
一、数据集
1.1 数据概况
数据集 | 2001-2024 年 A 股上市公司年报&管理层讨论与分析
数据名称: 2001-2024年A股上市公司年报&管理层讨论与分析
数据来源: 上海证券交易所、深圳证券交易所
数据格式: csv、txt
公司数量: 5706
MD&A数量: 65519
会计年度: 2001-2024
1.2 读取 md&a 数据
import pandas as pd
# 读取前5行数据
df = pd.read_csv('mda01-24.csv.gz', compression='gzip', nrows=5)
# gz解压后读取csv
# df = pd.read_csv('mda01-24.csv', nrows=5)
print(len(df))
df.head()
Run
65519

二、训练 Word2Vec & GloVe 模型
2.1 准备语料
从 mda01-24.csv.gz 数据中抽取出所有文本,写入到 mda01-24.txt
%%time
with open('mda01-24.txt', 'w', encoding='utf-8') as f:
text = '\n'.join(df['text'].fillna(''))
f.write(text)
最终得到 3.34G 的语料文件。
2.2 配置 cntext 环境
pip3 install cntext --upgrade
2.3 开始训练
%%time
%%time
import cntext as ct
w2v_model = ct.Word2Vec(corpus_file='mda01-24.txt', # 语料文件
lang='chinese', # 中文语料
vector_size=200, # 嵌入的维度数
window_size=15) # 词语上下文的窗口大小
glove_model = ct.GloVe(corpus_file='mda01-24.txt',
lang='chinese',
vector_size=200,
window_size=15)
Run
Mac(Linux) System, Enable Parallel Processing
Cache output/mda01-24_cache.txt Not Found or Empty, Preprocessing Corpus
Processing Corpus: 100%|█| 27404772/27404772 [04:38<00:00, 9
Reading Preprocessed Corpus from output/mda01-24_cache.txt
Start Training Word2Vec
Word2Vec Training Cost 1625 s.
Output Saved To: output/mda01-24-Word2Vec.200.15.bin
Mac(Linux) System, Enable Parallel Processing
Cache output/mda01-24_cache.txt Found, Skip Preprocessing Corpus
Start Training GloVe
BUILDING VOCABULARY
Using vocabulary of size 536863.
COUNTING COOCCURRENCES
Merging cooccurrence files: processed 353975745 lines.
Using random seed 1746091798
SHUFFLING COOCCURRENCES
Merging temp files: processed 353975745 lines.
TRAINING MODEL
Read 353975745 lines.
Using random seed 1746091864
05/01/25 - 05:32.08PM, iter: 001, cost: 0.115862
05/01/25 - 05:33.04PM, iter: 002, cost: 0.082325
05/01/25 - 05:34.00PM, iter: 003, cost: 0.070848
......
......
05/01/25 - 05:43.23PM, iter: 013, cost: 0.050617
05/01/25 - 05:44.19PM, iter: 014, cost: 0.050079
05/01/25 - 05:45.16PM, iter: 015, cost: 0.049582
GloVe Training Cost 1366 s.
Output Saved To: output/mda01-24-GloVe.200.15.bin
CPU times: user 1h 28min 19s, sys: 2min 6s, total: 1h 30min 26s
Wall time: 49min 55s
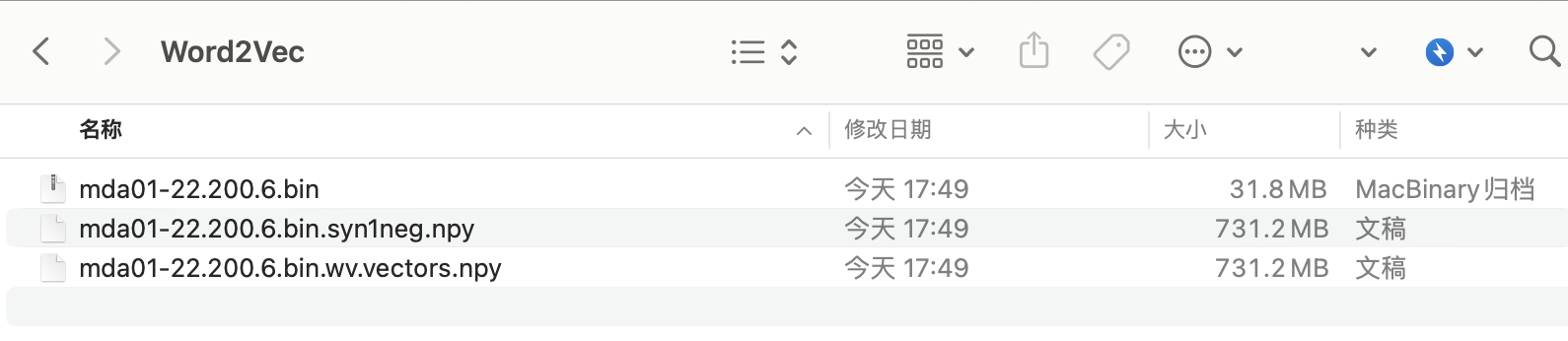
经过 1.5 小时, 训练出的中国 A 股管理层讨论与分析的 GloVe 和 Word2Vec 词向量模型(如下截图)。模型可广泛用于经济管理等领域概念(情感)词典的构建或扩展。
- mda01-24_cache.txt 缓存文件
- mda01-24-Word2Vec.200.15.bin Word2Vec 模型文件
- mda01-24-GloVe.200.15.bin GloVe 模型文件
三、使用模型
3.1 导入模型
使用 ct.load_w2v(w2v_path) 来导入刚刚训练好的模型 mda01-24-GloVe.200.15.bin
import cntext as ct
print(ct.__version__)
w2v_model = ct.load_w2v('output/mda01-24-Word2Vec.200.15.bin')
glove_model = ct.load_w2v('output/mda01-24-GloVe.200.15.bin')
w2v_model
Run
2.1.6
Loading output/mda01-24-Word2Vec.200.15.bin...
Loading output/mda01-24-GloVe.200.15.bin...
<gensim.models.keyedvectors.KeyedVectors at 0x633060fe0>
3.2 评估模型
使用近义法和类比法, 判断模型的表现。详情可查看文档
以 word2vec 为例,评估模型表现
ct.evaluate_similarity(w2v_model)
ct.evaluate_analogy(w2v_model)
Run
近义测试: similarity.txt
/Library/Frameworks/Python.framework/Versions/3.12/lib/python3.12/site-packages/cntext/model/evaluate_data/similarity.txt
评估结果:
+----------+------------+----------------------------+
| 发现词语 | 未发现词语 | Spearman's Rank Coeficient |
+----------+------------+----------------------------+
| 425 | 112 | 0.42 |
+----------+------------+----------------------------+
类比测试: analogy.txt
/Library/Frameworks/Python.framework/Versions/3.12/lib/python3.12/site-packages/cntext/model/evaluate_data/analogy.txt
Processing Analogy Test: 100%|██████████████| 1198/1198 [00:11<00:00, 99.91it/s]
评估结果:
+--------------------+----------+------------+------------+----------+
| Category | 发现词语 | 未发现词语 | 准确率 (%) | 平均排名 |
+--------------------+----------+------------+------------+----------+
| CapitalOfCountries | 455 | 222 | 31.21 | 4.30 |
| CityInProvince | 175 | 0 | 97.71 | 1.26 |
| FamilyRelationship | 90 | 182 | 10.00 | 5.89 |
| SocialScience | 9 | 61 | 44.44 | 4.50 |
+--------------------+----------+------------+------------+----------+
近义测试: Spearman’s Rank Coeficient 系数取值[-1, 1], 取值越大, 说明模型表现越好。
类比测试:
- CapitalOfCountries 中文 md&a 语料在此项表现较差, 应该是语料中常见国家首度的提及较少。也体现了大多数企业没有国际化。盲猜美股的 CapitalOfCountries 表现应该好于 A 股。
- CityInProvince 中文 md&a 语料在此项表现如此优异,说明 A 股多数企业扎根于中国大地, 年报 md&a 中提及次数很多。
- FamilyRelationship 中文 md&a 语料中主要体现的是公司组织层面,较少提及家庭关系词语,所以类别表现一般是很容易理解的。
- SocialScience 中文 md&a 语料在此项表现一般, 应该是语料中常见的社会科学词语提及较少。
整体而言,语料训练的效果很不错,抓住了数据场景的独特性语义。
3.3 KeyedVectors 的操作方法(或属性)
| 方法 | 描述 |
|---|---|
| KeyedVectors.index_to_key | 获取词汇表中的所有单词。 |
| KeyedVectors.key_to_index | 获取单词到索引的映射。 |
| KeyedVectors.vector_size | 获取 GloVe 模型中任意词向量的维度。 |
| KeyedVectors.get_vector(word) | 获取给定单词的词向量。 |
| KeyedVectors.similar_by_word(word, topn=10) | 获取某词语最相似的 10 个近义词。 |
| KeyedVectors.similar_by_vector(vector, topn=10) | 获取词向量最相似的 10 个近义词。 |
3.4 查看词汇量&维度数
# 词汇量
print('Word2Vec词汇量: ', len(w2v_model))
print('GloVe词汇量: ', len(glove_model))
print('Word2Vec维度数: ', w2v_model.vector_size)
print('GloVe维度数: ', glove_model.vector_size)
Run
Word2Vec词汇量: 902666
GloVe词汇量: 536864
Word2Vec维度数: 200
GloVe维度数: 200
3.5 词表
查看词表
w2v_model.index_to_key
Run
['公司',
'适用',
'情况',
'项目',
'产品',
...
'比上',
'境内',
'最终',
'启动',
...]
查看词汇映射表
w2v_model.key_to_index
Run
{'公司': 0,
'适用': 1,
'情况': 2,
'项目': 3,
'产品': 4,
......
'比上': 996,
'境内': 997,
'最终': 998,
'启动': 999,
...}
3.6 查看词向量
# 查询某词的词向量
w2v_model.get_vector('创新')
Run
array([ 2.2048666 , 1.7392347 , 3.8569732 , 2.181498 , 0.49182096,
-2.0054908 , 0.55133677, 0.97385484, 3.6563325 , -2.1495004 ,
-4.8804154 , 2.8375697 , 2.071349 , 3.0867636 , -1.3978149 ,
-0.38058507, -2.379905 , -1.8974878 , 3.596266 , 0.44742537,
......
0.13521506, -0.78970003, -0.8154422 , 1.015166 , 0.30753416,
-6.1991196 , -2.2295246 , 0.797445 , -0.21968505, 1.6549479 ,
-1.1522037 , -1.5377268 , -3.4639692 , -3.3877385 , 3.5285642 ,
0.9497059 , -2.6022844 , 1.6192312 , -0.39254257, -0.5094183 ],
dtype=float32)
# 查询多个词的词向量
w2v_model.get_mean_vector(['创新', '研发'])
Ruj
array([ 0.01322632, 0.01596442, 0.08699574, 0.06786569, 0.00441768,
-0.04059787, 0.01970061, 0.02050735, 0.04548474, -0.01610814,
-0.10554063, 0.08021796, 0.10255495, 0.06383747, -0.07158516,
0.00185056, -0.02854855, -0.09506228, 0.1032301 , -0.05448814,
......
-0.01035122, -0.02931183, -0.03785197, 0.04421834, 0.04357708,
-0.15989086, -0.05572033, 0.02324059, -0.08414906, 0.02760434,
0.01254621, -0.02324901, -0.05535778, -0.06064604, 0.0409652 ,
-0.04119795, -0.08222105, 0.03998823, -0.03626942, -0.01975589],
dtype=float32)
3.7 近义词
根据词语查找最相似的 10 个词
w2v_model.similar_by_word('创新', topn=10)
Run
[('技术创新', 0.6993309855461121),
('不断创新', 0.6758015155792236),
('创新型', 0.636788547039032),
('创新能力', 0.6053606271743774),
('引领', 0.604947566986084),
('硬核', 0.5690070986747742),
('前沿', 0.5627986788749695),
('赋能', 0.5582684278488159),
('创新性', 0.5509947538375854),
('革新', 0.5494255423545837)]
根据某词的词向量查询最相似的 10 个词
creativeness_vector = w2v_model.get_vector('创新')
w2v_model.similar_by_vector(creativeness_vector, topn=10)
Run
[('创新', 1.0),
('技术创新', 0.6993309855461121),
('不断创新', 0.6758015155792236),
('创新型', 0.636788547039032),
('创新能力', 0.6053606271743774),
('引领', 0.6049476265907288),
('硬核', 0.5690070986747742),
('前沿', 0.5627986788749695),
('赋能', 0.5582684278488159),
('创新性', 0.5509947538375854)]
多个词求得均值向量
AI_vector = w2v_model.get_mean_vector(['ai', '机器学习', '人工智能', '自然语言处理'])
w2v_model.similar_by_vector(AI_vector, topn=20)
Run
[('ai', 0.9074109792709351),
('机器学习', 0.8809980750083923),
('自然语言处理', 0.8750396966934204),
('ai模型', 0.8575210571289062),
('人工智能', 0.8506893515586853),
('nlp', 0.8240388035774231),
('语言模型', 0.8206671476364136),
('模态模型', 0.8144882917404175),
('深度学习', 0.7912176847457886),
('生成式', 0.7850476503372192),
('自然语言', 0.7846022248268127),
('llm', 0.7809537649154663),
('大模', 0.7670232653617859),
('gpt', 0.7638874053955078),
('自然语言理解', 0.7441188097000122),
('知识图谱', 0.7421959638595581),
('生成式ai', 0.7387682199478149),
('aigc', 0.7381091117858887),
('ai算法', 0.7311530709266663),
('语音识别', 0.7257674932479858)]
短视主义词
short_term_vector = w2v_model.get_mean_vector(['尽快', '年内', '马上'])
w2v_model.similar_by_vector(short_term_vector, topn=20)
Run
[('尽快', 0.7294592261314392),
('年内', 0.7279667854309082),
('尽早', 0.6742831468582153),
('马上', 0.6565427184104919),
('即将', 0.61030113697052),
('早日', 0.6024956107139587),
('争取早日', 0.5442042946815491),
('争取尽早', 0.5283723473548889),
('抓紧', 0.5254929661750793),
('争取', 0.5205905437469482),
('短时间', 0.5205082297325134),
('争取尽快', 0.5160724520683289),
('按期', 0.51212477684021),
('后续', 0.5105950236320496),
('力争早日', 0.5102716684341431),
('提前', 0.5060917139053345),
('力争', 0.4955942928791046),
('力争尽早', 0.4942554235458374),
('最后', 0.4882470369338989),
('立即', 0.4858567416667938)]
四、扩展词典
做词典法的文本分析,最重要的是有自己的领域词典。之前受限于技术难度,文科生的我也一直在用形容词的通用情感词典。现在依托 word2vec 技术, 可以加速人工构建的准确率和效率。
下面是在 mda01-24-Word2Vec.200.15.bin 上做的词典扩展测试,函数 ct.expand_dictionary(wv, seeddict, topn=100) 会根据种子词选取最准确的 topn 个词。
- wv 预训练模型,数据类型为 gensim.models.keyedvectors.KeyedVectors。
- seeddict 参数类似于种子词;格式为 PYTHON 字典;
- topn 返回 topn 个语义最接近 seeddict 的词,默认 100.
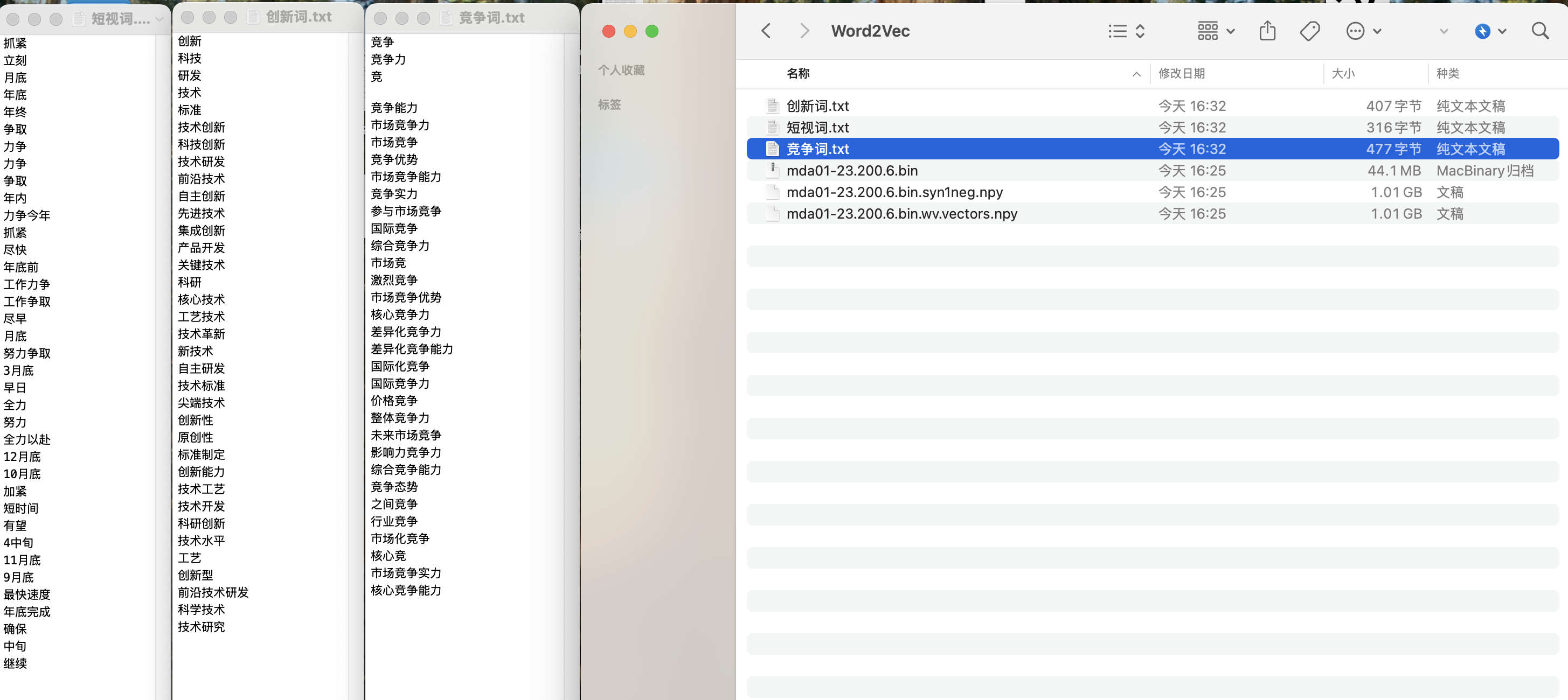
假设现在有种子词 seeddicts, 内含我构建的 短视词、 创新词、 竞争词, 我希望生成最终各含 30 个词的候选词表 txt 文件。
可以使用 ct.expand_dictionary 进行如下操作
seeddicts = {
'短视词': ['抓紧', '立刻', '月底', '年底', '年终', '争取', '力争'],
'创新词': ['创新', '科技', '研发', '技术', '标准'],
'竞争词': ['竞争', '竞争力'],
}
ct.expand_dictionary(wv = w2v_model,
seeddict = seeddicts,
topn=30)
Run
Finish! 短视词 candidates saved to output/短视词.txt
Finish! 创新词 candidates saved to output/创新词.txt
Finish! 竞争词 candidates saved to output/竞争词.txt
六、获取模型
内容创作不易, 本文为付费内容,
- 免费 mda01-24-Word2Vec.200.15.bin 链接: https://pan.baidu.com/s/1Gke4UKOnswpctp8vsZ0koQ?pwd=dpry
- 免费 mda01-24-GloVe.200.15.bin 链接: https://pan.baidu.com/s/1TqoA4TqMAhLzpIp0ZvrQEA?pwd=ajjw
- 更多免费词向量 https://cntext.readthedocs.io/zh-cn/latest/embeddings.html
相关内容
相关文献
[0]刘景江,郑畅然,洪永淼.机器学习如何赋能管理学研究?——国内外前沿综述和未来展望[J].管理世界,2023,39(09):191-216.
[1]冉雅璇,李志强,刘佳妮,张逸石.大数据时代下社会科学研究方法的拓展——基于词嵌入技术的文本分析的应用[J].南开管理评论:1-27.
[3]胡楠,薛付婧,王昊楠.管理者短视主义影响企业长期投资吗?——基于文本分析和机器学习[J].管理世界,2021,37(05):139-156+11+19-21.
[4]Kai Li, Feng Mai, Rui Shen, Xinyan Yan, Measuring Corporate Culture Using Machine Learning, *The Review of Financial Studies*,2020
- LIST | 社科(经管)文本挖掘文献汇总
- LIST | 文本分析代码汇总
- 词嵌入技术在社会科学领域进行数据挖掘常见 39 个 FAQ 汇总
- LIST | 可供社科(经管)领域使用的数据集
- Python 实证指标构建与文本分析
- 推荐 | 文本分析库 cntext2.x 使用手册
- 使用 5000w 专利申请数据集按年份(按省份)训练词向量
- 词向量 | 使用1985年-2025年专利申请摘要训练 Word2Vec 模型
- 词向量 | 使用人民网领导留言板语料训练 Word2Vec 模型
- 实验 | 使用 Stanford Glove 代码训练中文语料的 Glove 模型
- 可视化 | 人民日报语料反映七十年文化演变
