CSR数据多为非结构文本数据,可以做词频统计、情感分析、话题模型等文本分析任务。今天给大家奉上A股CSR数据集, 对文本分析感兴趣的同学, 欢迎报名视频课「Python实证指标构建与文本分析」。 本文仅展示A股企业社会责任数据集,并作简单分析。
一、CSR数据集
目前这是市面上最全最完整的原始数据,数据已整理到csv压缩文件(大小308M)。
「A股企业社会责任报告数据集」基本信息
- 记录数14845
- 沪深2383家公司
- 年度2006-2023
- 公布日期2007-03-14 ~ 2024-06-22
- txt、pdf、csv
声明
科研用途;如有问题, 请加微信372335839,备注「姓名-学校-专业」
二、相关文献
近年来,企业社会责任(csr)已成为全球学术界研究的热点,
[1]解学梅,朱琪玮.企业绿色创新实践如何破解“和谐共生”难题?[J].管理世界,2021,37(01):128-149+9.
[2]谢红军,吕雪.负责任的国际投资:ESG与中国OFDI[J].经济研究,2022,57(03):83-99.
[3]Schaefer, Sarah Desirée, Ralf Terlutter, and Sandra Diehl. "Is my company really doing good? Factors influencing employees' evaluation of the authenticity of their company's corporate social responsibility engagement." Journal of business research 101 (2019): 128-143.
三、实验
3.1 读取数据
import pandas as pd
df = pd.read_csv('CSR2006-2023.csv.gz', compression='gzip')
df
3.2 字段
CSR2006-2023.csv.gz 含字段
- code 股票代码
- name 公司简称
- year 会计年度
- pub_date 发布日期
- type 报告类型,
- 企业社会责任CSR
- 环境、社会及治理ESG、
- 可持续发展SD
- 环境报告书ENV;
报告可为某种类型,也可是多种类型的组合。
查看不同报告类型的记录数
df.type.value_counts()
Run
type
#CSR 11900
#ESG 1982
#SD 447
#CSR#ESG 232
#ENV 211
#ESG#SD 42
#CSR#SD 28
#SD#ESG 2
#CSR#ESG#SD 1
Name: count, dtype: int64
3.3 记录数
#ESG报告数
len(df)
Run
14845
#发布ESG报告的公司数
df.code.nunique()
Run
2383
3.4 会计年度
#有ESG报告的年份
#sorted(df['year'].unique())
sorted(df.year.unique())
Run
[2006,
2007,
2008,
2009,
2010,
2011,
2012,
2013,
2014,
2015,
2016,
2017,
2018,
2019,
2020,
2021,
2022,
2023]
3.5 发布日期
df['pub_date'] = pd.to_datetime(df['pub_date'], errors='coerce')
print(df['pub_date'].min())
print(df['pub_date'].max())
Run
2007-03-14 00:00:00
2024-06-22 00:00:00
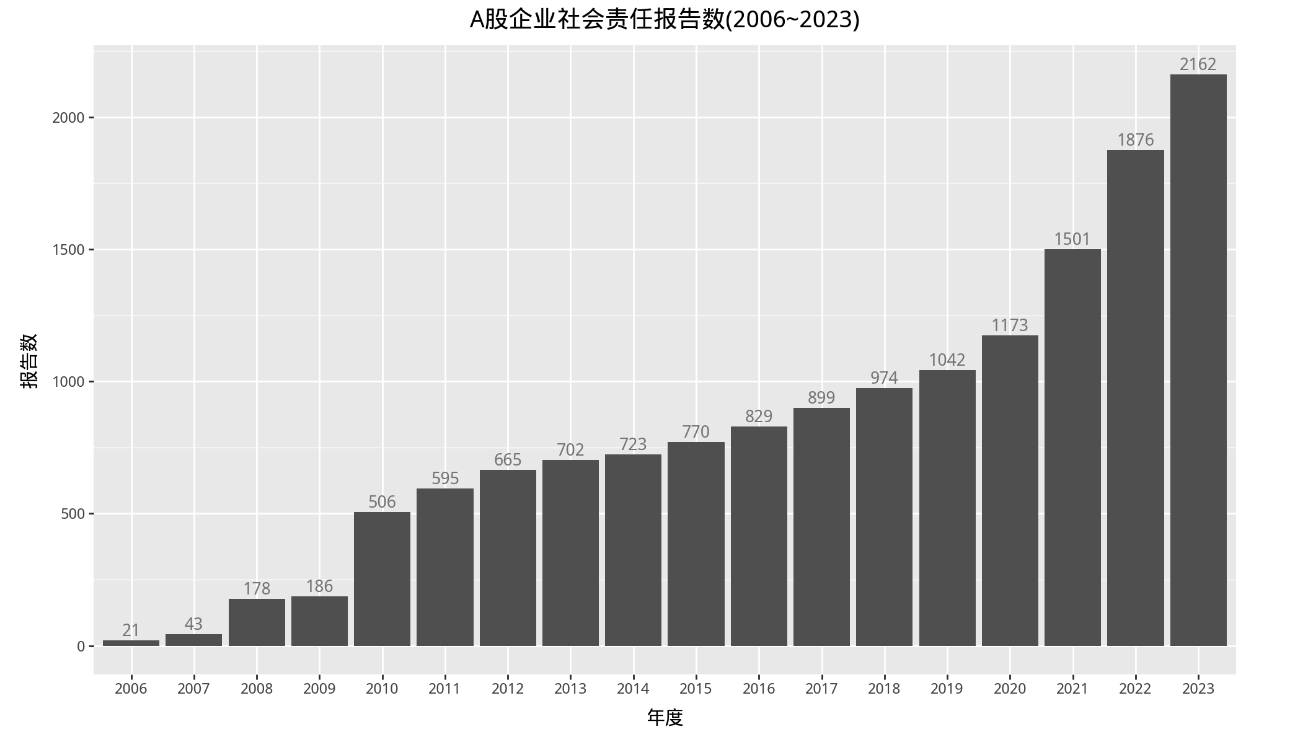
四、ESG年度发布量
from plotnine import *
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
#文泉驿微米黑.ttf位于代码同文件夹
font_prop = FontProperties(fname='文泉驿微米黑.ttf')
data = pd.DataFrame(df.groupby('year').apply(len).reset_index())
data.columns=['year', 'volume']
(
ggplot(data, aes(x='year', y='volume'))
+geom_col()
+geom_text(aes(label='volume'), data=data, va='bottom', color='grey', size=10)
+theme(figure_size=(10, 6),
text = element_text(family = font_prop.get_name()),
plot_title = element_text(family = font_prop.get_name(), size=14)
)
+labs(title='A股企业社会责任报告数(2006~2023)',
x = '年度',
y = '报告数')
)
五、沪深发布量
大邓记得深圳交易所大多数股票以0开头,上海交易所股票则大多以6开头。 可以简单通过第一位数字来判断两个交易所发布量
#切片,选取股票代码字符串第二个位置的数字
df['code'].str.slice(start=1, stop=2).value_counts()
Run
code
6 8339
0 5193
3 1265
8 19
9 17
2 10
4 2
Name: count, dtype: int64
运行结果,除了0和6还出现了2、3、9。综上,股票代码
-
0 深交所
-
3 创业板
-
6 上交所
-
其他
df[df['code'].str.startswith('A6')]
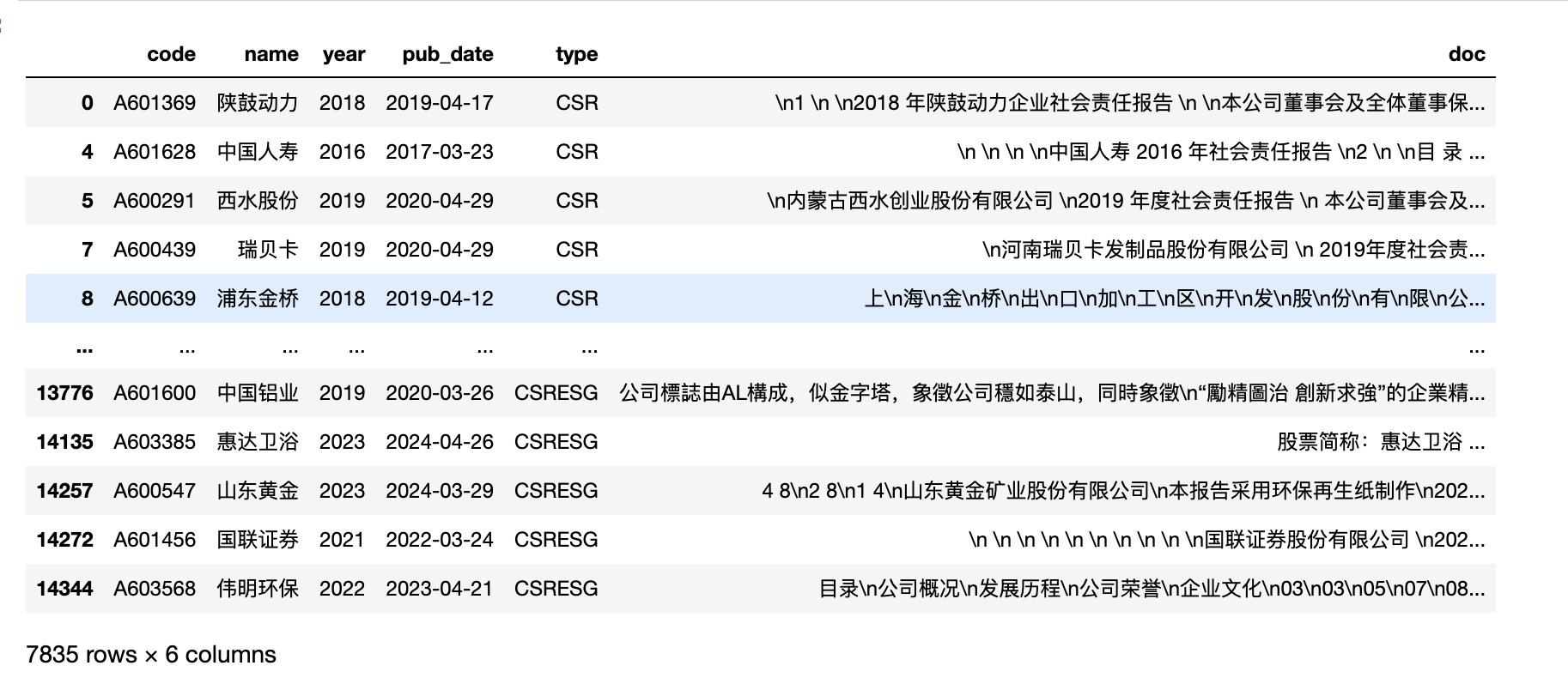
df[df['code'].str.startswith('A0')]
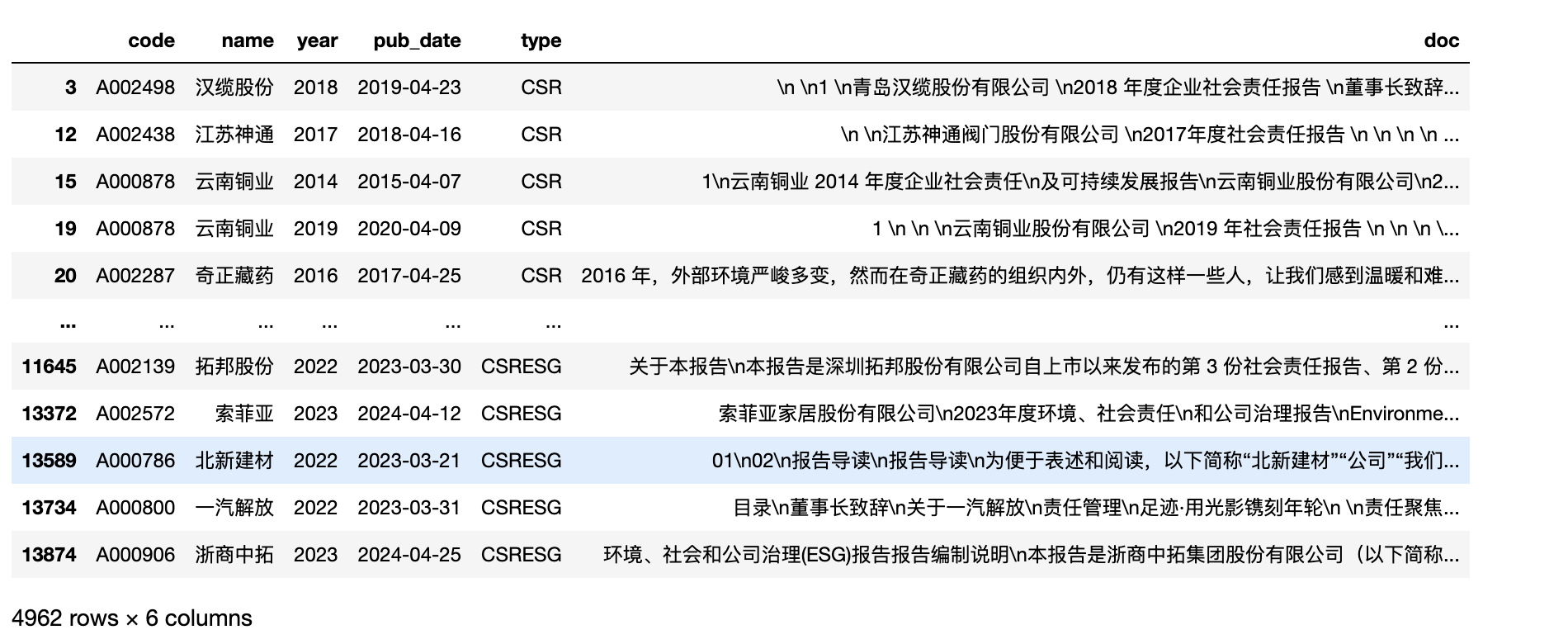
#股票代码第一位出现2或者9的股票
df[df['code'].str.match('A2|A9')]