词嵌入在经管中的应用很多,但大多数是训练词嵌入模型,依据词嵌入构建或扩展词典。 今天我们将分享一篇用词嵌入测量团队认知多样性。

一、研究
Lix, Katharina, Amir Goldberg, Sameer B. Srivastava, and Melissa A. Valentine. “Aligning differences: Discursive diversity and team performance.” Management Science 68, no. 11 (2022): 8430-8448.
1.1 摘要
团队中的认知多样性如何影响其绩效?先前的研究表明,团队的认知多样性存在绩效权衡:多样性团队在创造力和创新方面表现出色,但在协调行动方面则有困难。基于团队认知不是静态的,而是动态互动产生的观点,我们引入了 话语多样性 的概念,这是团队认知多样性的一种表现,反映了在一组互动中团队成员传达的含义在多大程度上相互不同。我们提出,高绩效团队是那些具有调节共享认知以适应不断变化的任务要求的集体能力的团队:在进行构思任务时,它们表现出更高的话语多样性,在执行协调任务时,表现出较低的话语多样性。我们进一步认为,表现出一致调节的团队——即,在成员对不断变化的任务要求的个人语义变化中团队层面方差较低的团队——更有可能取得成功,而不是由成员之间存在不一致的调节。我们利用 计算语言学 工具来衡量话语多样性,并借助一组新型纵向数据,包括117个在线平台 www.gigster.com 上的远程软件开发团队的团内电子通信和绩效结果,得出了对我们理论的支持。我们的研究结果表明,团队认知多样性的绩效权衡并非不可避免:团队可以通过将话语多样性水平与任务要求相匹配以及在进行这些调整时使成员保持一致来应对这一权衡。
1.2 创新点
这篇论文的创新点主要包括以下几个方面:
-
研究了团队内部的差异对团队绩效的影响:该论文通过分析团队成员之间的差异,探讨了这些差异对团队绩效的影响。这一研究角度对于理解团队内部动态和绩效提升具有重要意义。
-
引入了阶段性的话语差异概念:论文提出了阶段性的话语差异概念,即团队成员在不同阶段的沟通中所表现出的差异。这一概念有助于更好地理解团队内部沟通的动态过程。
-
探讨了团队内部沟通差异的调节作用:论文研究了团队内部沟通差异与团队绩效之间的关系,并发现团队内部沟通差异在不同阶段对团队绩效的影响存在差异。这一发现为团队管理和绩效提升提供了重要的启示。
-
结合了多个学科领域的理论和方法:该论文综合运用了心理学、经济学和组织学等多个学科领域的理论和方法,从多个角度深入研究了团队内部差异和绩效之间的关系,为相关领域的研究提供了新的视角和方法。
二、文献梳理
2.1 认知多样性
认知多样性(cognitive diversity)对团队绩效的影响是一个长期存在的问题。以往的研究表明,团队的认知多样性存在绩效权衡:多样性团队在创造力和创新方面表现出色,但在协调行动方面存在困难。然而,最近的研究提出了一种新的观点,即团队的「认知多样性」可以通过调节团队的「共享认知」来实现绩效的平衡。这意味着团队可以根据任务要求调整其认知多样性的水平,以在创造性任务和协调任务之间找到平衡点。高绩效团队具备调节团队认知的能力,使其能够在创造性任务中展现较高的认知多样性,在协调任务中展现较低的认知多样性。这种能力使团队能够在创新和执行之间找到平衡,从而提高绩效。
2.2 话语多样性
话语多样性(discursive diversity) 是指团队成员在交流和讨论中表达的观点、意见和想法的多样性程度。它反映了团队成员在思考和表达上的差异程度。话语多样性可以包括词汇选择、句子结构、表达方式等方面的差异。
话语多样性对团队的协调行动有影响。在协调任务中,团队成员需要相互理解、协调行动,达成共识并共同努力实现共同目标。如果团队成员的话语多样性过高,意味着他们在表达观点和意见时存在较大的差异,这可能导致沟通困难、理解不一致和冲突的产生,从而影响团队的协调行动。
因此,在协调任务中,团队成员的话语多样性应该相对较低,以便更好地理解和协调彼此的行动。相反,在创意和思考任务中,话语多样性可以促进团队成员的创新和思考,帮助他们从不同的角度和观点来解决问题,从而提高团队的创造力和创新能力。总之,话语多样性在团队中起着重要的作用,它需要根据任务的性质和要求进行调节,以实现团队的协调行动和创新能力。
2.3 两者关系
在这篇论文中,话语多样性被用来衡量认知多样性。研究人员使用计算语言学的工具来推导出话语多样性的度量,并将其应用于团队的电子沟通数据中。他们认为,团队的话语多样性可以反映成员之间的认知多样性,即在思维方式、知识和技能等方面的差异程度。通过分析团队的话语多样性,研究人员试图探索团队在不同任务要求下的表现,并研究团队如何调节共享认知以适应任务需求的变化。因此,话语多样性被视为一种衡量团队认知多样性的指标。
三、数据及方法
3.1 数据
Gigster(www.gigster.com),是一个在线平台, 自由软件开发人员可以在该平台上为个人和企业客户制作按需软件。该平台将个人自由职业开发人员组装成由团队领导领导的临时团队,并将他们分配给需要复杂、相互依赖的长期项目。该平台上的自由职业者分布在全球各地,从事从移动到网络应用程序开发的各种项目。这些项目通常是知识密集型的,需要高水平的创造力、技术问题解决能力和人际协调能力。软件项目规模巨大,成本从数万美元到数十万美元不等(极端情况下可达一百万美元以上)。
我们的数据集由 117 个团队组成,代表 421 个不同的个体(36% 为女性),时间跨度从 2015 年初到 2017 年底。一个典型的团队有 5 名成员,其中包括一名项目经理;至少一名后端、前端或“全栈”工程师;设计师;和用户界面专家。根据项目类型,团队有时还包括作家、自然语言处理工程师和其他类型的专业人士。在我们数据中的团队中,项目平均持续 159 天(中位数:150 天),并分为平均持续两周的里程碑阶段(平均:14 天;中位数:14 天)。要加入该平台,专业人士必须通过旨在验证其专业知识的各种技术面试。平均而言,单个团队的成员代表 3.6 个国家/地区(中位数:3 个)。在我们的样本中,42% 的人将其原籍国列为北美。另外 13% 来自亚洲,其次是 12% 来自欧洲。其余 23% 居住在拉丁美洲、非洲和世界其他地区。
由于地理位置分散且缺乏实体办公空间,团队成员几乎完全通过名为 Slack 的在线即时通讯工具进行沟通。我们可以访问整个团队的 Slack 档案——超过 800,000 条消息。每条消息都带有时间戳并可归因(通过匿名标识符)其作者。团队在整个生命周期中平均在公共渠道中交换 1,873 条 Slack 消息(中位数:1,220 条)。我们对 Gigster 的高级领导和团队领导进行了非正式采访,他们一致表示团队沟通几乎完全通过 Slack 进行。一位高级领导描述了其中的原因:“几乎所有团队对话都发生在 Slack 上。这是一个有用的工具,因为我们运营全球团队,而且 Slack 允许在一个平台内进行实时和异步通信。它还允许轻松地共享项目文件。” 多位知情人士强调,团队成员始终依赖 Slack,而不是其他工具,因为“一切都在一个地方”对于促进团队协作非常重要。知情人士还表示,团队成员有动力使用 Slack,因为它提供了团队流程和事件的透明档案,可用于对一些罕见的争议案例进行分类。
除了 Slack 消息之外,我们还可以获得有关团队成员特征(职能角色、性别和原籍国)的数据,以及团队在实现各个项目里程碑方面的整体绩效。这些数据共同构成了团队内部动态和结果的丰富且连续的历史记录。
3.2 计算话语多样性
之前的工作表明,词嵌入模型对于捕获单词之间的语义关系特别有用, 例如,(2018) 证明,根据应用于 20 世纪出版的英语书籍的词嵌入模型推断出的不同职业的语义性别关联与这些职业的历史性别构成相对应。同样,科兹洛夫斯基等人(2019)说明了不同的生活方式活动如何与阶级、种族和性别认同相关。因此,词嵌入为语言中包含的众多意义维度提供了全面且有意义的见解,而这是以前的方法无法捕获的。因此,本论文使用词嵌入模型开发了话语多样性度量。
我们首先对 Slack 数据进行预处理,并使用 Word2Vec(连续词袋词嵌入模型的流行实现)来训练词嵌入模型。
按照标准实践,窗口大小设置为10, 维度设置成200来训练word2vec模型(Mikolov 等人,2013)。从这个训练过程中,我们获得了语料库中每个单词的一个 200 维坐标向量,表示该单词在语义空间中的位置。
窗口大小: 每个词的上下文范围。 人阅读书籍,一般视野只有十来个词,逐行阅读。 跟人类似, 在计算机中训练词嵌入模型时候,数据不是一次性灌入习得词语的向量,而是像人一样是有上下文范围的,这个范围叫做窗口。
如前所述,嵌入空间的维度表示训练语料库中语言使用的潜在特征。尽管这些维度本身不具有定性可解释的含义,但这些维度是提供信息的,因为具有更相似含义的单词彼此更接近。下图(a)是从聊天消息构建词嵌入向量的过程:

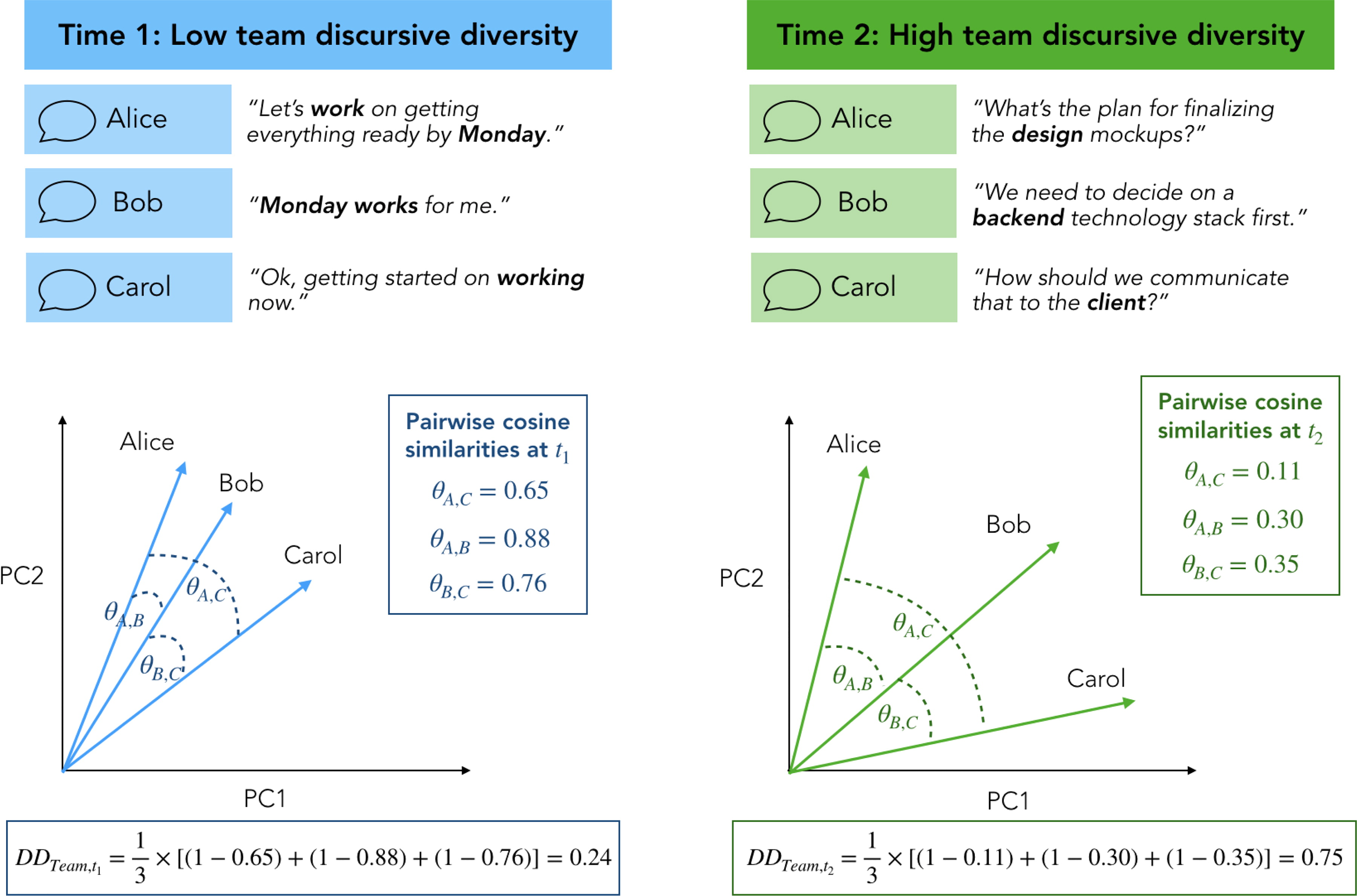
**使用词嵌入模型,我们就可以把词语、每句话、某人某时期的话、某团队某时期的话、所有团队所有的话,通过一定的计算,都表征为200维的向量。**上图 (b) 从聊天消息构建团队话语多样性得分(Discursive Diversity)。
通过公式1,计算出两个人差异性。通过公式2, 计算出团队话语多样性。


假设团队只有三个人, 低话语多样性 与 高话语多样性, 分别对应下图的左侧和右侧。

四、Python伪码
import numpy as np
def discursive_diversity_score(wv, words):
# wv: 词嵌入模型; gensim.models.keyedvectors.KeyedVectors
# words: 一个时间窗口内的词语列表
# 计算词嵌入向量的平均值
embedding_vectors = [wv[word] for word in words]
centroid = np.mean(embedding_vectors, axis=0)
# 计算词嵌入向量之间的余弦相似度
pairwise_distances = [np.dot(centroid, embedding) / (np.linalg.norm(centroid) * np.linalg.norm(embedding)) for embedding in embedding_vectors]
# 计算语言多样性得分
diversity_score = np.mean(pairwise_distances)
return diversity_score
函数 discursive_diversity_score 已内置到 cntext 中。 对cntext 感兴趣,可阅读 文本分析库cntext使用手册
五、词嵌入应用文献
# 使用词嵌入技术构建词典
[1]胡楠, 薛付婧 and 王昊楠, 2021. **管理者短视主义影响企业长期投资吗———基于文本分析和机器学习**. *管理世界*, *37*(5), pp.139-156.
[2]Kai Li, Feng Mai, Rui Shen, Xinyan Yan, **Measuring Corporate Culture Using Machine Learning**, *The Review of Financial Studies*,2020
# 使用词嵌入测量偏见(刻板印象)、认知
[3]Lawson, M. Asher, Ashley E. Martin, Imrul Huda, and Sandra C. Matz. "**Hiring women into senior leadership positions is associated with a reduction in gender stereotypes in organizational language.**" _Proceedings of the National Academy of Sciences_ 119, no. 9 (2022): e2026443119.
[4]Lix, Katharina, Amir Goldberg, Sameer B. Srivastava, and Melissa A. Valentine. "**Aligning differences: Discursive diversity and team performance.**" *Management Science* 68, no. 11 (2022): 8430-8448.
cntext使用声明
如在研究或项目中使用 cntext ,请在文中介绍并附引用声明。引用格式可参考 cntext 推荐引用格式
