作者: JOSH
原文: https://www.kaggle.com/code/joshuaswords/awesome-eda-2021-happiness-population/notebook
幸福指数
本笔记本纯粹是一项探索性数据分析,目的是看看我能否找出使一个国家感到幸福或不幸的因素。为此,我将分析和探索2021年的世界幸福指数,以及自2005年以来的历史世界幸福指数数据。
我希望在这个过程中能学到一些东西,也希望读到这篇文章的任何人也能如此。
另外,我会引入人口数据来研究这是否与幸福水平有明显的联系。
我还将探索各国是否能够随着时间的推移改善其排名,或者这些排名是否基本保持不变。
最后,我将使用K均值和肘部方法正式地对我们的数据进行聚类,以查看我们是否可以根据数据集中各种指标的分数将国家分组在一起。
准备工作
安装必要的包
pip3 install pywaffle, geopandas, pycountry
本文代码较多, 只展示部分代码,点击完整的代码&数据,请前往textdata.cn下载。
导入数据
import pandas as pd
import warnings
warnings.filterwarnings("ignore")
import matplotlib
import matplotlib.pyplot as plt
#get data
df = pd.read_csv('data/world-happiness-report-2021.csv')
df2 = pd.read_csv('data/world-happiness-report.csv')
pop = pd.read_csv('data/population_by_country_2020.csv')
safety = df.copy()
# 统一不同数据中的字段名renaming columns for easier merge later
df.rename(columns={'Country name': 'Country'}, inplace=True)
df2.rename(columns={'Country name': 'Country'}, inplace=True)
pop.rename(columns={'Country (or dependency)': 'Country'}, inplace=True)
#might use later
temporal = df2.groupby(['year','Country'])['Life Ladder'].mean().unstack().T
temporal = temporal.fillna(0).astype(int)
# colours
low_c = '#dd4124'
high_c = '#009473'
plt.rcParams["font.family"] = "monospace"
初始概览
# inspiration ; https://www.kaggle.com/gaetanlopez/how-to-make-clean-visualizations
# changed code signif.
fig = plt.figure(figsize=(6,3),dpi=150)
gs = fig.add_gridspec(1, 1)
gs.update(wspace=0.2, hspace=0.4)
ax0 = fig.add_subplot(gs[0, 0])
background_color = "#fafafa"
fig.patch.set_facecolor(background_color) # figure background color
ax0.set_facecolor(background_color)
ax0.text(1.167,0.85,"2021 World Happiness Index",color='#323232',fontsize=28, fontweight='bold', fontfamily='sanserif',ha='center')
ax0.text(1.13,-0.35,"stand-out facts",color='lightgray',fontsize=28, fontweight='bold', fontfamily='monospace',ha='center')
ax0.text(0,0.4,"Finland",color=high_c,fontsize=25, fontweight='bold', fontfamily='monospace',ha='center')
ax0.text(0,0.1,"Happiest",color='gray',fontsize=15, fontfamily='monospace',ha='center')
ax0.text(0.77,0.4,"9 of top 10",color=high_c,fontsize=25, fontweight='bold', fontfamily='monospace',ha='center')
ax0.text(0.75,0.1,"in Europe",color='gray',fontsize=15, fontfamily='monospace',ha='center')
ax0.text(1.5,0.4,"7 of bottom 10",color=low_c,fontsize=25, fontweight='bold', fontfamily='monospace',ha='center')
ax0.text(1.5,0.1,"in Africa",color='gray',fontsize=15, fontfamily='monospace',ha='center')
ax0.text(2.25,0.4,"Afghanistan",color=low_c,fontsize=25, fontweight='bold', fontfamily='monospace',ha='center')
ax0.text(2.25,0.1,"Unhappiest",color='gray',fontsize=15, fontfamily='monospace',ha='center')
ax0.set_yticklabels('')
ax0.set_xticklabels('')
ax0.tick_params(axis='both',length=0)
for s in ['top','right','left','bottom']:
ax0.spines[s].set_visible(False)
import matplotlib.lines as lines
l1 = lines.Line2D([0.15, 1.95], [0.67, 0.67], transform=fig.transFigure, figure=fig,color = 'gray', linestyle='-',linewidth = 1.1, alpha = .5)
fig.lines.extend([l1])
l2 = lines.Line2D([0.15, 1.95], [0.07, 0.07], transform=fig.transFigure, figure=fig,color = 'gray', linestyle='-',linewidth = 1.1, alpha = .5)
fig.lines.extend([l2])
plt.show()

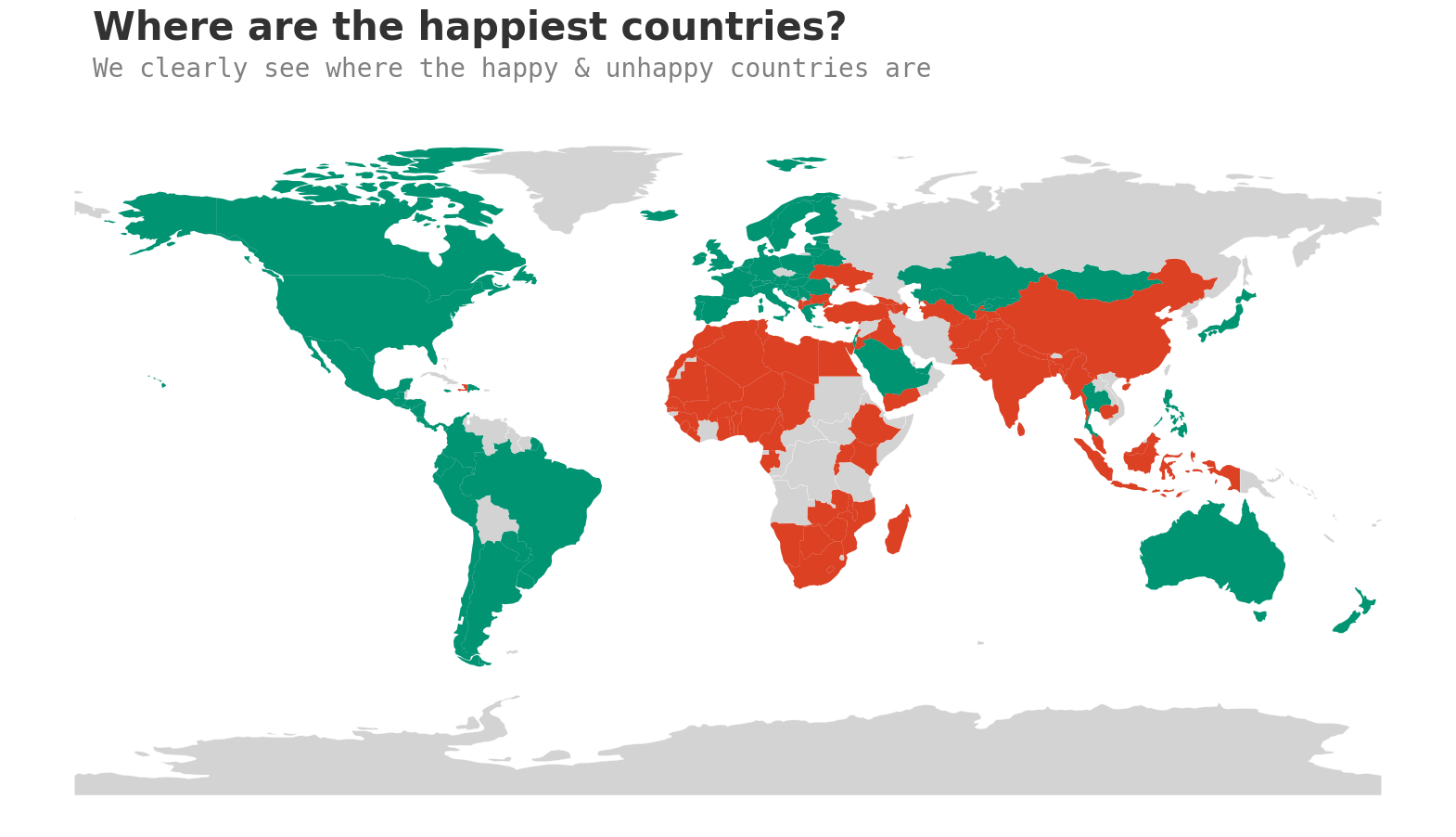
世界上最幸福的国家是哪些?
对我来说,'幸福‘似乎是一个个体化的指标,很难进行概括。然而,有些国家在幸福指数排名中表现始终稳定。
我们还注意到,前10名中有9个是欧洲国家,而后10名中有7个是非洲国家。
让我们看看目前位于列表顶端的国家,以及那些位于底部的国家。
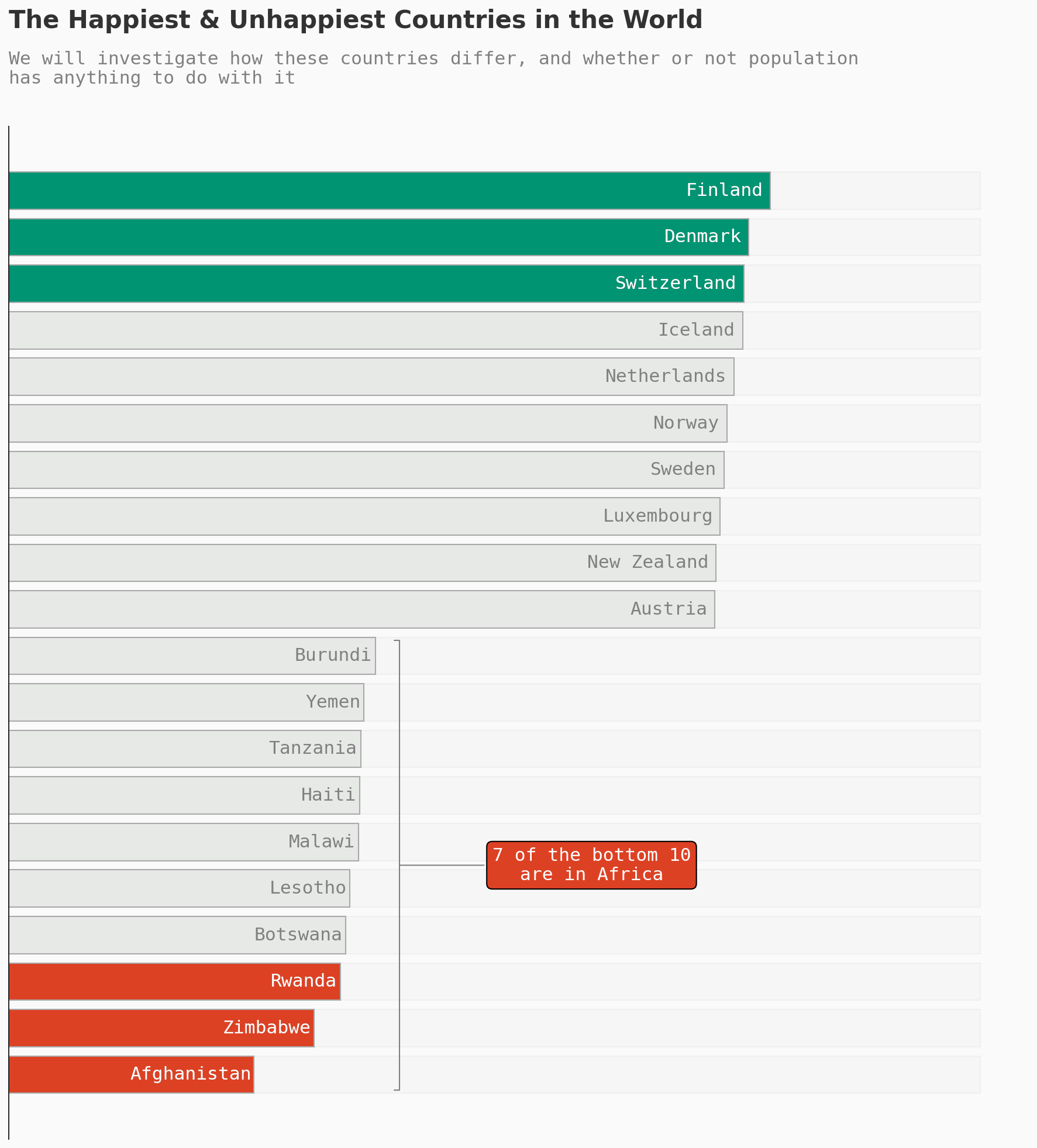
现在让我们把前10名和后10名并排放置,以便从另一个角度观察。

乍一看,我们发现世界上最幸福的许多国家确实位于欧洲。
另一个额外的观察是,位于前10名的欧洲国家都是北欧国家。
happiness_mean = df['Ladder score'].mean()
df['lower_happy'] = df['Ladder score'].apply(lambda x: 0 if x < happiness_mean else 1)
这种情况经常发生吗?
稍后我将更深入地探索时间上的变化,但现在,让我们看一下这些年来排在前20名的国家。
这个图展示了从2005年至今,前20名国家的所有分数,特别突出了它们的平均分和2021年的分数。
值得注意的是,尽管有疫情的影响,许多国家在2021年的分数比他们的平均分还要高。
尽管这些分数确实有所不同,但它们仍然相对较高。
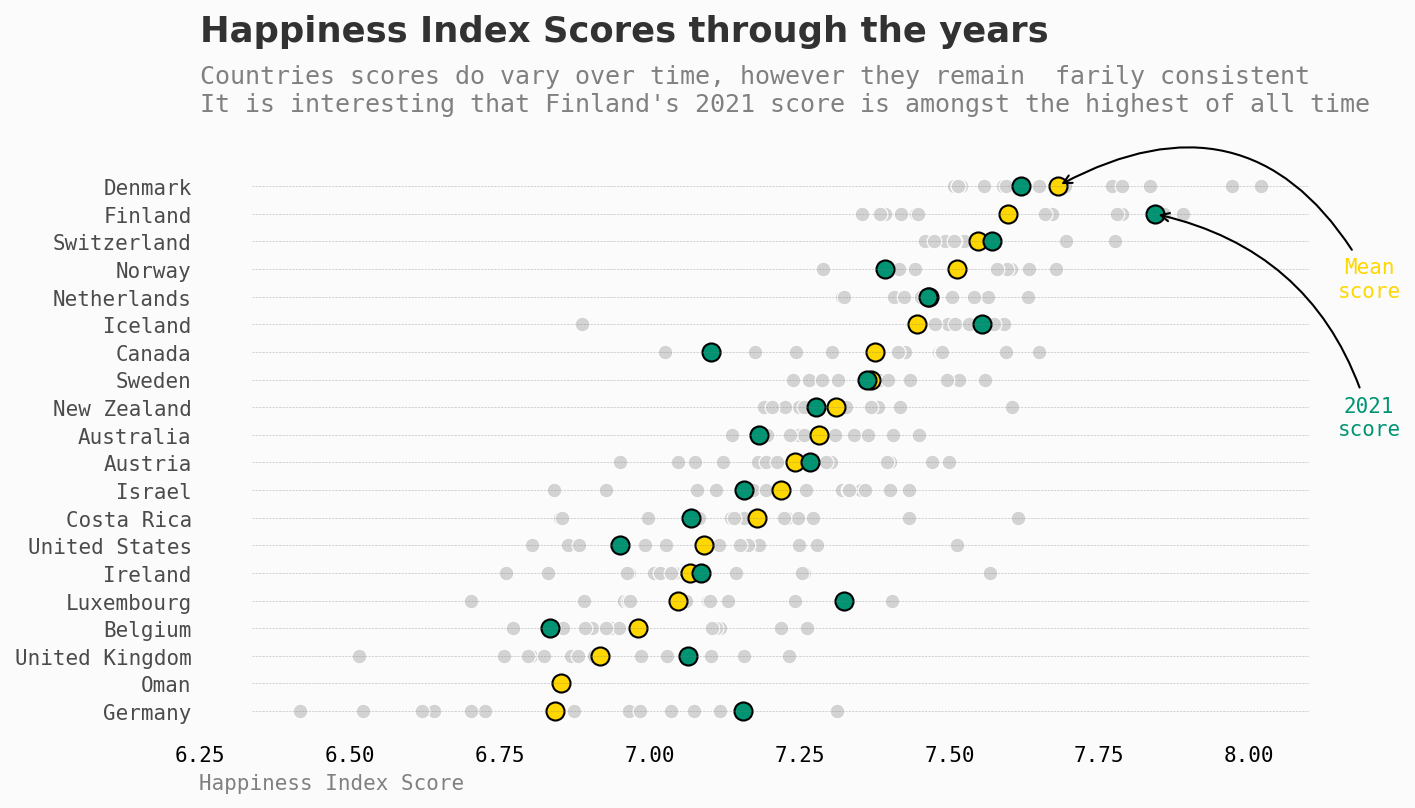
为什么会有差异?
我们现在了解到,北欧国家一直位居榜首。
让我们更仔细地探究一下欧洲与世界其他地区之间的这些差异。
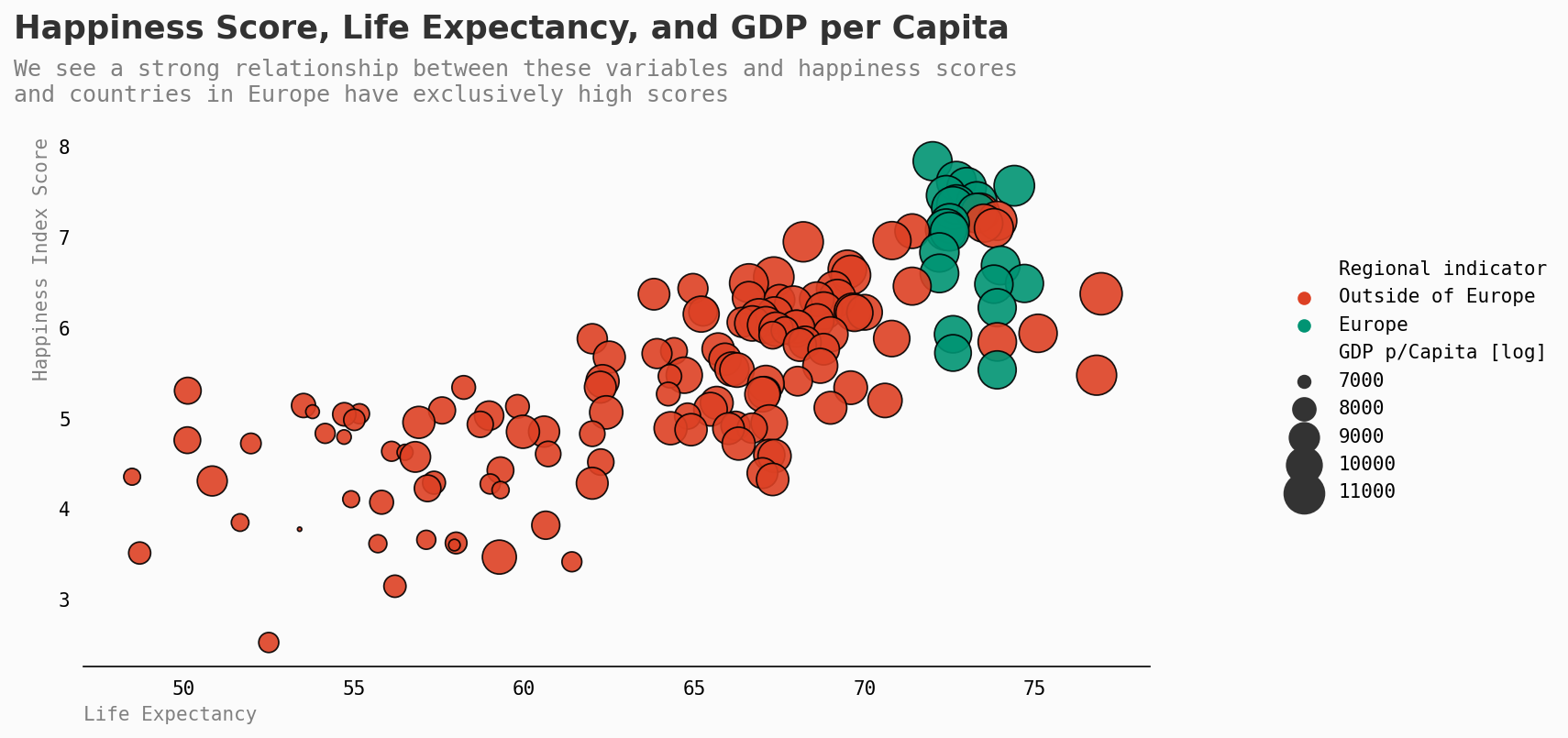
幸福程度较高的国家往往是那些预期寿命更长、GDP更高的国家。这也基本上包括了西欧。
现在让我们明确地关注一下非洲…
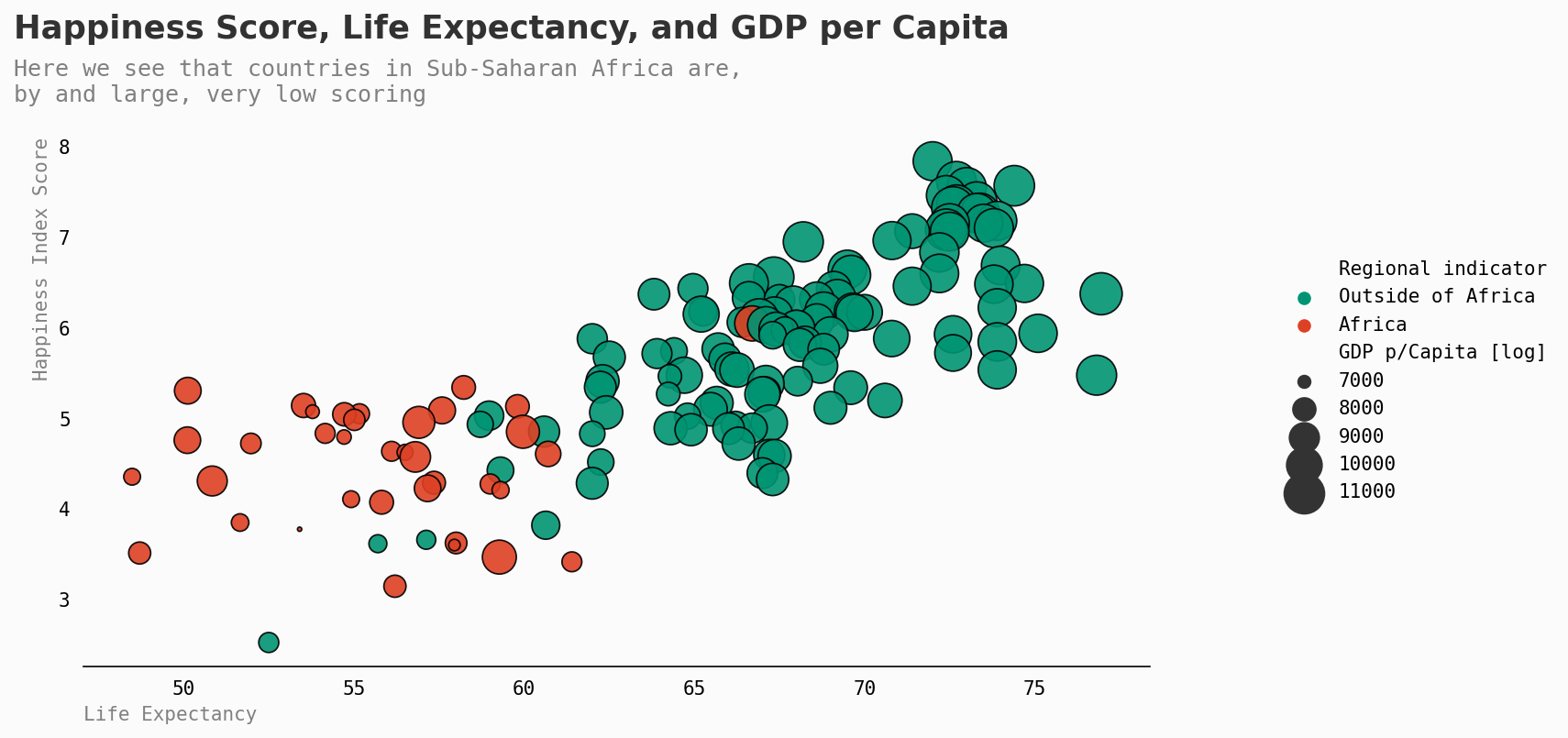
总体而言,非洲国家有更低的预期寿命、更低的GDP,最终也有更低的幸福指数分数。
其他因素
因此,GDP和预期寿命是影响因素。还有什么其他因素可以考虑呢?
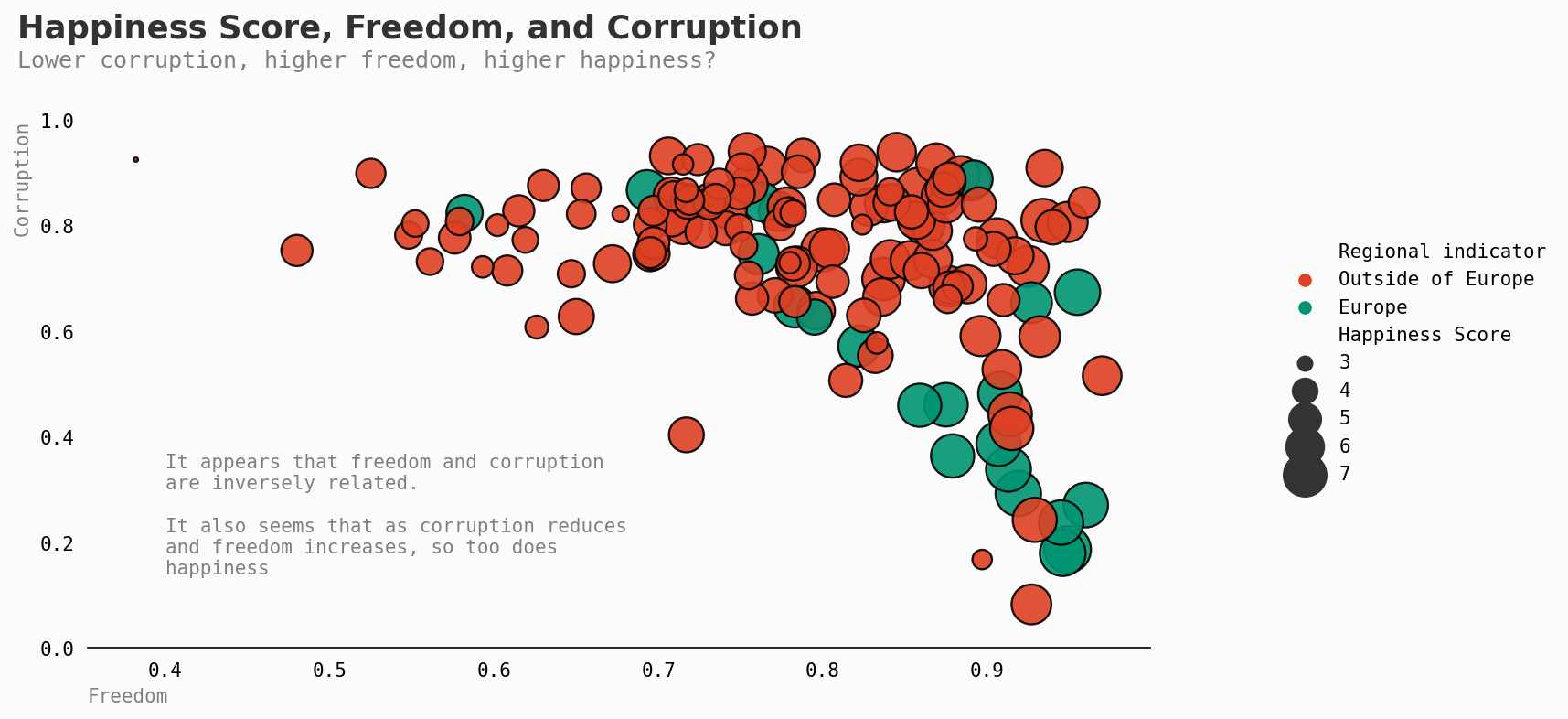
正如我在图中指出的,自由和腐败是成反比的关系:更高的腐败通常伴随着更低的自由度。
然而,有趣的是需要注意的是,几个欧洲国家也有高度认知的腐败水平。
大陆视角
让我们将这些国家按照各自所属的大陆分类,看看我们能否了解更多。
当然,我们预期西欧会排名很高,但是在幸福排名中,还有没有其他表现特别好或特别差的大陆?
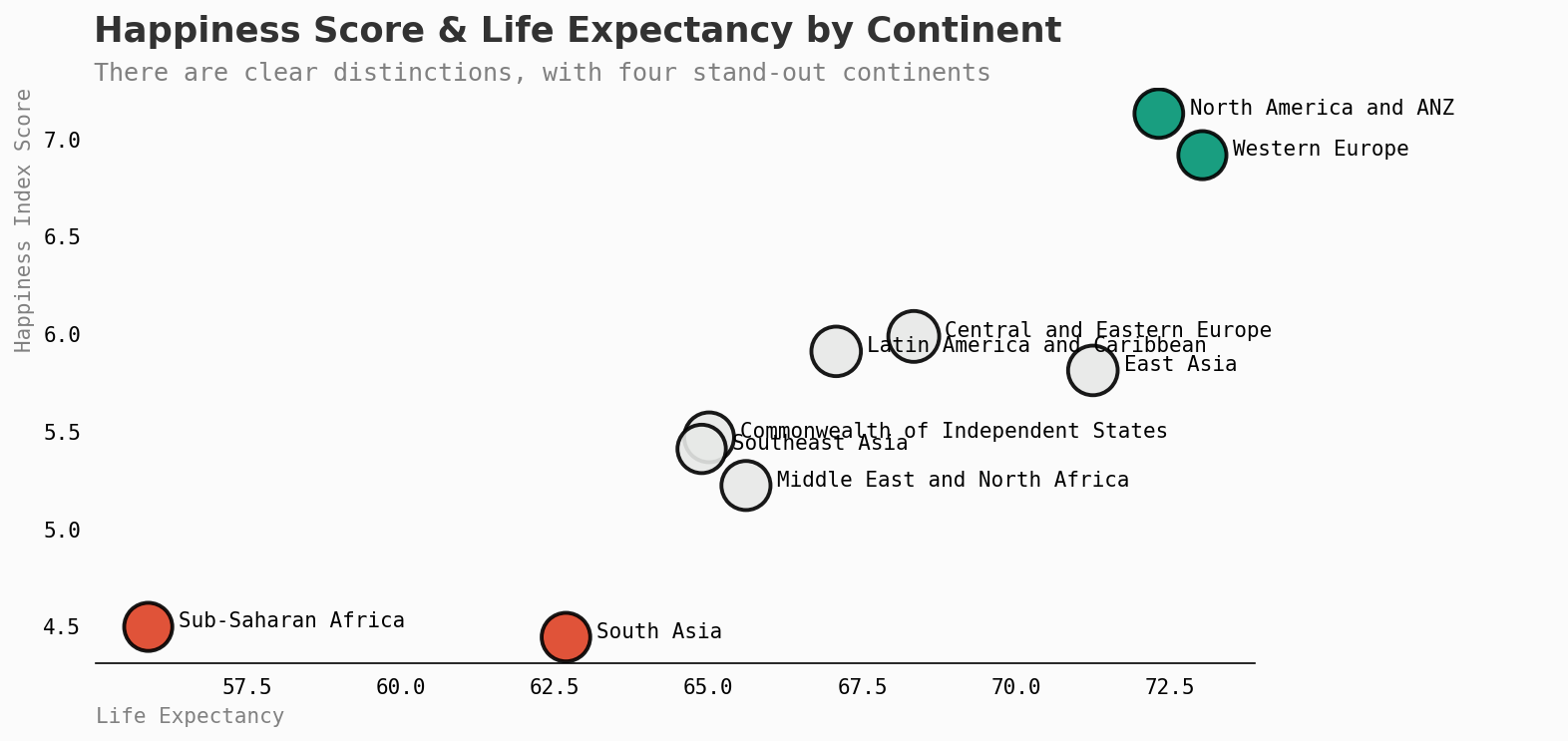
可以清晰地看到有三个大陆群体。稍后将对此进行更多讨论…
撒哈拉以南非洲和南亚的分数最低。而西欧以及北美和澳新(ANZ)则遥遥领先,位于榜单的顶端。
continent_score = df.groupby('Regional indicator')[['Healthy life expectancy','Logged GDP per capita','Perceptions of corruption','Freedom to make life choices','Ladder score']].mean().mean(axis=1).sort_values(ascending=True)[:10]
df_bottom = df.groupby('Country')[['Logged GDP per capita','Perceptions of corruption','Freedom to make life choices','Social support','Ladder score']].mean().sort_values(by='Ladder score',ascending=True)[:10]
df_bottom['Logged GDP per capita'] = df_bottom['Logged GDP per capita']/10
df_bottom['Ladder score'] = df_bottom['Ladder score']/5
categorical = [var for var in df.columns if df[var].dtype=='O']
continuous = [var for var in df.columns if df[var].dtype!='O']
#refined
continuous = ['Logged GDP per capita',
'Social support',
'Healthy life expectancy',
'Freedom to make life choices',
'Generosity',
'Perceptions of corruption']
高于和低于平均幸福水平的差异
让我们一次绘制多个特征,按照平均幸福水平进行划分。如往常一样,最幸福的国家以绿色显示。
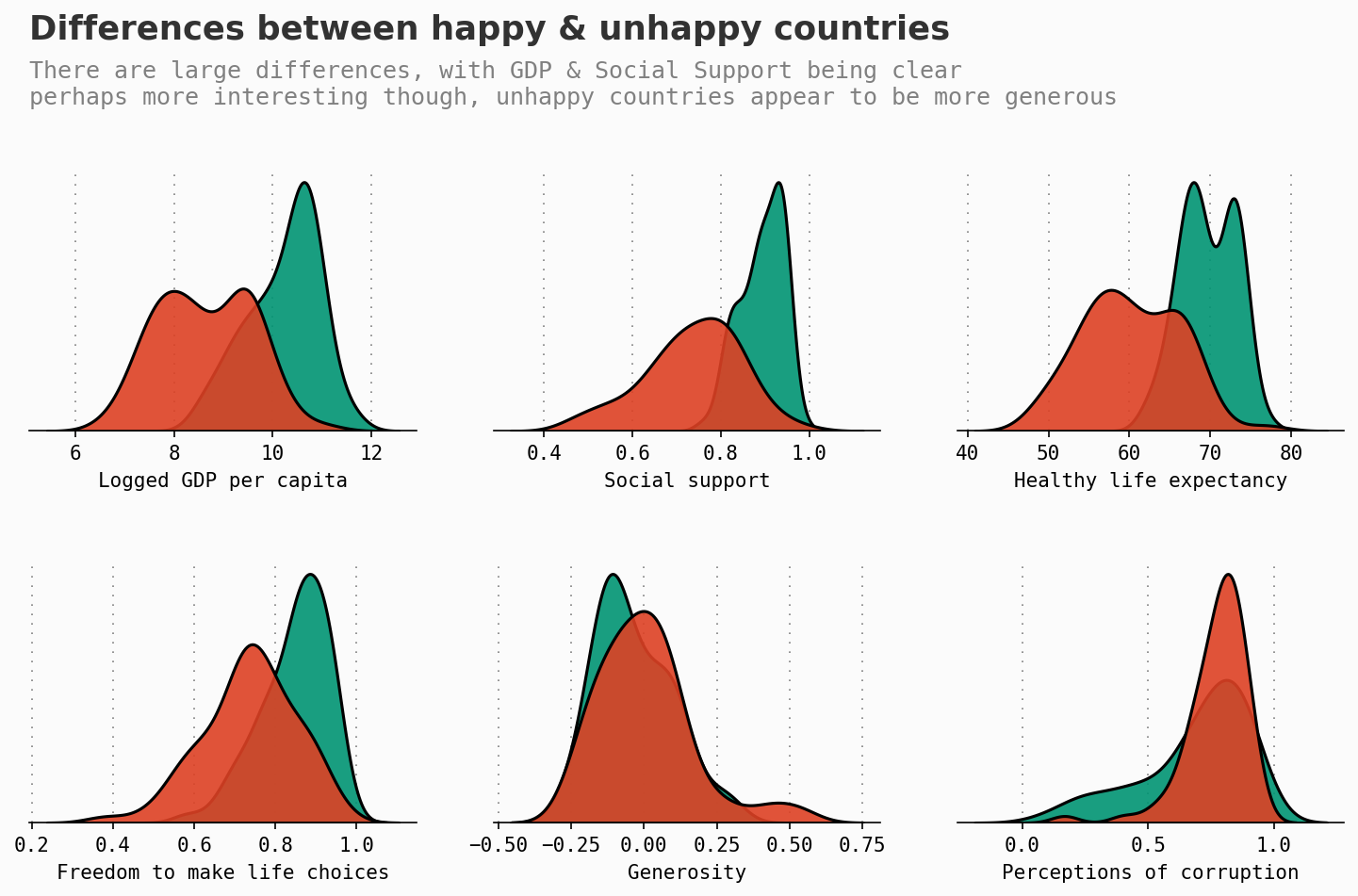
上面的图表确认了我们之前看到的一些内容,并带有一些值得注意的特点,比如社会支持。
在不太幸福的国家中,慷慨度被认为更高,这非常有趣。
全球视角
我们现在已经看到了基于多个因素不同国家之间明显的差异。
现在让我们从全球角度来看这个问题。
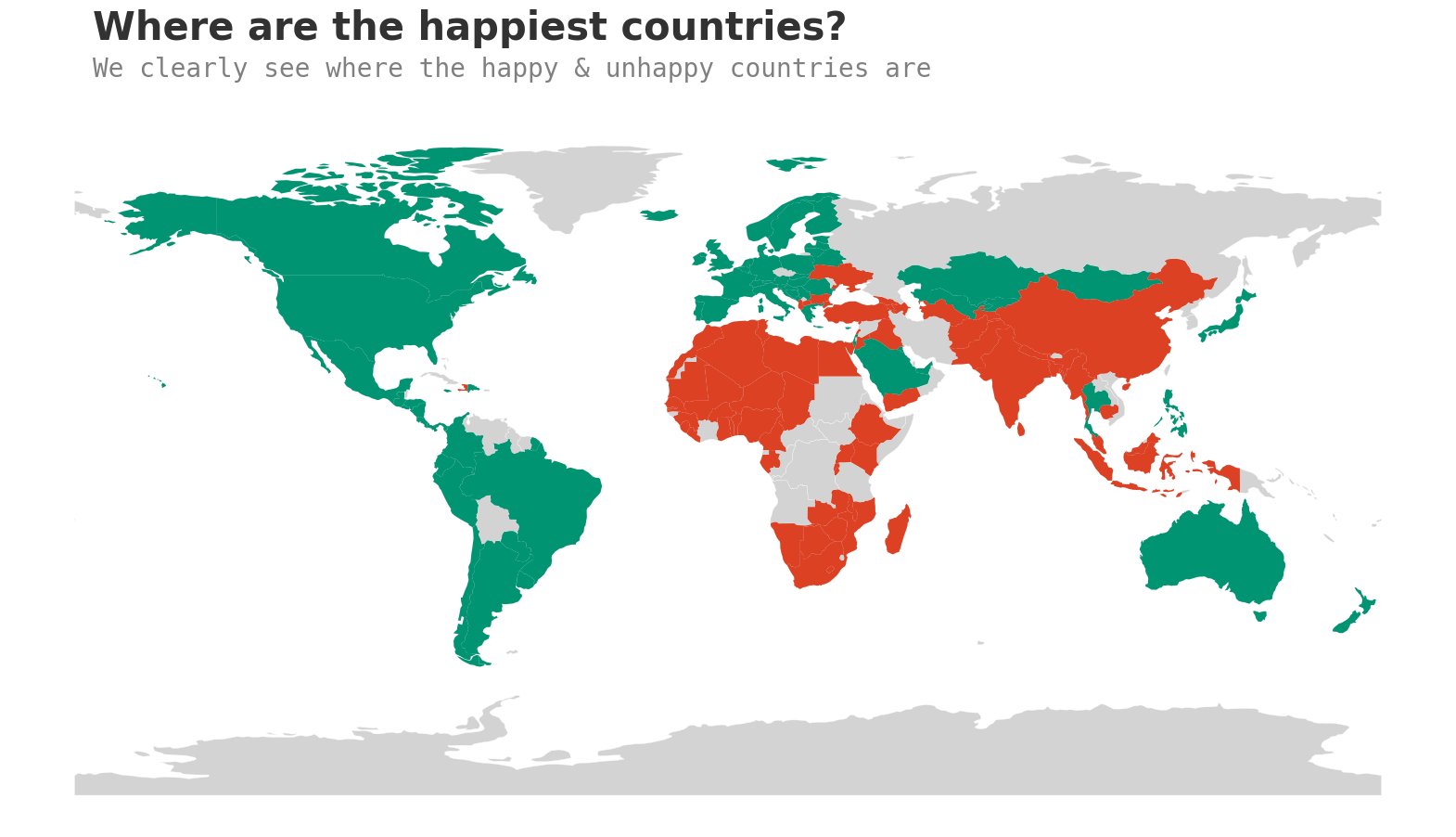
这张图确认了我们之前的发现,南亚和非洲处于红色区域。
但它也突出了我们可以进一步调查的地区。例如,中国和印度都在红色区域,它们的人口都超过了10亿。我们能否研究人口与幸福水平之间的关系?
人口
让我们引入更多的因素——比如人口。
这是否会影响幸福水平?
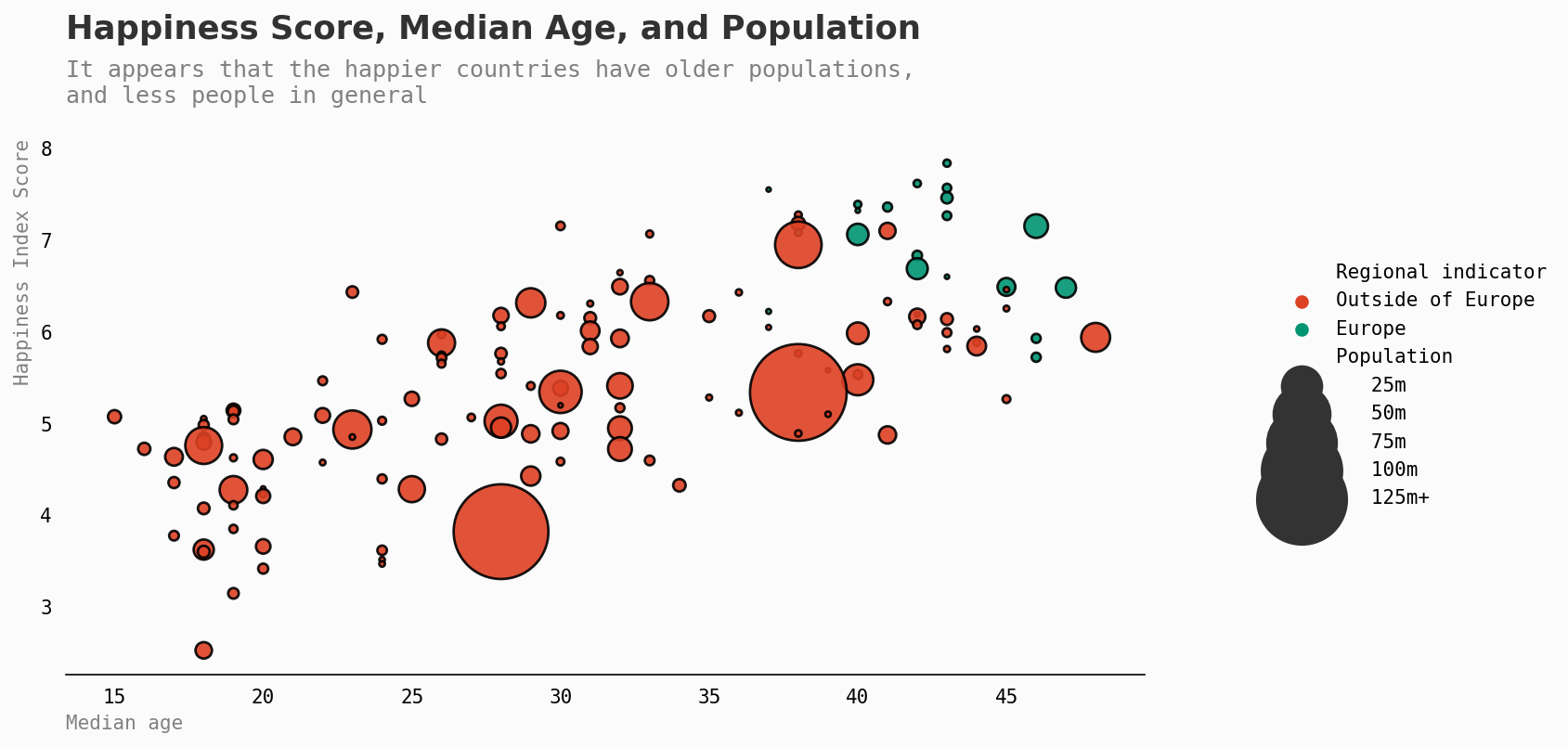
我们清晰地看到,更幸福的国家往往年龄更大,人口更少。
我加入了欧洲作为参考。
那么生育率呢?
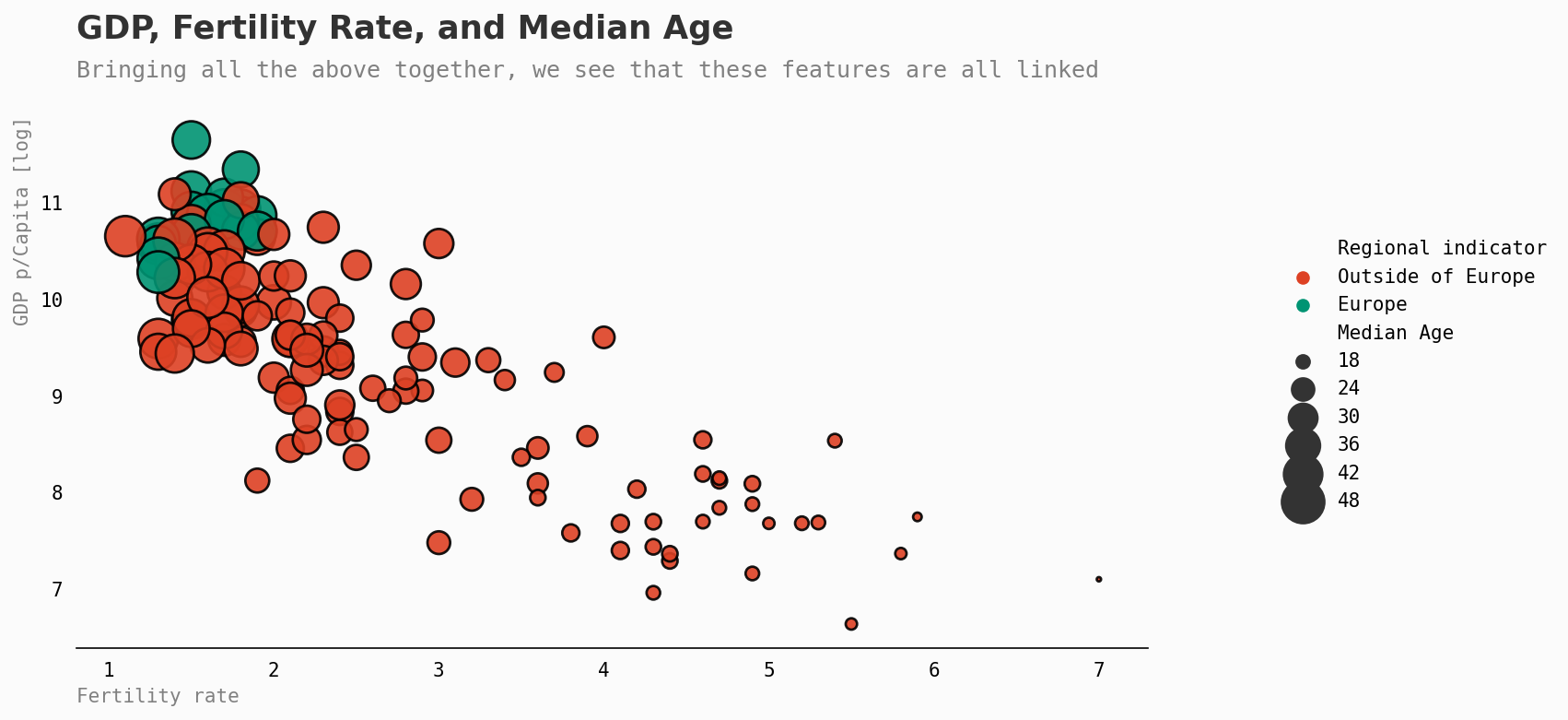
正如我所怀疑的,更幸福的国家通常也有更少的孩子。这很可能是由于可以更容易地获得避孕方法。
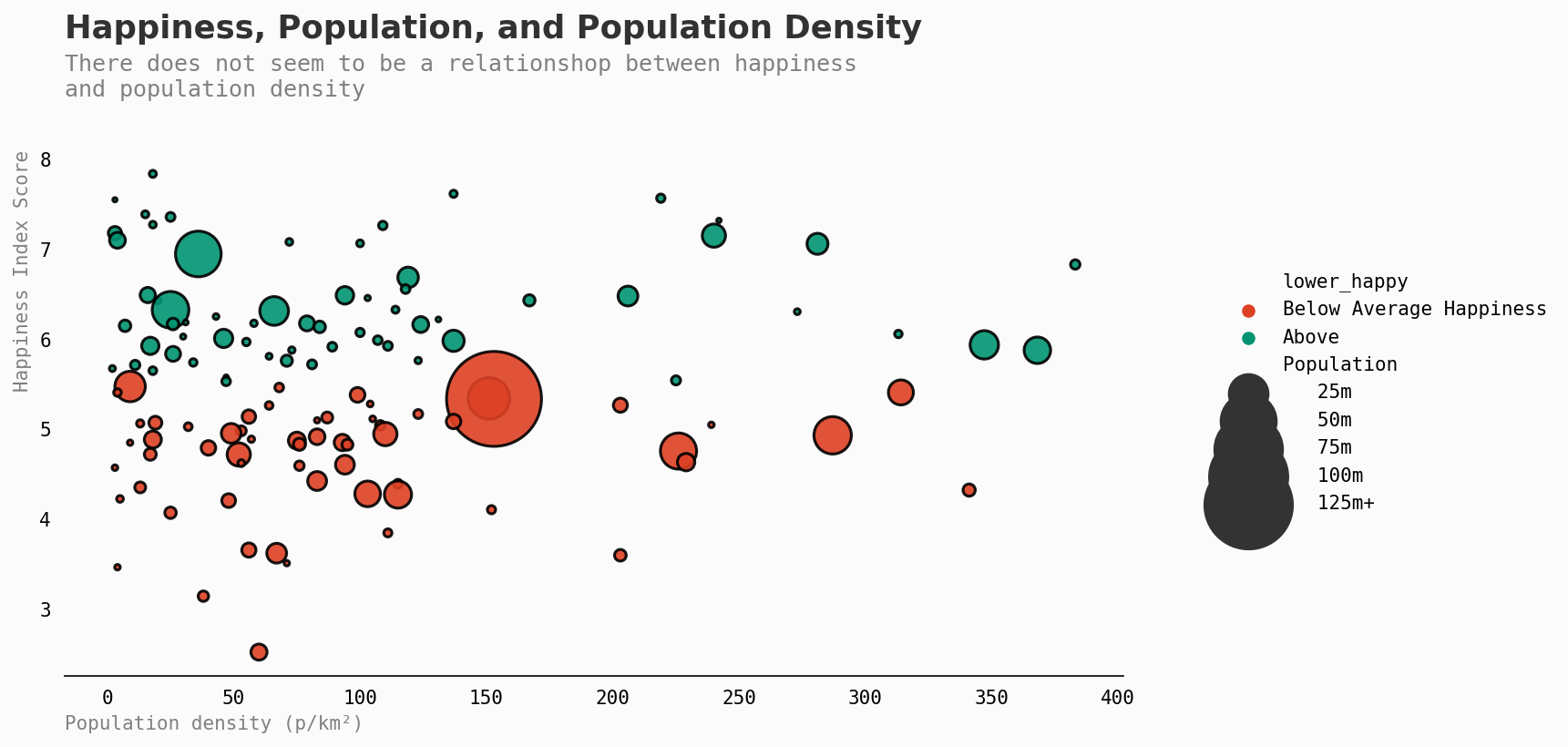
我很惊讶人口密度并不影响幸福感——尽管这可能是因为个人偏好!
随着时间的推移,有没有变化?
不快乐的人会变得更快乐吗?
这仅仅是一个时间点的快照吗?还是这些趋势更加持久?
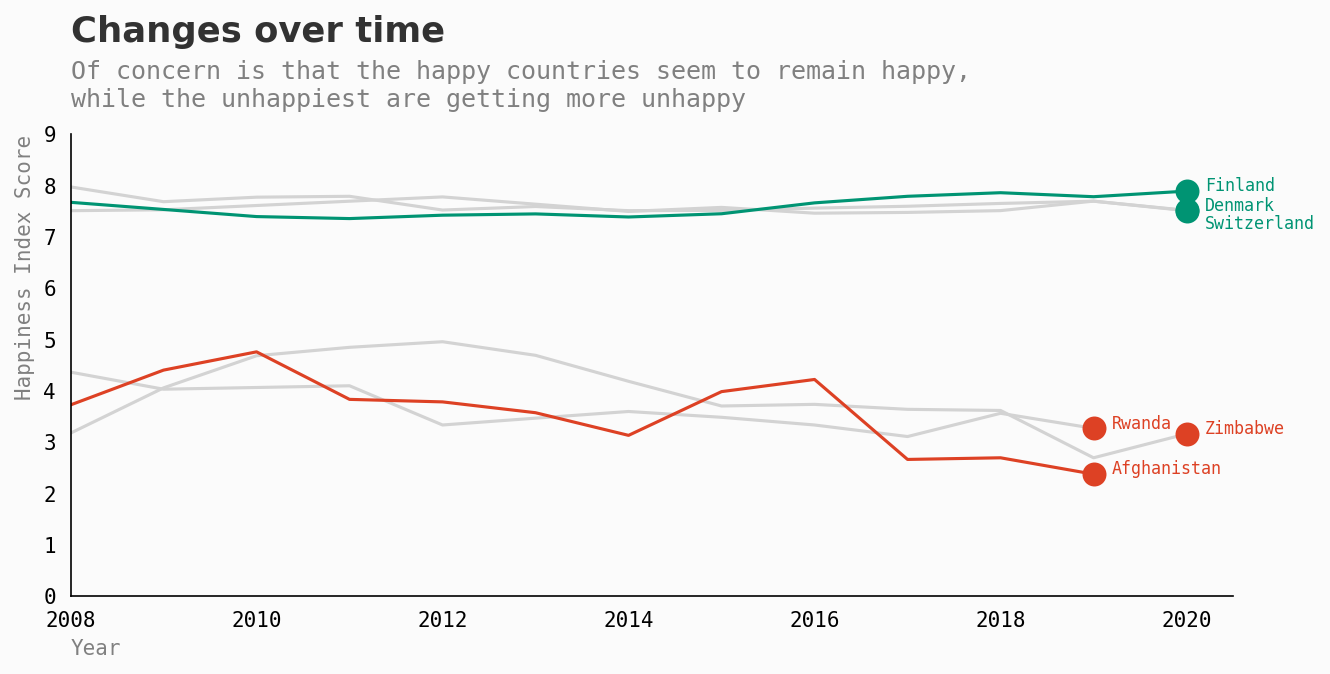
令人关注的是,不快乐的人依然不快乐,更糟糕的是,他们似乎变得更加不快乐。
这种趋势是持续的吗?或者某些国家的分数会随着时间的推移而提高?
让我们更多地探讨一下随时间变化的情况。
在上面,我选取了几个国家作为样本。让我们用一个斜率图来绘制他们从2007年到2020年的变化,看看我们能否从中学到什么。
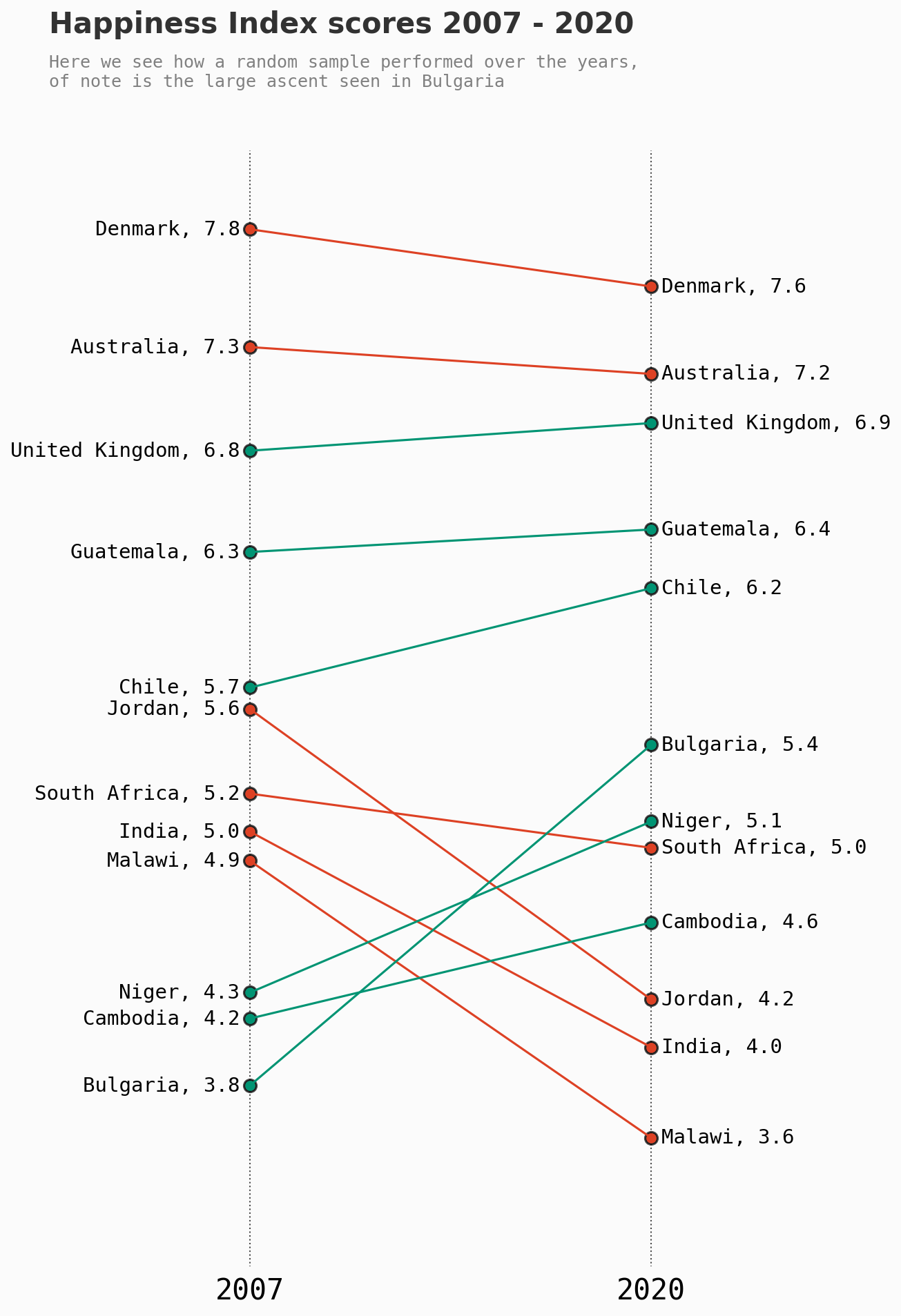
显然,多年来确实有很多变化。
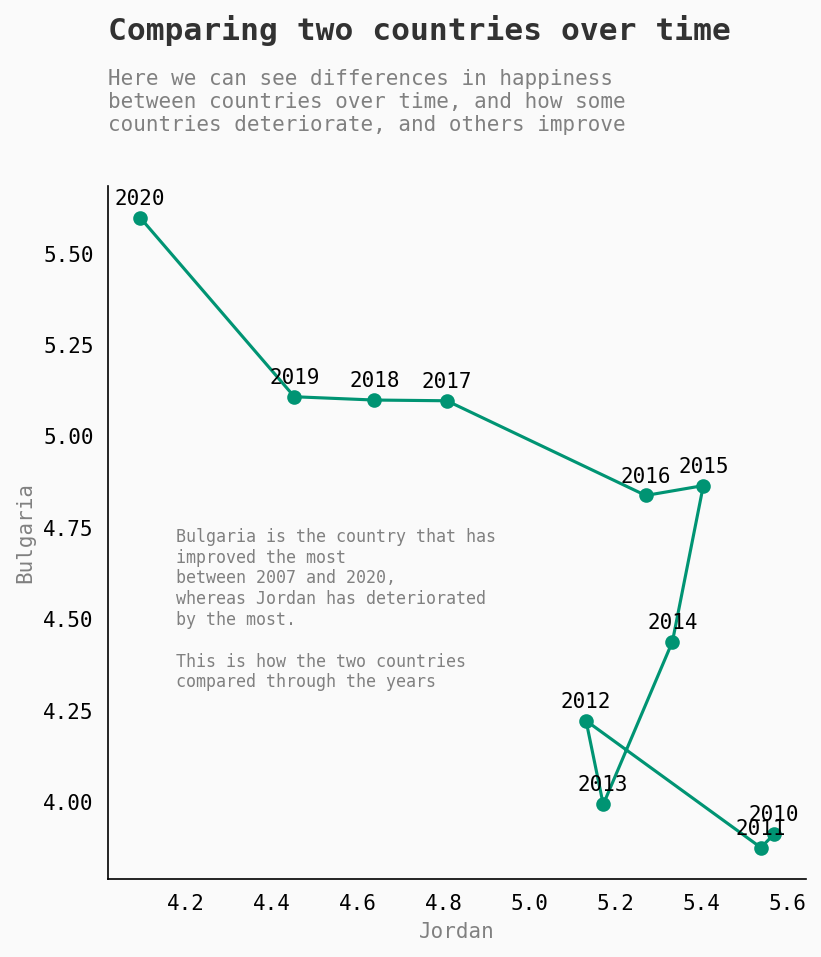
哪些国家经历了最大的变化?
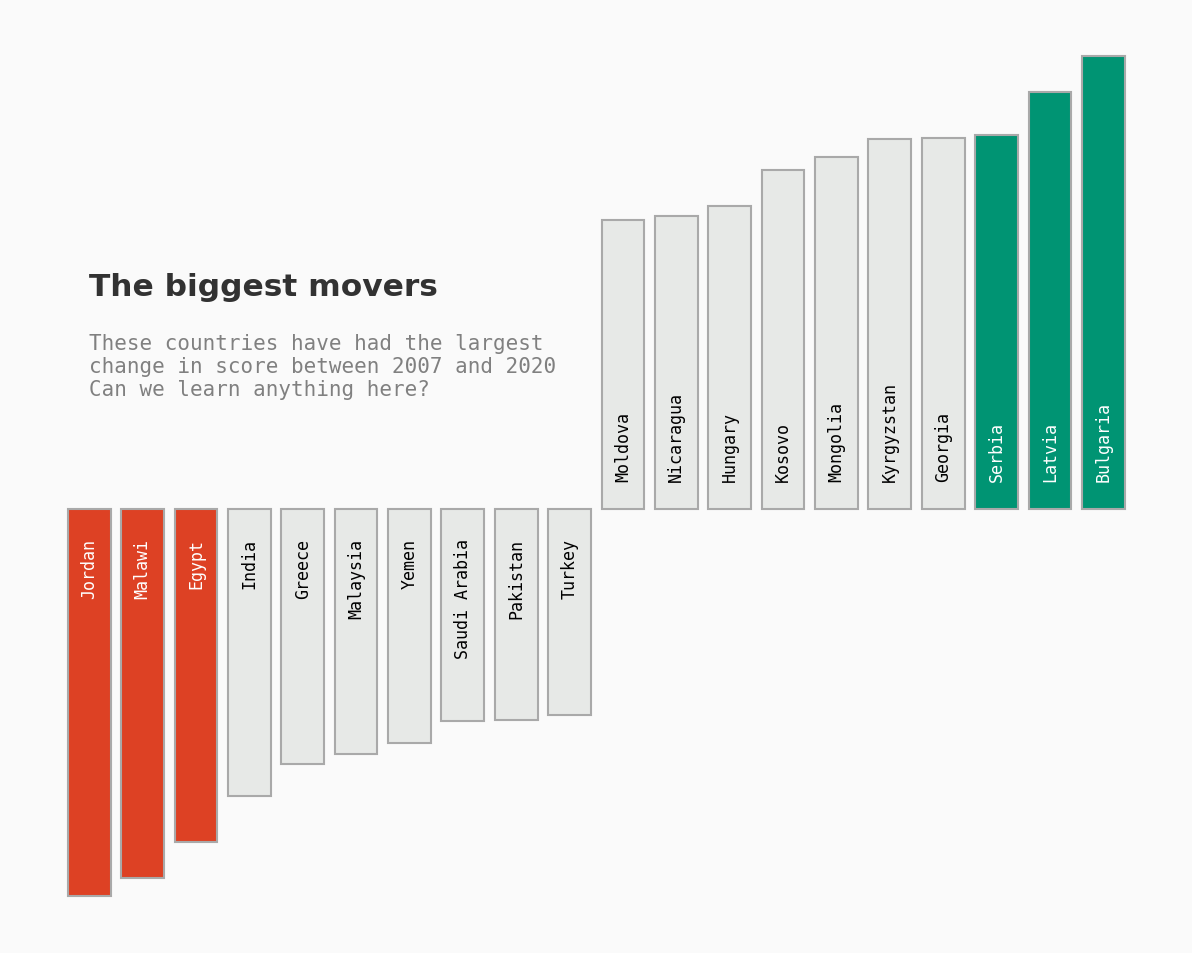
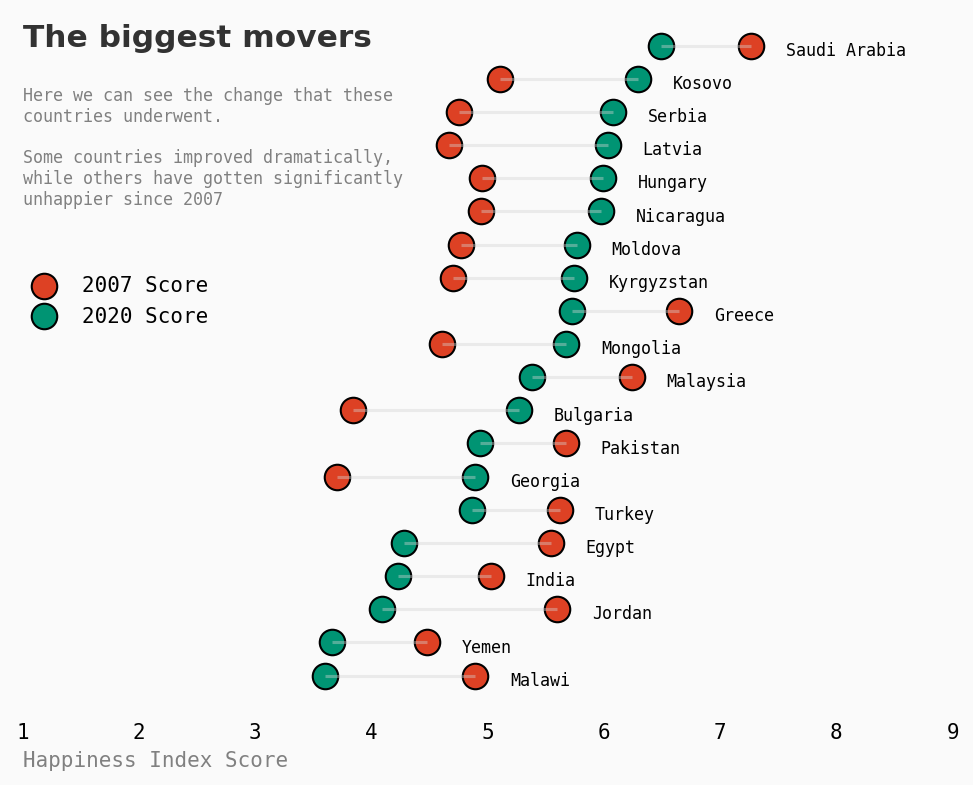
让我们比较在幸福指数得分方面增长最多和下降最多的两个国家:保加利亚和约旦。
我们将对比他们多年来的表现。
当我探究这个关于时间变化的观点时,我想从大陆的角度来看。
例如,西欧的所有国家都“幸福”吗?

