内容来源
整理自 https://www.kaggle.com/code/huzujun/xiaohongshu-data-mining/notebook
点击下载代码数据
安装相关库
!pip install dtreeviz==1.3.3
!pip install emoji
!pip install plotly
一、导入数据
点击下载数据 xiaohongshu.csv
import pandas as pd
import warnings
warnings.filterwarnings("ignore")
df = pd.read_csv('xiaohongshu.csv')
print(len(df))
df.head()

二、数据预处理
列是series类型数据, 使用apply方法(应用lambda函数)对列进行批处理。
这里可以做很多事情,例如
- desc的文本长度、表情数量
- title标题的长度
- 几点发文(24小时制的)
- …
import emoji
#desc中的表情数量
df['emoji_nums'] = df['desc'].apply(lambda desc: len(emoji.emoji_list(desc)))
#话题tag数量
df['hashTag_nums'] = df['desc'].str.count('#')
#标题title的文本长度
df['title_len'] = df['title'].str.len()
df['desc_len'] = df['desc'].str.len()
#几点发文
df['time'] = pd.to_datetime(df['time'], errors='coerce')
df['hours'] = df['time'].dt.hour
#把文本数字转为数值型数字
df['image_nums'] = df['image_nums'].astype('int')
df['liked_count'] = df['liked_count'].astype('int')
#显示前5行
df[['emoji_nums', 'hashTag_nums', 'title_len', 'desc_len', 'hours', 'image_nums', 'liked_count']].head()

三、数据分析
3.1 处理点赞数
看一下点赞数的数据分布
df.liked_count.describe()
Run
count 5928.000000
mean 157.174764
std 713.708655
min 0.000000
25% 2.000000
50% 15.000000
75% 69.000000
max 22265.000000
Name: liked_count, dtype: float64
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib
import platform
import matplotlib_inline
matplotlib_inline.backend_inline.set_matplotlib_formats('png', 'svg')
system = platform.system() # 获取操作系统类型
if system == 'Windows':
font = {'family': 'SimHei'}
elif system == 'Darwin':
font = {'family': 'Arial Unicode MS'}
else:
# 如果是其他系统,可以使用系统默认字体
font = {'family': 'sans-serif'}
matplotlib.rc('font', **font) # 设置全局字体
sns.distplot(df.liked_count)
plt.xlabel('点赞数')
plt.ylabel('分布')
plt.title('liked_count核密度分布图')

print(df.liked_count.min())
print(df.liked_count.median())
print(df.liked_count.max())
0
15.0
22265
这里可以看出一个问题,点赞数具有很强的长尾效应,也就是说一半的文章点赞数小于15,而热门的文章点赞数可以上千上万,因此如果直接分析点赞数的数值,用回归之类的算法去分析,一定是灾难,所以我们不妨简单处理,在这里我先人为定义点赞数>=50为热帖,其它的不是热帖,通过这个方式把笔记分成了两类
df["heat"] = pd.cut(df["liked_count"], bins=[-1, 50, 22266], labels=['凉帖', '热帖'])
3.2 分析热帖比例和小时的关系
import plotly
import plotly.graph_objs as go
plotly.offline.init_notebook_mode()
heats = []
for i in range(24):
hour_df = df[df['hours'] == i]
heats.append(len(hour_df[hour_df['heat'] == '热帖'])/len(hour_df))
layout = {'title': '24小时随时间热帖图'}
fig = go.Figure(data=[{'x': list(range(0, 24)), 'y': heats}], layout = layout)
plotly.offline.iplot(fig)

3.3 分析热帖比例和表情数的关系
df["emoji_nums"].describe()
Run
count 5928.000000
mean 6.824055
std 9.996283
min 0.000000
25% 0.000000
50% 3.000000
75% 10.000000
max 103.000000
Name: emoji_nums, dtype: float64
sns.distplot(df.emoji_nums)
plt.xlabel('表情数')
plt.ylabel('分布')
plt.title('emoji表情数核密度分布图')

import plotly.offline as py
import plotly.graph_objs as go
df["emoji_level"] = pd.cut(df["emoji_nums"], bins=[-1, 4, 90], labels=['表情少', '表情多'])
emoji_levels = []
for i in ['表情少', '表情多']:
emoji_df = df[df['emoji_level'] == i]
emoji_levels.append(len(emoji_df[emoji_df['heat'] == '热帖'])/len(emoji_df))
import plotly.express as px
colors = ['blue', 'red']
fig = go.Figure(data=[go.Bar(
x=['表情数<=4', '表情数>4'],
y=emoji_levels,
marker_color=colors # marker color can be a single color value or an iterable
)])
fig.update_layout(title_text='表情数-热帖占比')
plotly.offline.iplot(fig)

3.4 分析热帖比例和标签的关系
我原本以为的是“适当的标签最好,不是越多越好”,结果推翻了我的猜想
df["hashTag_nums"].describe([i/10 for i in range(1, 11)])
Run
count 5928.000000
mean 3.638327
std 4.077919
min 0.000000
10% 0.000000
20% 0.000000
30% 1.000000
40% 2.000000
50% 3.000000
60% 3.000000
70% 4.000000
80% 6.000000
90% 9.000000
100% 49.000000
max 49.000000
Name: hashTag_nums, dtype: float64
df["hashTags_level"] = pd.cut(df["hashTag_nums"], bins=[-1, 1, 2, 3, 4, 6, 9, 49], labels=[1, 2, 3, 4, 5, 6, 7])
emoji_levels = []
for i in range(1, 8):
con = df[df['hashTags_level'] == i]
emoji_levels.append(len(con[con['heat'] == '热帖'])/len(con))
import plotly.express as px
fig = go.Figure(data=[go.Bar(
x=['<= 1 hashTags', '1 < hashTags <= 2', '2 < hashTags <= 3', '3 < hashTags <= 4', '4 < hashTags <= 6',
'6 < hashTags <= 9', '9 < hashTags <= 49'],
y=emoji_levels, # marker color can be a single color value or an iterable
)])
fig.update_layout(title_text='话题数-热帖占比')
plotly.offline.iplot(fig)

df[df['hashTag_nums'] > 9].describe()

3.5 决策树模型
这里我们尝试用这些因子去预测帖子是否热门,我挑选的是决策树,虽然别的模型可能会搞出几个百分点的准确率,但是必要性不是很大,在这里我更想要看到可解释性强的结果,而不是黑盒模型,这是决策数的优点,因为预测是否热帖这个事情不是我们的目的。
df['liked_count'].describe()
Run
count 5928.000000
mean 157.174764
std 713.708655
min 0.000000
25% 2.000000
50% 15.000000
75% 69.000000
max 22265.000000
Name: liked_count, dtype: float64
决策树模型要求种类要平衡,这里有两种解决方法:
- 对不平衡的种类重新取样
- 这里因为数据本来就不算很多,我就人为重新定义了中位数作为热帖的分水岭
df["heat"] = pd.cut(df["liked_count"], bins=[-1, 15, 22266], labels=[1, 2])
print(len(df[df["heat"] == 1]), len(df[df["heat"] == 2]))
2982 2946
决策树模型根据尝试,在最大深度为3时近似就能取到很好的准确率了
from sklearn.preprocessing import StandardScaler
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
df["heat"] = pd.cut(df["liked_count"], bins=[-1, 15, 22266], labels=[1, 2])
df["emoji_level"] = pd.cut(df["emoji_nums"], bins=[-1, 4, 90], labels=[1, 2])
cols = ['image_nums', 'desc_len', 'title_len', 'hashTags_level' ,'emoji_level', 'hours']
X = df[cols]
scaler = StandardScaler()
scaler.fit(X)
X = scaler.transform(X)
y = df['heat']
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
print(len(X_train), len(y_test))
clf = DecisionTreeClassifier(max_depth = 3)
clf.fit(X_train, y_train)
print(accuracy_score(clf.predict(X_test), y_test))
4446 1482
0.699055330634278
70%的准确率意味着比乱猜的50%要好不少,在我们完全没有去关注帖子内容,仅仅只根据图片数、文本长度来预测是否热帖已经有这个准确率,已经是非常好了。
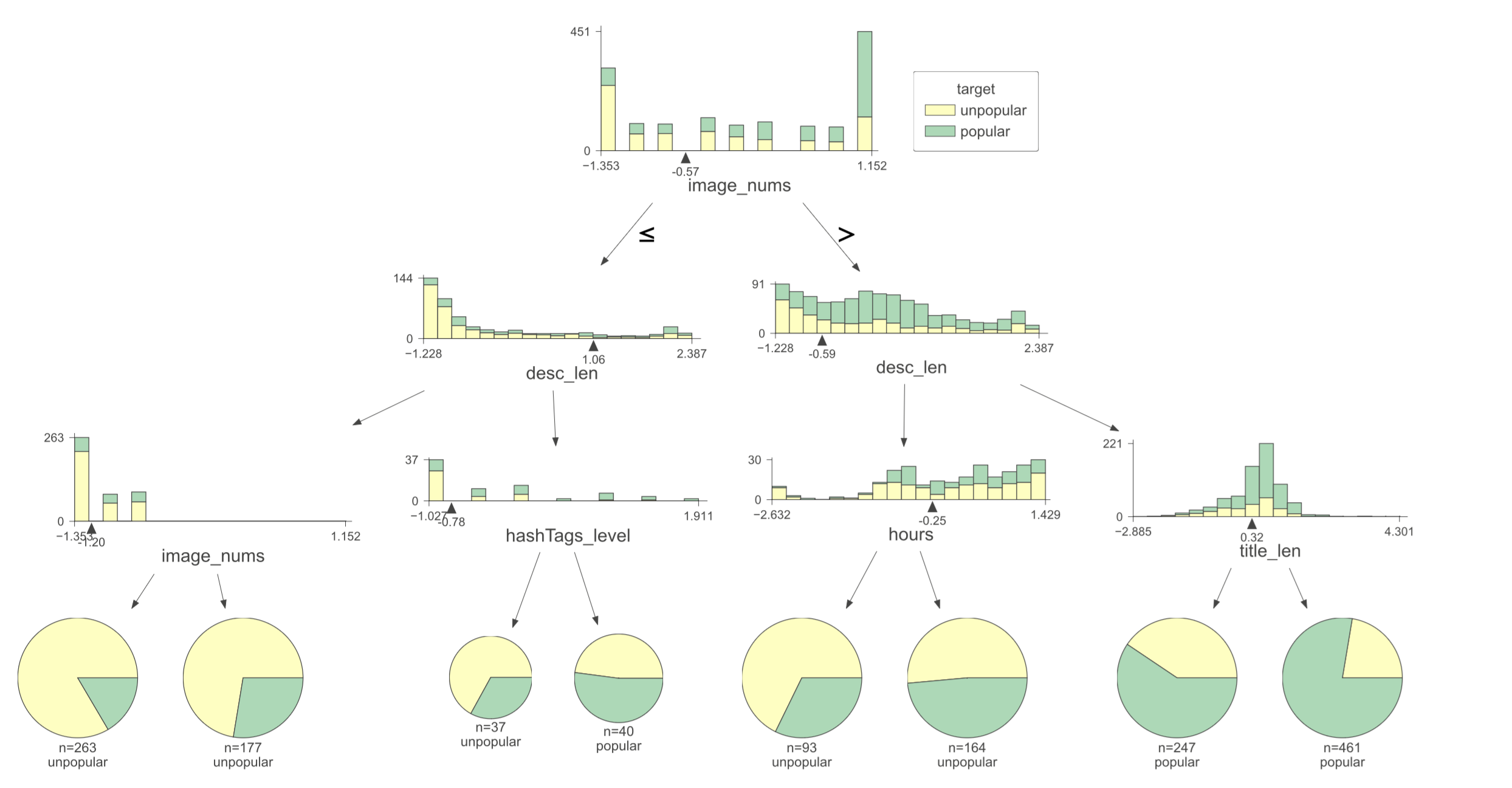
我们可视化决策树
from dtreeviz.trees import dtreeviz # remember to load the package
viz = dtreeviz(clf, X_test, y_test,
target_name="target",
feature_names=cols,
class_names=['unpopular', 'popular'])
viz.save("viz.svg")
viz

可视化决策树的结论:一般来说,越多的图片、越长的标题、越长的正文能显著获得更高的热贴机会,这是根据决策树的结果得到的。不过如果图片和标题信息量足够了,正文不用特别长也可以了。
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
forest = RandomForestClassifier(random_state=888, max_depth = 4)
forest.fit(X_train, y_train)
print(accuracy_score(forest.predict(X_test), y_test))
0.7031039136302294
import matplotlib.pyplot as plt
from sklearn.inspection import permutation_importance
result = permutation_importance(forest, X_test, y_test,
n_repeats=10, random_state=42, n_jobs=2)
forest_importances = pd.Series(result.importances_mean, index=col)
fig, ax = plt.subplots()
forest_importances.plot.bar(yerr=result.importances_std, ax=ax)
ax.set_title("模型中特征重要性排序")
ax.set_ylabel("平均精度下降")
fig.tight_layout()
plt.show()

