
一、数据概况
数据集名: 上市公司高管违规-原始数据.xlsx
记录条数: 25365
覆盖日期: 1997-01-16 ~ 2022-12-28
为得到截图所示的高管违规次数.xlsx,实现步骤:
-
使用pd.read_excel()函数读取
- 高管违规数据集
上市公司高管违规-原始数据.xlsx - 股票代码列表
行业代码.xlsx
- 高管违规数据集
-
然后我们使用pd.merge()函数将两个数据集按照股票代码和年度进行合并,使用全连接(how=‘outer’)确保即使某些股票代码未出现在高管违规数据集中,也能保留在结果中。
-
接下来,我们使用groupby()函数按股票代码和年度进行分组,然后使用count()函数统计每个组的违规次数。
-
检查结果, 无误后导出xlsx。字段包括股票代码、年度和违规次数。
二、实现过程
2.1 导入数据
import pandas as pd
df1 = pd.read_excel('行业代码.xlsx', converters={'股票代码': str})
df1.head()
df2 = pd.read_excel('上市公司高管违规-原始数据.xlsx', converters={'股票代码': str})
df2['公告日期'] = pd.to_datetime(df2['公告日期'])
df2['会计年度'] = df2['公告日期'].dt.year
print(len(df2))
df2.head()
25365

2.2 合并
然后我们使用pd.merge()函数将两个数据集按照股票代码和年度进行合并,使用全连接(how=‘outer’)确保即使某些股票代码未出现在高管违规数据集中,也能保留在结果中。
df = pd.merge(df1, df2, how='outer', on=['股票代码', '会计年度'])
df.head()
2.3 分组Groupby
接下来,
- 使用groupby()函数按
股票代码和会计年度进行分组 - 然后使用count()函数统计每组次数
- 并将计算命名为
违规次数
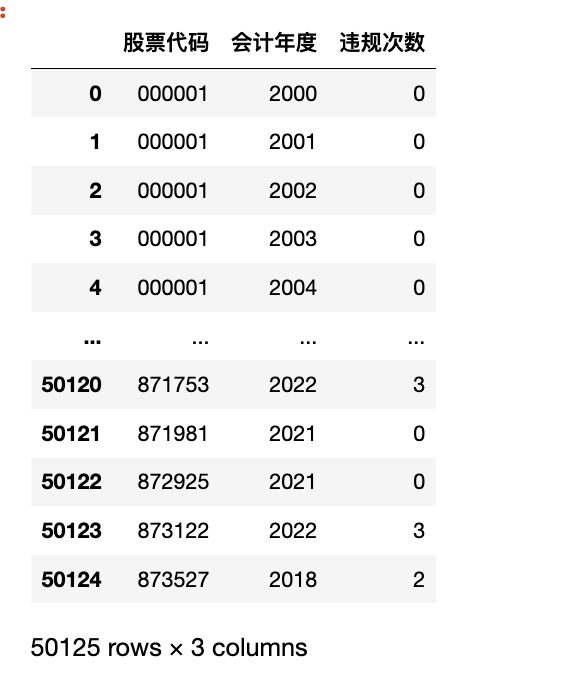
result_df = df.groupby(['股票代码', '会计年度'])['违规行为'].count().reset_index(name='违规次数')
result_df
2.4 检查&保存
检查结果, 无误后导出xlsx。字段包括股票代码、年度和违规次数。
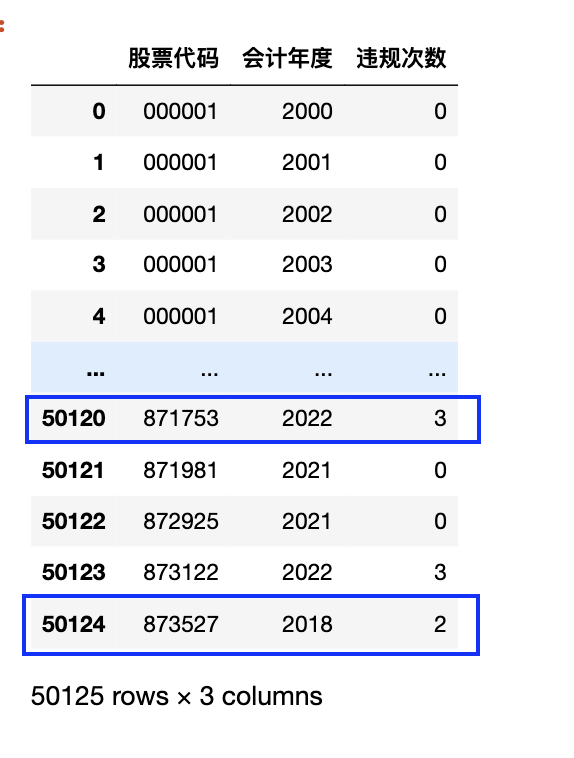
df2[(df2['股票代码']=='871753') & (df2['公告日期'].dt.year==2022)]

df2[(df2['股票代码']=='873527') & (df2['公告日期'].dt.year==2018)]

这里仅随机检查了两个记录(现实中要多检查几次), 与result_df中是一致的, 现在保存结果供后续实证分析
result_df.to_excel('高管违规次数.xlsx', index=False)
三、获取数据
链接: https://pan.baidu.com/s/1Ff2G8jRZaTtJH7VcfQGX5Q?pwd=npyf 提取码: npyf
