使用R语言绘制文本数据情感历时趋势图, 实现步骤
- 导入数据、
- 保留涉及政府的内容; 确定政府关键词,保留政府关键词出现位置窗口距离内的所有词语
- 情感计算,使用LSD2015中的正、负两类词表, 统计正、负情感词出现次数
- 绘制出卫报中涉及政府情感的历时可视化图
1. 导入数据
该语料库包含 2012 年至 2016 年的 6,000 篇卫报新闻文章。
library(quanteda)
library(quanteda.corpora)
corp_news <- readRDS("data/data_corpus_guardian.RDS")
2. 保留涉及政府的内容
确定政府关键词,保留政府关键词出现位置窗口距离内的所有词语
# 分词
toks_news <- tokens(corp_news, remove_punct = TRUE)
#政府相关词
gov <- c("government", "cabinet", "prime minister")
# 政府gov词出现位置前后10个词都保留
# note: 使用 phrase() 构建词组
toks_gov <- tokens_keep(toks_news, pattern = phrase(gov), window = 10)
3. 情感计算
使用 data_dictionary_LSD2015 情感词典
lengths(data_dictionary_LSD2015)
Run
negative positive neg_positive neg_negative
2858 1709 1721 2860
data_dictionary_LSD2015词典中有四个词表,只使用前两个,即 negative 和 positive
# 只使用 negative 和 positive
data_dictionary_LSD2015_pos_neg <- data_dictionary_LSD2015[1:2]
# toks_gov中属于positive词表的词语出现几次, positive就是几;同理,negative;
toks_gov_lsd <- tokens_lookup(toks_gov,
dictionary = data_dictionary_LSD2015_pos_neg)
# 构建文档特征矩阵, 并将date进行分组
dfmat_gov_lsd <- dfm(toks_gov_lsd) %>%
dfm_group(groups = date)
dfmat_gov_lsd
Run
Document-feature matrix of: 1,453 documents, 2 features (36.89% sparse) and 3 docvars.
features
docs negative positive
2012-01-02 2 0
2012-01-04 0 0
2012-01-05 0 1
2012-01-06 0 0
2012-01-07 1 0
2012-01-11 4 4
[ reached max_ndoc ... 1,447 more documents ]
4. 可视化
图表详情
- x轴日期
- y轴词频
- 图中的柱为每天中的正、负词出现次数
由此绘制出卫报中涉及政府情感的历时可视化图。
matplot(dfmat_gov_lsd$date, dfmat_gov_lsd, type = "l", lty = 1, col = 1:2,
ylab = "Frequency", xlab = "")
grid()
legend("topleft", col = 1:2, legend = colnames(dfmat_gov_lsd), lty = 1, bg = "white")
通过获取正面词和负面词的频率之间的差异来计算每日情绪分数。
plot(dfmat_gov_lsd$date, dfmat_gov_lsd[,"positive"] - dfmat_gov_lsd[,"negative"],
type = "l", ylab = "Sentiment", xlab = "")
grid()
abline(h = 0, lty = 2)
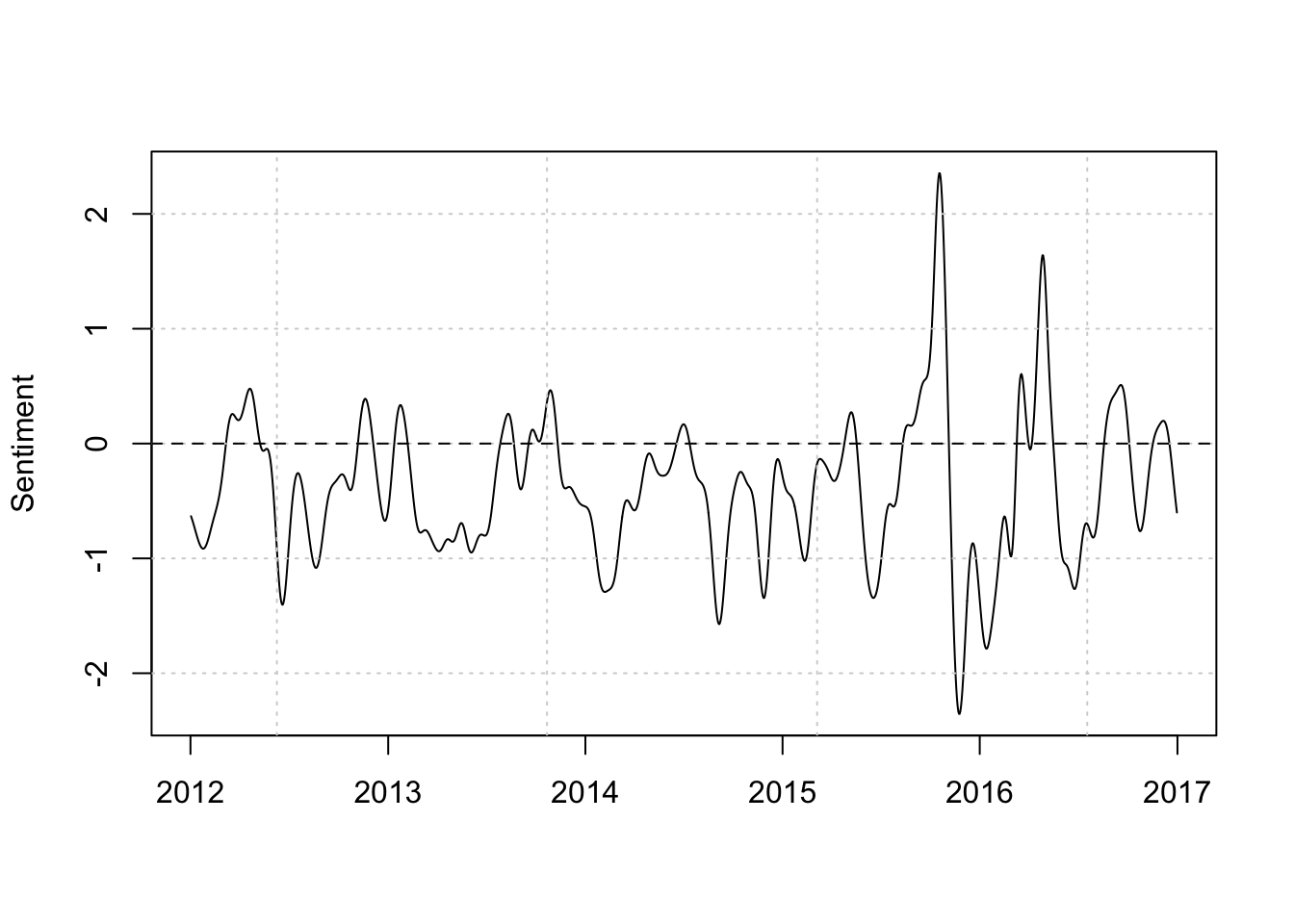
上面两幅图太粗糙了, 可以应用内核平滑处理下情感值,更清楚地显示卫报中涉及政府的情感变化趋势。
dat_smooth <- ksmooth(x = dfmat_gov_lsd$date,
y = dfmat_gov_lsd[,"positive"] - dfmat_gov_lsd[,"negative"],
kernel = "normal", bandwidth = 30)
plot(dat_smooth$x, dat_smooth$y, type = "l", ylab = "Sentiment", xlab = "")
grid()
abline(h = 0, lty = 2)
