相关内容
昨日知乎热榜出现了一个话题「全职儿女不是啃老」,发现新闻对象主要集中于豆瓣小组, 咱们可以简单的爬一爬。

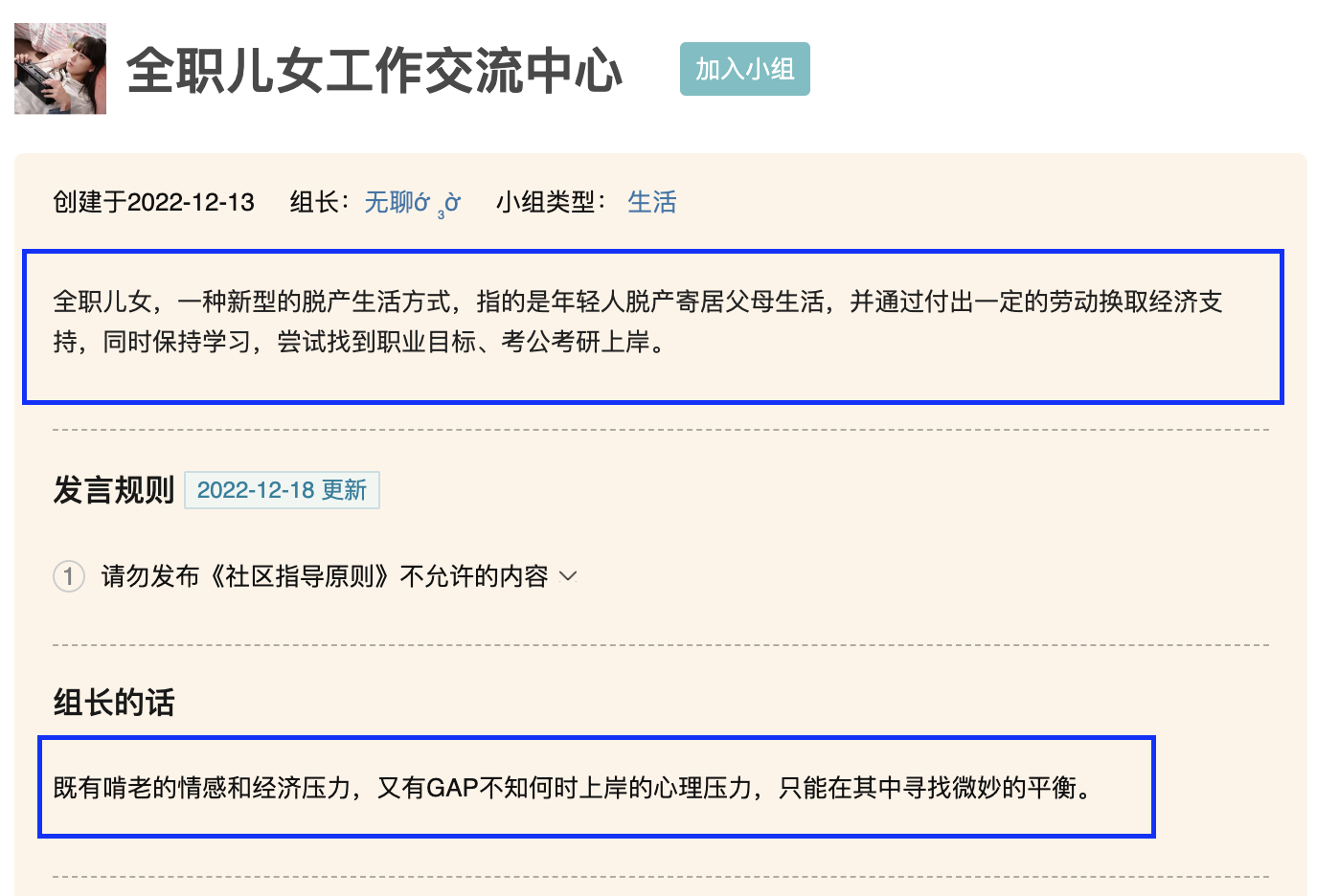
「全职儿女」,一种新型的脱产生活方式,指的是年轻人脱产寄居父母生活,并通过付出一定的劳动换取经济支持,同时保持学习,尝试找到职业目标……豆瓣小组“全职儿女工作交流中心”的小组介绍中这样写道。
一、寻找网址规律


点击很多个页面,最后发现网址规律
https://www.douban.com/group/{group_id}/members?start={offset}
其中
- group_id为小组的id
- offset 为36的倍数,随着页码的增加而增大
template = 'https://www.douban.com/group/{group_id}/members?start={offset}'
for page in range(1, 94):
url = template.format(group_id='735596', offset=(page-1)*36)
print(page, ' ', url)
Run
1 https://www.douban.com/group/735596/members?start=0
2 https://www.douban.com/group/735596/members?start=36
3 https://www.douban.com/group/735596/members?start=72
......
91 https://www.douban.com/group/735596/members?start=3240
92 https://www.douban.com/group/735596/members?start=3276
93 https://www.douban.com/group/735596/members?start=3312
二、访问测试
尝试对第一页进行方法,为了避免反爬, 访问时加入header伪装头。 最后检查第一页截图与resp.text内容对应上。如果一切顺利,即可定位数据。
import requests
header = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36'}
#group_id = '735596'
#url = template.format(group_id=group_id, offset=0)
url = 'https://www.douban.com/group/735596/members?start=0'
resp = requests.get(url, headers=header)
resp.text
Run
'<!DOCTYPE html>\n<html lang="zh-CN">\n<head>\n <meta http-equiv="Content-Type" content="text/html; charset=utf-8">\n <meta name="renderer" content="webkit">\n <meta name="referrer" content="always">\n <meta name="google-site-verification" content="ok0wCgT20tBBgo9_zat2iAcimtN4Ftf5ccsh092Xeyw" />\n <title>\n 全职儿女工作交流中心小组成员\n</title>\n \n \n <meta http-equiv="Pragma" content="no-cache">\n <meta http-equiv="Expires" content="Sun, 6 Mar 2005 01:00:00 GMT">\n class="pic">\n <a href="https://www.douban.com/people/meetyuan/" class="nbg">\n <img src="https://img9.doubanio.com/icon/up215413041-5.jpg" class="imgnoga" alt="无聊ớ ₃ờ" width="48px" height="48px"/>\n </a>\n </div>\n\n <div class="name">\n <a href="https://www.douban.com/people/meetyuan/" class="">无聊ớ ₃ờ</a>\n href="https://www.douban.com/people/139539208/" class="nbg">\n <img src="https://img2.doubanio.com/icon/up139539208-1.jpg" class="imgnoga" alt="Fortis817" width="48px" height="48px"/>\n </a>\n </div>\n\n <div class="name">\n <a href="https://www.douban.com/people/139539208/" class="">Fortis817</a>\n <br/>\n \n <span class="pl">(商丘)</span>\n </div>\n </li>\n \n \n <li class="member-item">\n <div class="pic">\n <a href="https://www.douban.com/people/caozhe1/" class="nbg">\n <img src="https://img1.doubanio.com/icon/up6807132-7.jpg" class="imgnoga" alt="泛思哲" width="48px" height="48px"/>\n </a>\n </div>\n\n <div class="name">\n <a href="https://www.douban.com/people/caozhe1/" class="">泛思哲</a>\n <br/>\n \n <span class="pl">(界首)</span>\n </div>\n </li>\n \n \n <li class="member-item">\n <div class="pic">\n <a href="https://www.douban.com/people/234804718/" class="nbg">\n <img src="https://img2.doubanio.com/icon/up234804718-1.jpg" class="imgnoga" alt="明月渡鴻影" width="48px" height="48px"/>\n </a>\n </div>\n\n <div class="name">\n <a href="https://www.douban.com/people/234804718/" class="">明月渡鴻影</a>\n <br/>\n \n <span class="pl"></span>\n </div>\n </li>\n \n \n <li class="member-item">\n <div class="pic">\n <a href="https://www.douban.com/people/138762699/" class="nbg">\n <img src="https://img2.doubanio.com/icon/up138762699-2.jpg" class="imgnoga" alt="火焰大地" width="48px" height="48px"/>\n </a>\n </div>\n\n <div class="name">\n <a href="https://www.douban.com/people/138762699/" class="">火焰大地</a>\n <br/>\n \n <span class="pl">(武汉)</span>\n </div>\n </li>\n \n \n <li class="member-item">\n <div class="pic">\n <a href="https://www.douban.com/people/73205393/" class="nbg">\n <img src="https://img2.doubanio.com/icon/up73205393-1.jpg"
......
三、 定位数据
使用pyquery定位数据, 保存用户昵称、主页链接、id、城市、头像。下图是对应关系和对应的定位pyquery选择器表达式。
pyquery比较难, 建议大家B站搜「大邓 Python网络爬虫快速入门」,有专门的章节讲pyquery。

from pyquery import PyQuery
doc = PyQuery(resp.text)
for item in doc.items('.member-item'):
data = {
'name': item('.name a').text(),
'link': item('.name a').attr('href'),
'id': item('.name a').attr('href').split('/')[-2],
'city': item('.name .pl').text().replace('(', '').replace(')', ''),
'avatar': item('.pic a img').attr('src'),
}
print(data)
Run
{'name': '无聊ớ ₃ờ', 'link': 'https://www.douban.com/people/meetyuan/', 'id': 'meetyuan', 'city': '重庆', 'avatar': 'https://img9.doubanio.com/icon/up215413041-5.jpg'}
{'name': '无聊ớ ₃ờ', 'link': 'https://www.douban.com/people/meetyuan/', 'id': 'meetyuan', 'city': '重庆', 'avatar': 'https://img9.doubanio.com/icon/up215413041-5.jpg'}
{'name': 'Fortis817', 'link': 'https://www.douban.com/people/139539208/', 'id': '139539208', 'city': '商丘', 'avatar': 'https://img2.doubanio.com/icon/up139539208-1.jpg'}
{'name': '泛思哲', 'link': 'https://www.douban.com/people/caozhe1/', 'id': 'caozhe1', 'city': '界首', 'avatar': 'https://img1.doubanio.com/icon/up6807132-7.jpg'}
......
{'name': '豆瓣zufang', 'link': 'https://www.douban.com/people/237754807/', 'id': '237754807', 'city': '', 'avatar': 'https://img2.doubanio.com/icon/up237754807-1.jpg'}
{'name': '豆友3giqV8i6EY', 'link': 'https://www.douban.com/people/250606383/', 'id': '250606383', 'city': '', 'avatar': 'https://img2.doubanio.com/icon/up250606383-1.jpg'}
{'name': 'momo', 'link': 'https://www.douban.com/people/254617952/', 'id': '254617952', 'city': '南京', 'avatar': 'https://img1.doubanio.com/icon/up254617952-8.jpg'}
四、存储数据
使用csv的字典写入方式,存储数据。
import csv
group_id = '735596'
with open(f'{group_id}.csv', 'w', newline='', encoding='utf-8') as csvf:
#定义csv内的字段
fieldnames = ['name', 'link', 'id', 'city', 'avatar']
writer = csv.DictWriter(csvf, fieldnames=fieldnames)
writer.writeheader()
doc = PyQuery(resp.text)
for item in doc.items('.member-item'):
data = {
'name': item('.name a').text(),
'link': item('.name a').attr('href'),
'id': item('.name a').attr('href').split('/')[-2],
'city': item('.name .pl').text().replace('(', '').replace(')', ''),
'avatar': item('.pic a img').attr('src'),
}
#逐行写入
writer.writerow(data)
五、汇总代码
将一、二、三、四等部分汇总合并,调整代码,既可以采集该豆瓣小组的信息。
import requests
import csv
import time
header = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36'}
template = 'https://www.douban.com/group/{group_id}/members?start={offset}'
group_id = '735596'
with open(f'{group_id}.csv', 'w', newline='', encoding='utf-8') as csvf:
#定义csv内的字段
fieldnames = ['name', 'link', 'id', 'city', 'avatar']
writer = csv.DictWriter(csvf, fieldnames=fieldnames)
writer.writeheader()
for page in range(1, 94):
print(f'正在采集page: {page} ')
time.sleep(1)
url = template.format(group_id=group_id, offset=(page-1)*36)
resp = requests.get(url, headers=header)
doc = PyQuery(resp.text)
for item in doc.items('.member-item'):
data = {
'name': item('.name a').text(),
'link': item('.name a').attr('href'),
'id': item('.name a').attr('href').split('/')[-2],
'city': item('.name .pl').text().replace('(', '').replace(')', ''),
'avatar': item('.pic a img').attr('src'),
}
#逐行写入
writer.writerow(data)
Run
正在采集page: 1
正在采集page: 2
正在采集page: 3
......
正在采集page: 91
正在采集page: 92
正在采集page: 93
六、欣赏结果
读取数据, 欣赏下结果。
import pandas as pd
df = pd.read_csv('735596.csv', encoding='utf-8')
print('小组成员数量: ', len(df))
df.head()
Run
记录数: 3317

df.city.value_counts(ascending=False)
Run
北京 235
上海 148
广州 78
深圳 61
南京 58
...
河池 1
Faroe Islands 1
Coventry 1
丽江 1
Warszawa 1
Name: city, Length: 275, dtype: int64
import matplotlib.pyplot as plt
import matplotlib
import matplotlib_inline
matplotlib_inline.backend_inline.set_matplotlib_formats('png', 'svg')
import scienceplots
import platform
plt.style.use(['science', 'no-latex', 'cjk-sc-font'])
system = platform.system() # 获取操作系统类型
if system == 'Windows':
font = {'family': 'SimHei'}
elif system == 'Darwin':
font = {'family': 'Arial Unicode MS'}
else:
font = {'family': 'sans-serif'}
matplotlib.rc('font', **font) # 设置全局字体
plt.figure(figsize=(12, 8))
df.city.value_counts(ascending=False)[:15].plot(kind='pie')

在饼形图中可以看到,全职儿女坐标主要集中于大城市。 需要注意, 豆瓣用户标注的地理位置,不一定体现现在所处的位置。
