
今日分享「信息含量」的第二种算法, 不同于之前 中国工业经济 | MD&A信息含量指标构建代码实现 , 金日分享的「信息含量」算法更简单易懂,运行速度更快。
一、信息含量
1.1 文献
宋建波,冯晓晴.关键审计事项信息含量与公司债券发行定价——基于文本相似度视角[J].会计研究,2022,(03):174-191.

1.2 信息的分类
- 标准信息,将关键审计事项段中与同行业其他公司重复或相似的信息定义为不具有信息含量的内容 ( 标准信息)。
- 特质性信息 将区别于同行业其他公司的信息定义为真正具有信息含量的内容 ( 特质性信息) 。 与标准信息相比, 特质性信息才是缓解公司与投资者之间信息不对称的关键。
二、算法
该文基于 向量空间模型 (VSM) , 采用某家公司关键审计事项文本内容与同行业其他公司关键审计事项文本内容之间的余弦相似度来衡量关键审计事项的特质性信息含量。
要测量信息含量的数学表达大概这样
-
文本向量化。
- 使用TF-IDF将公司审计文本向量化 Corp_Vec_it
- 公司所在行业众多的 Corp_Vec_jt 的均值向量 Industry_Vec_t 。注意计算均值向量时要剔除概公司。
-
余弦相似度cosine(Corp_Vec_it, Industry_Vec_t)
-
信息含量 = -cosine(Corp_Vec_it, Industry_Vec_t)
三、代码实现
3.1 文件结构
- 金融研究2023信息含量文件夹
- 代码.ipynb #代码文件
- data #数据文件夹
- mda01-23.csv.gz #md&a
- 上市公司基本信息2000-2023.xlsx #股票行业信息
- 关键审计-信息含量01-23.csv #计算结果
3.2 读取数据
原文数据描述
对于全部 A 股公司而言,新准则要求在针对 2017 财年 会计报表的审计报告中首次包含关键审计事项。 由于针对 2017 财年会计报表的审计报告于 2018 年发布, 债券投资者在 2018 年方能获取 2017 财年的关键审计事项信息, 进而在 2018 年进行债券投资时考虑关键审计事项信息。 因此,本文实证检验 2017-2018 会计年度审计报告中的关键审计事项信息对 2018-2019 年度非金融业上市公司发行的 357 只公司债券定价的影响。 关键审计事项信息含量数据通过 Python 编程语言进行文本分析计算得到; 公司债券限制性契约条款数据通过手工整理得到; 其他数据来自于 CSMAR 数据库。所有连续变量均进行 1%和 99%分位数的缩尾处理。
大邓这里没有「审计报告文本」数据集, 用「管理层讨论与分析」代替。
%%time
import pandas as pd
#读取md&a
df = pd.read_csv('data/mda01-23.csv.gz', compression='gzip')
df.columns = ['会计年度', '股票代码', '经营讨论与分析内容']
df['会计年度'] = df['会计年度'].astype(str)
#上市公司行业信息
ind_info_df = pd.read_excel('data/上市公司基本信息2000-2023.xlsx', usecols=['Symbol', 'EndDate', 'IndustryCodeC', 'ShortName'])
ind_info_df = ind_info_df[ind_info_df.Symbol!='股票代码']
ind_info_df['会计年度'] = ind_info_df.EndDate.fillna('').apply(lambda date: date[:4])
ind_info_df.rename(columns={'Symbol': '股票代码', 'IndustryCodeC':'行业代码', 'ShortName': '股票简称'}, inplace=True)
ind_info_df = ind_info_df[['股票代码', '会计年度', '行业代码', '股票简称']]
#合并数据
df = pd.merge(df, ind_info_df, on=['股票代码', '会计年度'], how='inner')
# 剔除金融行业处理
df = df[~df['行业代码'].str.contains("J")]
df['会计年度'] = df['会计年度'].astype(str)
#行业内企业数量过少,会导致行业向量与某个或某几个企业向量相关性增大,极端情况下,一个企业就是一个行业。剔除掉企业数较少的行业,这里只保留大于20的行业。
ind_codes = df['行业代码'].value_counts()
ind_codes = ind_codes[ind_codes>20].index
df = df[df['行业代码'].isin(ind_codes)]
df

3.3 文本向量化
使用sklearn,将该企业文本(审计报告文本)转为TF-IDF的企业向量。步骤
- 分词整理
tf-idf文本向量化- 合并多个字段为新的df
%%time
import jieba
import re
import cntext as ct
#cntext1.9.2
#stopwords = ct.load_pkl_dict('STOPWORDS.pkl')['STOPWORDS']['chinese']
##cntext2.1.7
stopwords= ct.read_yaml_dict('enzh_common_StopWords.yaml')['Dictionary']['chinese']
def transform(text):
#只保留md&a中的中文内容
text = ''.join(re.findall('[\u4e00-\u9fa5]+', text))
#剔除停用词
words = [w for w in jieba.cut(text) if w not in stopwords]
#整理为用空格间隔的字符串(类西方语言文本格式)
return ' '.join(words)
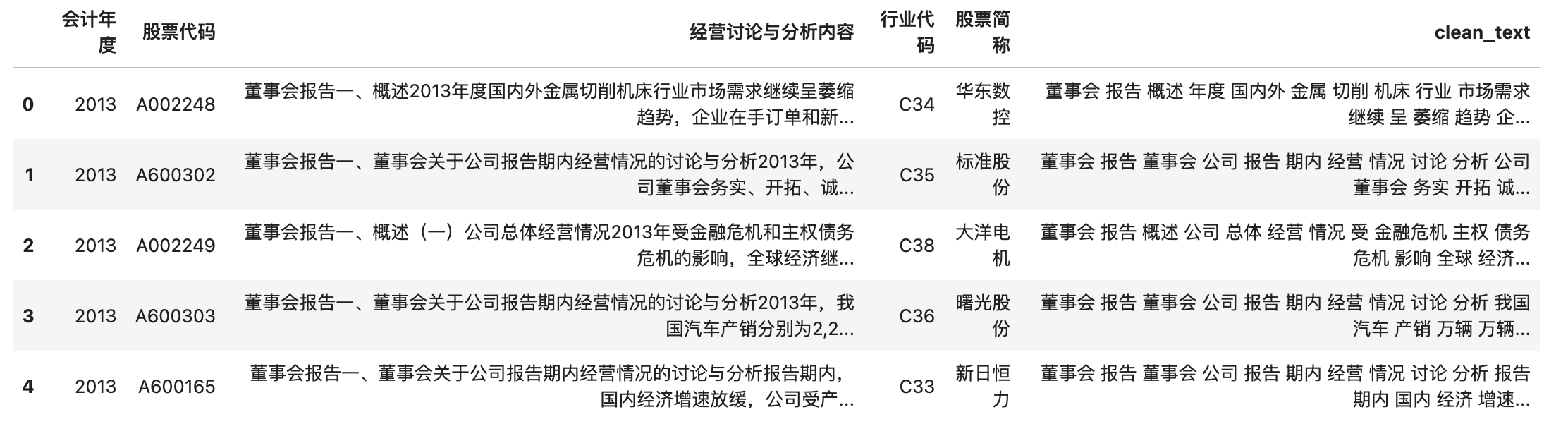
df['clean_text'] = df['经营讨论与分析内容'].apply(transform)
df.head()
Run
CPU times: user 54min 3s, sys: 56.4 s, total: 54min 59s
Wall time: 55min 16s
%%time
from sklearn.feature_extraction.text import TfidfVectorizer
cv = TfidfVectorizer(min_df=0.05, max_df=0.5)
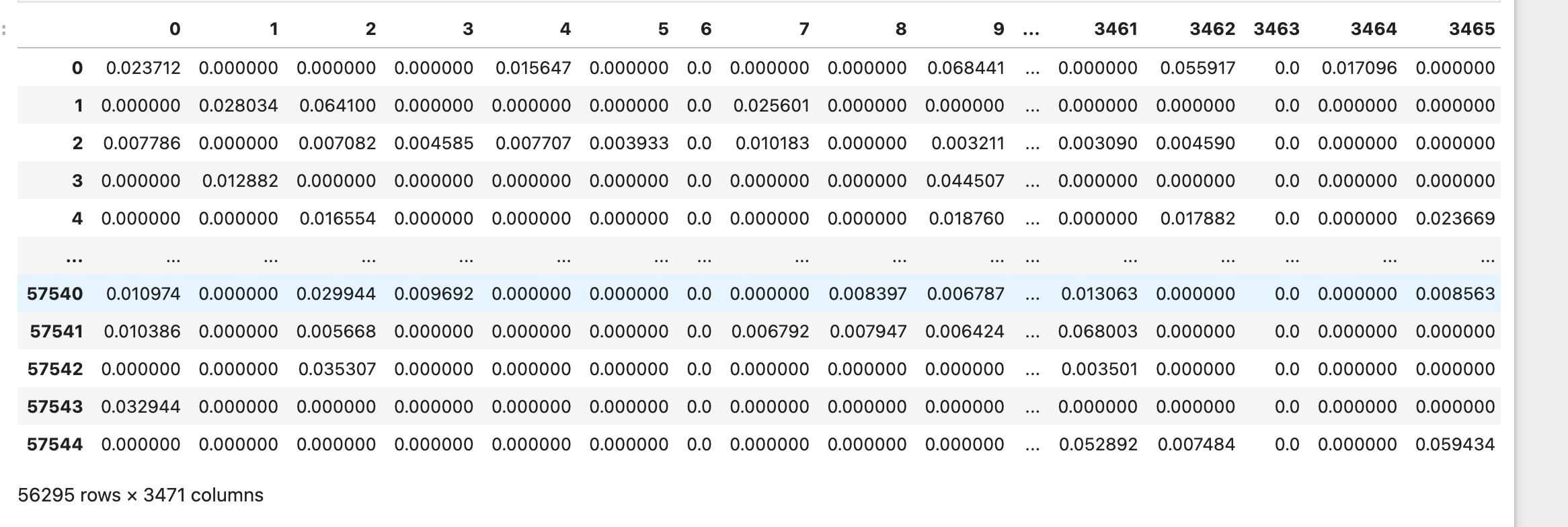
# 生成稀疏bow矩阵
#dtm 文档-词频-矩阵
dtm_df = cv.fit_transform(df['clean_text'])
#保证新生成的dtm_df2.index 与 df2.index 完全相同
dtm_df = pd.DataFrame(dtm_df.toarray(), index=df.index)
dtm_df
Run
CPU times: user 1min 2s, sys: 1.5 s, total: 1min 4s
Wall time: 1min 4s
3.6 小实验
指定某年份,某公司,某行业, 尝试着分别得到公司向量、行业向量、信息含量。
-
使用TF-IDF将公司审计文本向量化 Corp_Vec_it
-
公司所在行业众多的 Corp_Vec_jt 的均值向量 Industry_Vec_t 。注意计算均值向量时要剔除概公司。
-
余弦相似度cosine(Corp_Vec_it, Industry_Vec_t)
-
信息含量 = -cosine(Corp_Vec_it, Industry_Vec_t)
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
#小实验
year = '2023'
ind = 'K70'
code = 'A000002'
#筛选条件
year_mask = df['会计年度']==year
ind_mask = df['行业代码']==ind
corp_mask = df['股票代码']==code
#提取公司向量
selected_corp_index = df[year_mask & ind_mask & corp_mask].index
corp_vec = dtm_df[dtm_df.index.isin(selected_corp_index)].values
corp_arr = np.array(corp_vec)
print('公司向量: ', corp_arr)
#计算行业均值向量
selected_ind_df = df[ind_mask & year_mask]
selected_indexs = selected_ind_df[selected_ind_df['股票代码']!=code].index
ind_vec = dtm_df[dtm_df.index.isin(selected_indexs)].mean(axis=0).values
ind_arr = np.array([ind_vec])
print('公司向量: ', corp_arr)
#计算信息含量
special_info = -1 * cosine_similarity(corp_arr, ind_arr)[0][0]
print('信息含量: ', special_info)
Run
公司向量: [[0. 0.01495101 0.00455808 ... 0. 0. 0. ]]
公司向量: [[0. 0.01495101 0.00455808 ... 0. 0. 0. ]]
信息含量: -0.5683186993629404
2.5 批量计算信息含量
- 新建 信息含量.csv , 含字段
['股票代码', '会计年度', '行业代码', '信息含量'] - 先按年份对 df 进行分组,得到很多个 y_df;而 y_df 含一年很多条企业mda记录
- 双层 for循环逐年(y_df)内每条企业mda记录, 构建公司向量、行业向量、信息含量
- 将相关计算结果写入到csv中。
%%time
import time
import csv
import pandas as pd
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
from tqdm import tqdm
with open('关键审计-信息含量01-23.csv', 'w', newline='', encoding='utf-8') as csvf:
fieldnames = ['股票代码', '会计年度', '行业代码', '信息含量']
writer = csv.DictWriter(csvf, fieldnames=fieldnames)
writer.writeheader()
for year, y_df in tqdm(df.groupby('会计年度'), desc='分析进度'):
for idx in y_df.index:
try:
data = dict()
data['会计年度'] = year
code = y_df.loc[idx, '股票代码']
data['股票代码'] = code
industry = y_df.loc[idx, '行业代码']
data['行业代码'] = industry
#筛选条件mask
ind_mask = y_df['行业代码']==f'{industry}'
corp_mask = y_df['股票代码']==f'{code}'
year_mask = y_df['会计年度'] == f'{year}'
#某年某公司a
selected_corp_index = y_df[ind_mask & corp_mask & year_mask].index
corp_vec = dtm_df[dtm_df.index.isin(selected_corp_index)].values
corp_arr = np.array(corp_vec)
#某year,某行业(排除公司a)
selected_ind_df = y_df[ind_mask & year_mask]
selected_indexs = selected_ind_df[selected_ind_df['股票代码']!=code].index
ind_vec = dtm_df[dtm_df.index.isin(selected_indexs)].mean(axis=0).values
ind_arr = np.array([ind_vec])
#信息含量
special_info = -1 * cosine_similarity(corp_arr, ind_arr)[0][0]
data['信息含量'] = special_info
writer.writerow(data)
except:
pass
Run
分析进度: 100%|█████████████████████████████████| 22/22 [01:58<00:00, 5.37s/it]
CPU times: user 1min 55s, sys: 2.91 s, total: 1min 57s
Wall time: 1min 58s
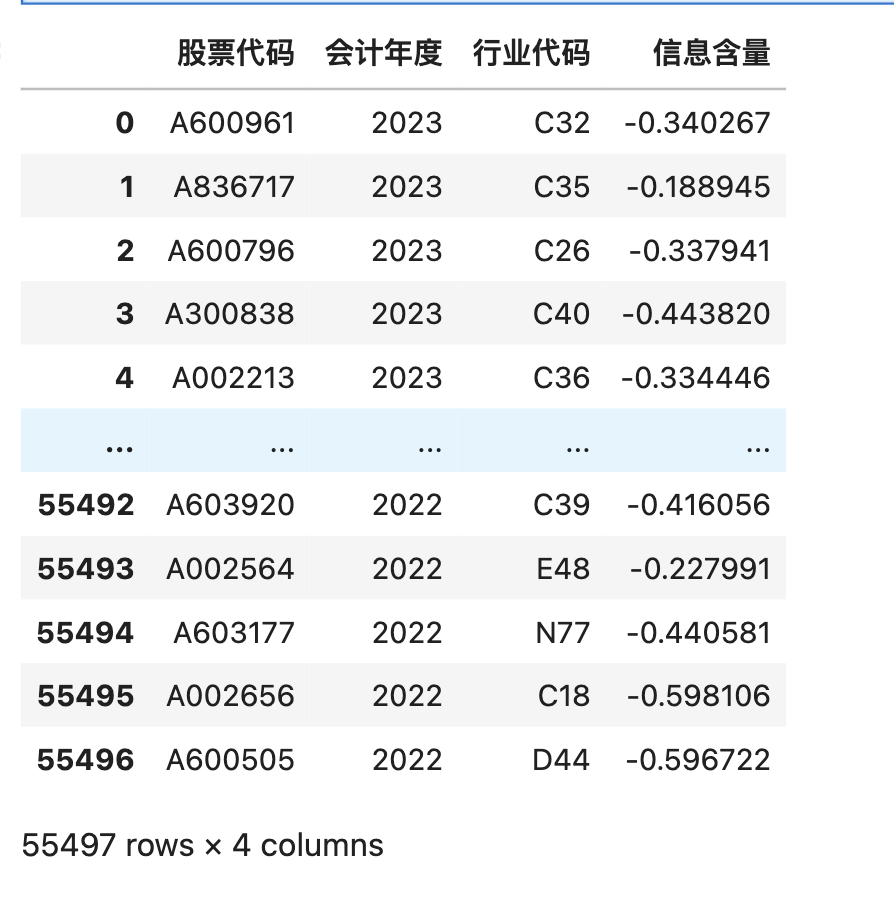
四、查看结果
欣赏一下计算结果 关键审计-信息含量01-23.csv
import pandas as pd
idf = pd.read_csv('关键审计-信息含量01-23.csv')
idf
五、相关内容
最近陆续分享了几篇文本相似度、信息含量的论文
[1]姜富伟,胡逸驰,黄楠.央行货币政策报告文本信息、宏观经济与股票市场[J].金融研究,2021,(06):95-113.
[2]宋建波,冯晓晴.关键审计事项信息含量与公司债券发行定价——基于文本相似度视角[J].会计研究,2022,(03):174-191.
[3]孟庆斌,杨俊华,鲁冰.管理层讨论与分析披露的信息含量与股价崩盘风险——基于文本向量化方法的研究[J].中国工业经济,2017,(12):132-150.
比较一下,三者均先使用了文本向量化,将本文数据转为向量。每篇论文的算法
| 论文 | 指标 | 算法 |
|---|---|---|
| [1] | 文本相似度 | 将央行货币政策报告向量化, 临近的两个报告文本向量计算相似度,相似度越高,金融市场波动性越小。 |
| [2] | 信息含量(本文) | 将同行业内所有企业向量Corp求均值得到行业向量Ind,求Corp与Ind的余弦相似度,并将结果乘以(-1),所得结果定义为信息向量。 |
| [3] | 信息含量 | 文本向量化+计量建模,认为md&a中的信息向量Norm可以由市场Norm_Market、行业Norm_Industry、企业异质性μ三种信息向量组成,通过计算 Norm = a0 + a1*Norm_Industry + a2*Norm_Market + μ ,将μ 向量的绝对值和作为信息含量,而a1+a2看标准信息。 |
从中可以看到两个向量的余弦相似度,在不同场景,解读含义是不同的。
- 在货币政策中,相似度越高,表示越政策稳定,金融市场波动星越小。
- 而在关键审计场景中,特质性信息是缓解公司与投资者信息不对称的关键,公司向量Corp与行业向量Ind相似度越高,表示公司审计报告文本特质性信息越少。
六、资料获取
数据&代码创作不易, 200元, 如果需要源代码和数据, 加微信372335839, 备注「姓名-学校-专业」
打包价 100元
1. 管理层讨论与分析(mda01-23.csv.gz)、上市公司基本信息2000-2023.xlsx
2. 计算结果(关键审计-信息含量01-23.csv)
零卖价
- 100元 管理层讨论与分析(mda01-23.csv.gz)、上市公司基本信息2000-2023.xlsx
- 50元 计算结果(关键审计-信息含量01-23.csv)
