
1978-2019.4, 585w中国大陆企业注册信息
文末有 enterprise-registration-data-of-chinese-mainland.csv 数据获取方式。
import pandas as pd
df = pd.read_csv('enterprise-registration-data-of-chinese-mainland.csv',
encoding='utf-8',
#忽略有问题的记录
on_bad_lines='skip')
df.head()
Run
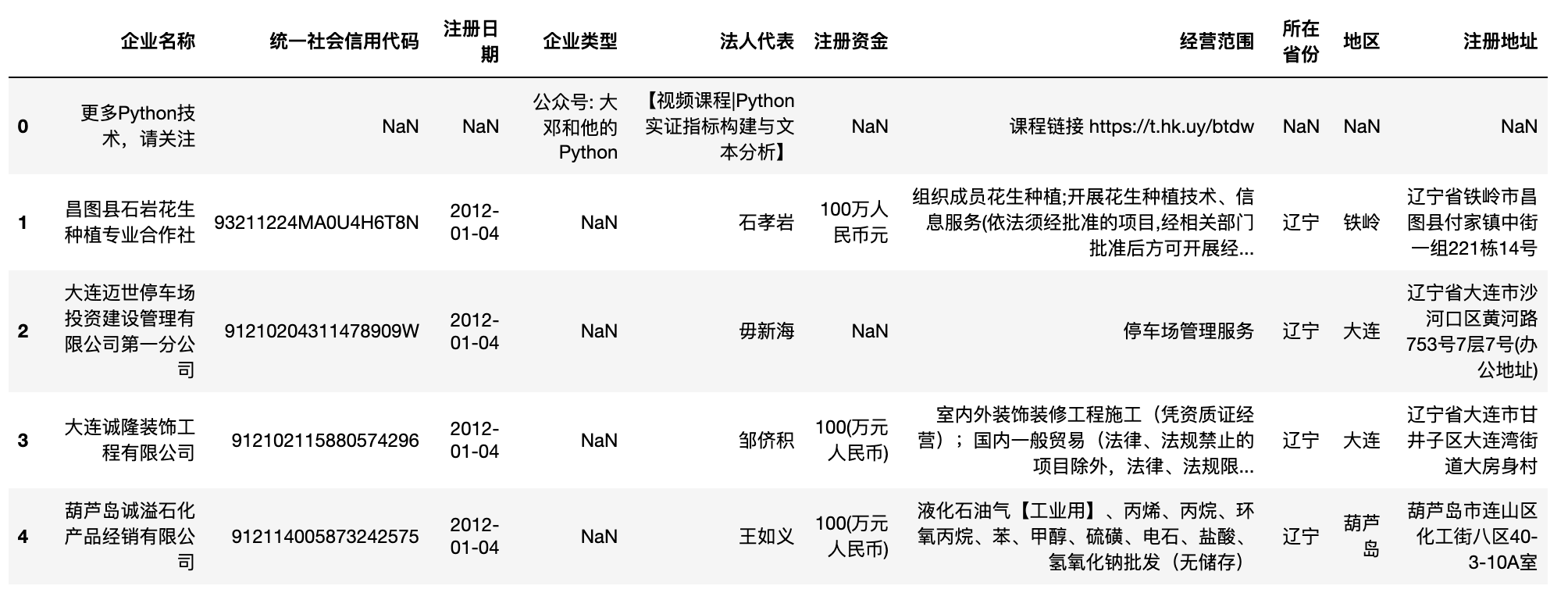
#剔除大邓广告
df = df[df['企业类型']!='公众号: 大邓和他的Python']
df.head()
Run
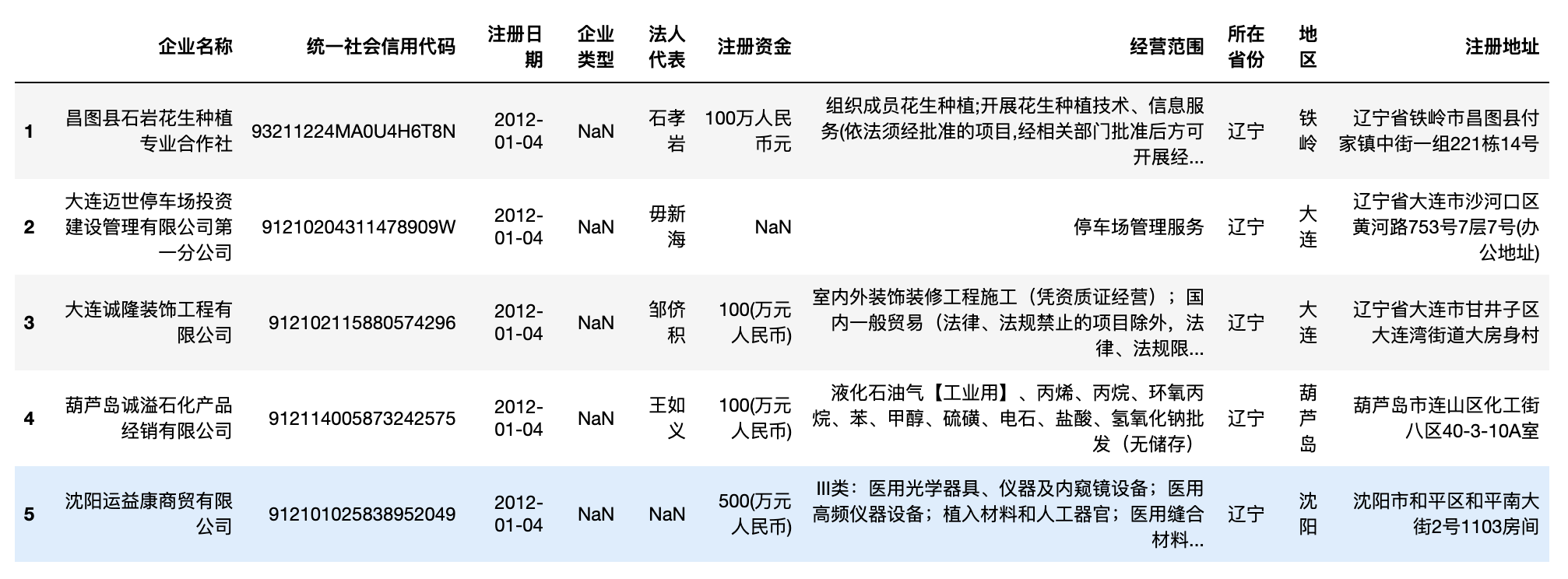
#记录
print('记录数: ', len(df))
#
print('字段有: ', df.columns)
Run
'记录数: 12756270'
'字段有: ['企业名称', '统一社会信用代码', '注册日期', '企业类型', '法人代表', '注册资金', '经营范围', '所在省份',
'地区', '注册地址']'
但数据可能会有重复,这里以企业名称作为唯一标识,可以查看真实的数据量
print('真实记录数: ', len(set(df['企业名称'])))
Run
'真实记录数: 5888382'
二、如何将多个csv汇总到一个csv中?
那么这个enterprise-registration-data-of-chinese-mainland.csv怎么来的?
原始的数据集结构

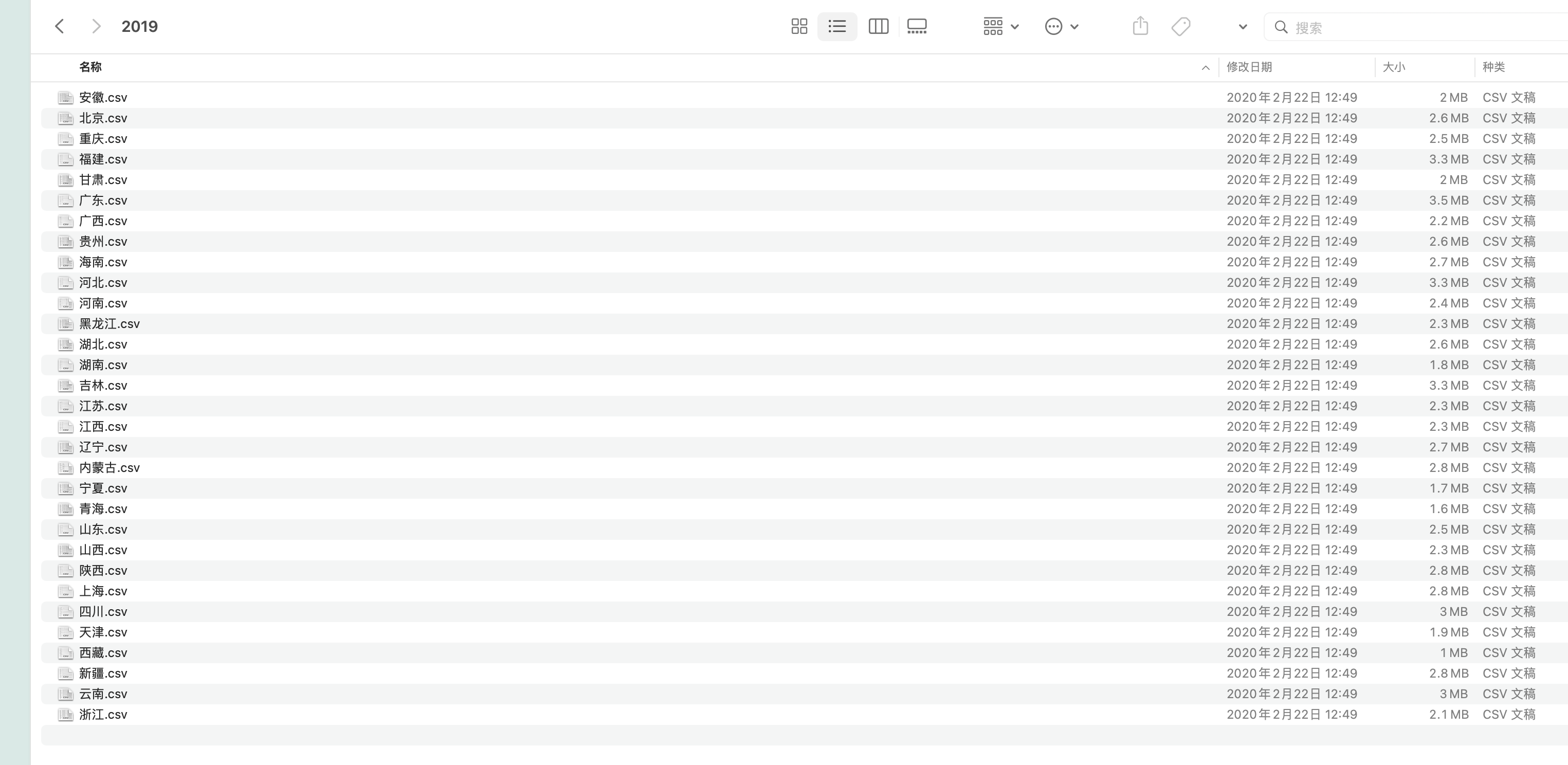
先局部实验成功后,推广到整体。
- 获取路径列表
- 尝试读取任意一个csv文件
- 尝试合并两个df
- 合并所有csv到一个文件内
2.1 获取路径列表
import os
#大邓电脑为Mac
#Mac容易在文件夹中生成奇怪的.DS_Store
#该操作为获取文件夹列表,同时剔除.DS_Store
y_dirs = [di for di in os.listdir('csv') if '.DS_Store'!=di]
for y_dir in y_dirs:
#在年份文件夹内有很多csv文件
fs = ['csv/{}/{}'.format(y_dir, fn)
for fn in os.listdir('csv/{}'.format(y_dir))
if '.csv' in fn]
print(fs)
print()
Run
......
......
['csv/2013/河南.csv', 'csv/2013/青海.csv', 'csv/2013/河北.csv', 'csv/2013/浙江.csv', 'csv/2013/内蒙古.csv', 'csv/2013/辽宁.csv', 'csv/2013/天津.csv', 'csv/2013/福建.csv', 'csv/2013/吉林.csv', 'csv/2013/西藏.csv', 'csv/2013/四川.csv', 'csv/2013/云南.csv', 'csv/2013/宁夏.csv', 'csv/2013/新疆.csv', 'csv/2013/安徽.csv', 'csv/2013/重庆.csv', 'csv/2013/贵州.csv', 'csv/2013/湖南.csv', 'csv/2013/海南.csv', 'csv/2013/湖北.csv', 'csv/2013/江西.csv', 'csv/2013/广东.csv', 'csv/2013/北京.csv', 'csv/2013/山西.csv', 'csv/2013/上海.csv', 'csv/2013/陕西.csv', 'csv/2013/黑龙江.csv', 'csv/2013/甘肃.csv', 'csv/2013/江苏.csv', 'csv/2013/山东.csv', 'csv/2013/广西.csv']
['csv/2014/河南.csv', 'csv/2014/青海.csv', 'csv/2014/河北.csv', 'csv/2014/浙江.csv', 'csv/2014/内蒙古.csv', 'csv/2014/辽宁.csv', 'csv/2014/天津.csv', 'csv/2014/福建.csv', 'csv/2014/吉林.csv', 'csv/2014/西藏.csv', 'csv/2014/四川.csv', 'csv/2014/云南.csv', 'csv/2014/宁夏.csv', 'csv/2014/新疆.csv', 'csv/2014/安徽.csv', 'csv/2014/重庆.csv', 'csv/2014/贵州.csv', 'csv/2014/湖南.csv', 'csv/2014/海南.csv', 'csv/2014/湖北.csv', 'csv/2014/江西.csv', 'csv/2014/广东.csv', 'csv/2014/北京.csv', 'csv/2014/山西.csv', 'csv/2014/上海.csv', 'csv/2014/陕西.csv', 'csv/2014/黑龙江.csv', 'csv/2014/甘肃.csv', 'csv/2014/江苏.csv', 'csv/2014/山东.csv', 'csv/2014/广西.csv']
['csv/2015/河南.csv', 'csv/2015/青海.csv', 'csv/2015/河北.csv', 'csv/2015/浙江.csv', 'csv/2015/内蒙古.csv', 'csv/2015/辽宁.csv', 'csv/2015/天津.csv', 'csv/2015/福建.csv', 'csv/2015/吉林.csv', 'csv/2015/西藏.csv', 'csv/2015/四川.csv', 'csv/2015/云南.csv', 'csv/2015/宁夏.csv', 'csv/2015/新疆.csv', 'csv/2015/安徽.csv', 'csv/2015/重庆.csv', 'csv/2015/贵州.csv', 'csv/2015/湖南.csv', 'csv/2015/海南.csv', 'csv/2015/湖北.csv', 'csv/2015/江西.csv', 'csv/2015/广东.csv', 'csv/2015/北京.csv', 'csv/2015/山西.csv', 'csv/2015/上海.csv', 'csv/2015/陕西.csv', 'csv/2015/黑龙江.csv', 'csv/2015/甘肃.csv', 'csv/2015/江苏.csv', 'csv/2015/山东.csv', 'csv/2015/广西.csv']
.....
.....
2.2 尝试读取任意一个csv文件
import pandas as pd
df1 = pd.read_csv('csv/2012/辽宁.csv',
encoding='utf-8',
on_bad_lines='skip')
df1.head(2)
Run

df2 = pd.read_csv('csv/2013/青海.csv',
encoding='utf-8',
on_bad_lines='skip')
df2.head(2)
Run

2.3 尝试合并两个df
两个df垂直方向堆积,不增加字段种类,所以选择 pd.concat函数。
df12 = pd.concat([df1, df2], axis=0)
df12.head(2)
Run
#检查记录数
print(len(df1))
print(len(df2))
print(len(df12))
Run
10246
4417
14663
2.4 合并所有csv到一个文件内
将步骤1、2、3代码整理,汇总
import os
import pandas as pd
#存df列表
dfs = []
#文件路径列表
y_dirs = [di for di in os.listdir('csv') if '.DS_Store'!=di]
for y_dir in y_dirs:
csvfs = ['csv/{}/{}'.format(y_dir, fn)
for fn in os.listdir('csv/{}'.format(y_dir))
if '.csv' in fn]
for csvf in csvfs:
#读取csv,得到df
df = pd.read_csv(csvf, encoding='utf-8', on_bad_lines='skip')
#存入df列表
dfs.append(df)
#合并dfs为alldf
alldf = pd.concat(dfs, axis=0)
#导出为data.csv
alldf.to_csv('enterprise-registration-data-of-chinese-mainland.csv', index=False)
三、数据获取
转发本文至朋友圈集赞50+, 加微信372335839, 备注【姓名-学校-专业-1200w工商】获取本文数据。