获取代码

如何用LDA预测文本的话题类型,本文将覆盖以下代码技术
- csv数据读取
- 文本预处理
- 训练(保存)lda模型
- 预测话题
一、读取数据
本文使用的数据集来自于 之前分享的 网络爬虫 | 知乎热门话题「全职儿女」
import pandas as pd
df = pd.read_csv('data/知乎-全职儿女.csv', encoding='utf-8')
df.dropna(subset=['content'], inplace=True)
print('记录数: ', len(df))
df.head(2)
记录数: 411

二、清洗数据
import re
import jieba
stoptext = open('data/stopwords.txt', encoding='utf-8').read()
stopwords = stoptext.split('\n')
def clean_text(text):
# 用正则表达式提取中文文本
text = ''.join(re.findall('[\u4e00-\u9fa5]+', text))
words = jieba.lcut(text)
words = [w for w in words if w not in stopwords]
#整理成用空格间隔词语的文本形式(类似西方语言)
return ' '.join(words)
test_text = "首先,我认为「全职儿女」不应该被简单地归为啃老。在目前社会环境下,随着经济、教育等发展,年轻..."
clean_text(text=test_text)
Run
'全职 儿女 简单 地归为 啃 老 社会 环境 经济 教育 发展 年轻'
df['clean_content'] = df['content'].apply(clean_text)
df.head(1)

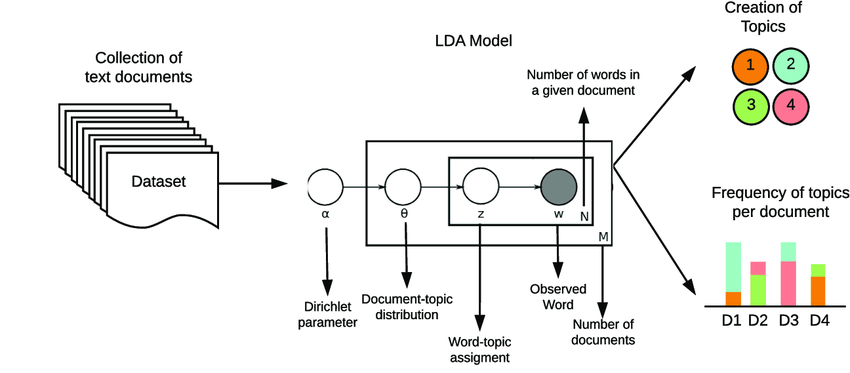
三、训练LDA模型
3.1 训练

根据词云图, 假设对数据比较了解,可以直接设置话题数 n_components = 4
from sklearn.feature_extraction.text import CountVectorizer,TfidfVectorizer
from sklearn.decomposition import LatentDirichletAllocation
# 构建词典,将词转为数字。将文档转为向量
vectorizer = TfidfVectorizer(max_df=0.5, min_df=20)
doc_term_matrix = vectorizer.fit_transform(df['clean_content'])
# 构建LDA话题模型
# 初始化模型,设置话题数为4,随机状态码888
lda_model = LatentDirichletAllocation(n_components=4, random_state=888)
lda_output = lda_model.fit_transform(doc_term_matrix)
lda_model
3.2 保存模型
如果训练过程非常久,保存模型,下次就可以跳过训练阶段,直接使用模型。
import joblib
# # 保存模型
joblib.dump(lda_model, 'output/全职儿女lda_model.pkl')
['output/全职儿女lda_model.pkl']
3.3 导入模型
import joblib
"""导入保存的模型"""
lda_model = joblib.load('output/全职儿女lda_model.pkl')
lda_model

四、使用LDA模型
4.1 查看话题特征词
获得每个话题对应的的n个特征词,方便后续对每个话题命名和解读
import numpy as np
def show_topics(vectorizer, lda_model, top_n=30):
"""
显示每个话题最重要的n个词语
vectorizer: 词袋法或tfidf.基于前面代码这里使用TF-IDF法
lda_model: 训练好的lda话题模型
top_n: 设置最重要的n个特征词,默认30个.
"""
keywords = np.array(vectorizer.get_feature_names_out())
topic_keywords = []
for topic_weights in lda_model.components_:
top_keyword_locs = (-topic_weights).argsort()[:top_n]
topic_keywords.append(keywords.take(top_keyword_locs))
return topic_keywords
"""利用show_topics函数展示全职儿女文本中的4个话题,基于每个话题最重要的20个词语为每个话题命名"""
topic_keywords = show_topics(vectorizer=vectorizer, # 【可改动】vectorizer我们训练的词语空间
lda_model=lda_model, # 【可改动】lda_model训练的lda模型
top_n=20) # 【可改动】最重要的30个词语
df_topic_keywords = pd.DataFrame(topic_keywords)
df_topic_keywords.columns = ['Word-' + str(i) for i in range(df_topic_keywords.shape[1])]
df_topic_keywords.index = ['Topic-' + str(i) for i in range(df_topic_keywords.shape[0])]
df_topic_keywords

4.2 预测文本的话题id
import numpy as np
def predict_topic(text):
doc_term_matrix = vectorizer.transform([clean_text(text)])
topic_term_prob_matrix = lda_model.transform(doc_term_matrix)
topic_index = np.argmax(topic_term_prob_matrix)
return topic_index
test_text2 = "最近,“全职儿女”话题受到舆论关注。“全职儿女”是指一种新型的脱产生活方式,年轻人脱产寄居父母生活,并通过付出一定的劳动换取经济支持,同时保持学习提升或发展副业的状态。这种生活方式既有其合理性和正当性,也有其问题和风险。我们不能一概而论,也不能一味否定或肯定。"
topic_index = predict_topic(test_text2)
print("该文本所属Topic: ", topic_index)
Run
该文本所属Topic: 0
#批量预测
df['话题ID'] = df['clean_content'].apply(predict_topic)
df.head(1)

df['话题ID'].value_counts()
Run
话题ID
0 214
1 88
3 84
2 25
Name: count, dtype: int64
#预测结果保存到csv、xlsx中。
df.to_csv('output/话题预测结果.csv', index=False)
df.to_excel('output/话题预测结果.xlsx', index=False)

