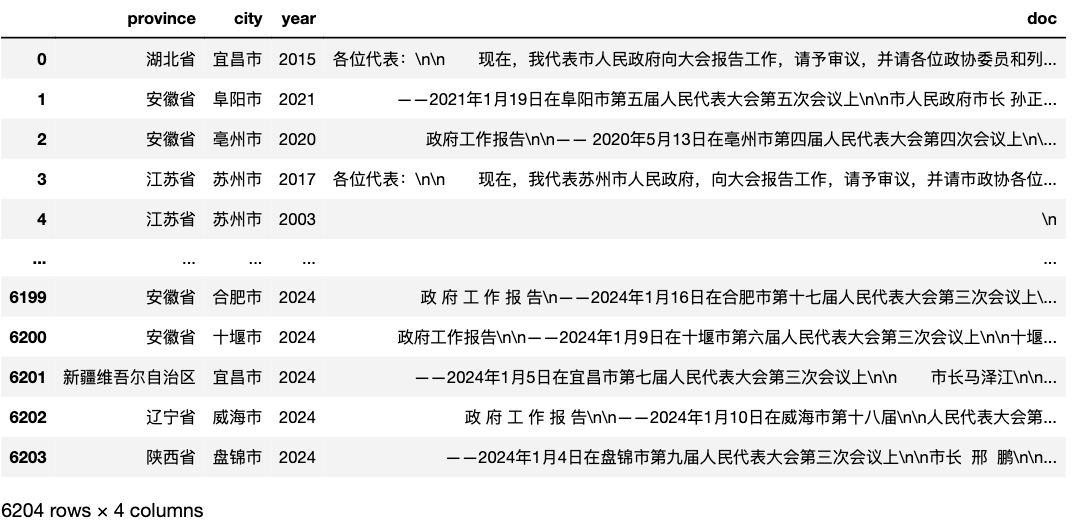
2.3 市级报告
cdf = pd.read_csv('GovReportData/city.csv')
cdf
三、 实验-文本分析
3.1 国-词频
计算总词语数、某类词出现的次数,计算各政府提及【环保】的频率
import jieba
ndf['word_num'] = ndf['doc'].fillna('').apply(lambda text: len(jieba.lcut(text)))
ndf['env_num'] = ndf['doc'].fillna('').str.count('环保|环境|污染|青山|绿水')
ndf['env_ratio'] = ndf['env_num']/ndf['word_num']
ndf

3.2 可视化
import matplotlib.pyplot as plt
import matplotlib
import matplotlib_inline
matplotlib_inline.backend_inline.set_matplotlib_formats('png', 'svg')
import scienceplots
import platform
import pandas as pd
import numpy as np
import jieba
plt.style.use(['science', 'no-latex', 'cjk-sc-font'])
system = platform.system() # 获取操作系统类型
if system == 'Windows':
font = {'family': 'SimHei'}
elif system == 'Darwin':
font = {'family': 'Arial Unicode MS'}
else:
font = {'family': 'sans-serif'}
matplotlib.rc('font', **font) # 设置全局字体
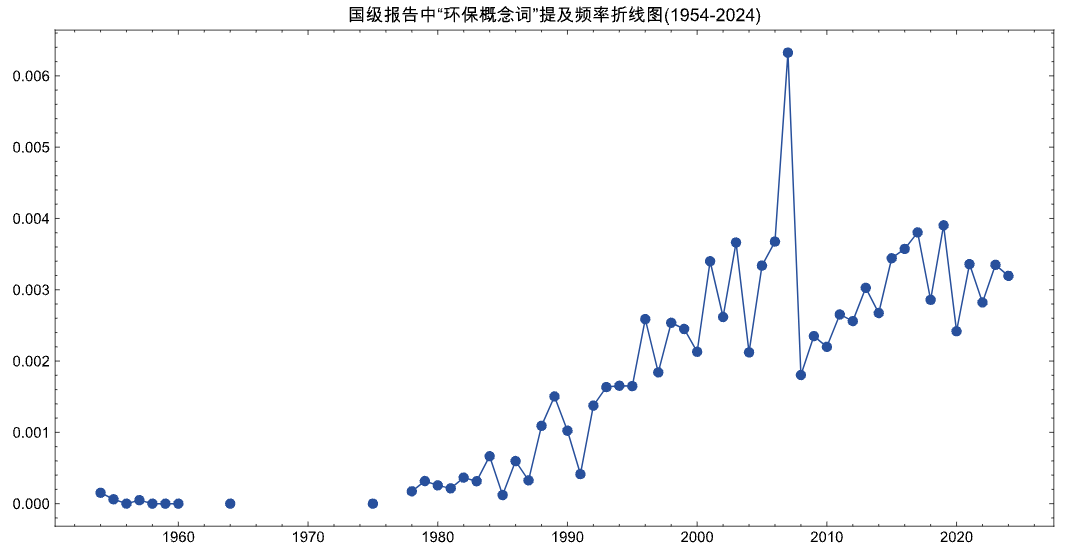
plt.figure(figsize=(12, 6))
ndf.sort_values('year', inplace=True)
plt.scatter(ndf['year'], ndf['env_ratio'])
plt.plot(ndf['year'], ndf['env_ratio'])
plt.title('国级报告中“环保概念词”提及频率折线图(1954-2024)')
plt.show()
大家应该都学过正泰分布中, 数据中大多数的记录会落在 均值+-标准差 范围内,
这里设置 top_nation_mask、bottom_nation_mask ,分别识别到最重视环保的年份、最不重视环保的年份
top_nation_mask = ndf['env_ratio'].mean() + ndf['env_ratio'].std()
bottom_nation_mask = ndf['env_ratio'].mean() - ndf['env_ratio'].std()
print('最重视环保的年份')
print(ndf[ndf['env_ratio']>top_nation_mask].year.values)
print()
print('最忽视环保的年份')
print(ndf[ndf['env_ratio']<bottom_nation_mask]['year'].values)
Run
最重视环保的年份
[2001 2003 2005 2006 2007 2015 2016 2017 2019 2021 2023]
最忽视环保的年份
[1954 1955 1956 1957 1958 1959 1960 1964 1975 1978 1979 1980 1981 1983
1985 1987]
可以看到进入21世纪,国家对环保重视从报告中就能看出。而在前期,因为生存是首要解决的,对环境保护的认识事不足的。
3.2 省-词频
计算总词语数、某类词出现的次数,计算各省提及【环保】的频率。因为省份的记录有770条,现在咱们把条件变严格,
top = mean+3*std,
bottom = mean-2std
大家可以自己设置条件的严格程度
pdf['word_num'] = pdf['doc'].fillna('').apply(lambda text: len(jieba.lcut(text)))
pdf['env_num'] = pdf['doc'].fillna('').str.count('环保|环境|污染|青山|绿水')
pdf['env_ratio'] = pdf['env_num']/pdf['word_num']
top_prov_mask = pdf['env_ratio'].mean() + 3*pdf['env_ratio'].std()
bottom_prov_mask = pdf['env_ratio'].mean() - 2*pdf['env_ratio'].std()
print('最重视环保的省(年份)')
pdf[pdf['env_ratio']>top_prov_mask][['province', 'year']]

重视环保结果挺合理的, 某人曾在浙江任职过,对环保比较重视,近年来浙江也比较重视环保,是真的很早就执行,环保搞得很好。而河北,笔者家乡,主要是跟钢铁产业关停并转,守卫di都蓝天有很大关系。
更多内容可在大邓博客 textdata.cn 中寻找相关代码。
