
一、高管数据集概况
1.1 数据源概况
数据集名: 中国上市公司高管简历数据集
覆盖日期: 1990-12-10 ~ 2021-07-19
记录条数: 900887
下载链接: https://pan.baidu.com/s/1hWadZraOk_GteADuOrpfpw?pwd=ccju
本文声明: 科研用途;如有问题, 请加微信372335839,备注「姓名-学校-专业」
90w条中国上市公司高管简历(采集自新浪财经公开数据) ,统计的日期范围1990-2021年。
以「新希望」为例, 新浪财经-新希望高管截图。
https://vip.stock.finance.sina.com.cn/corp/go.php/vCI_CorpManager/stockid/000876.phtml
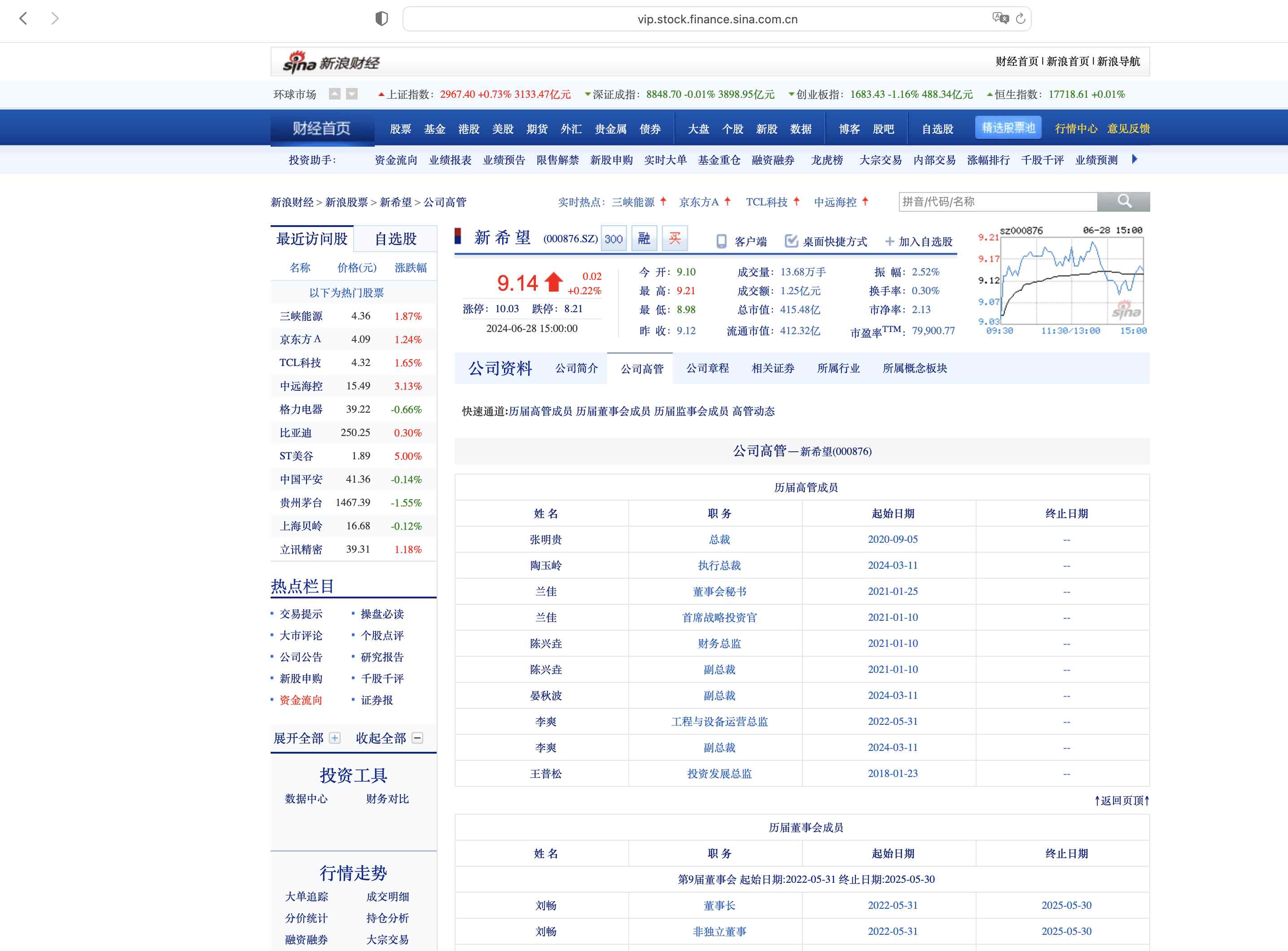
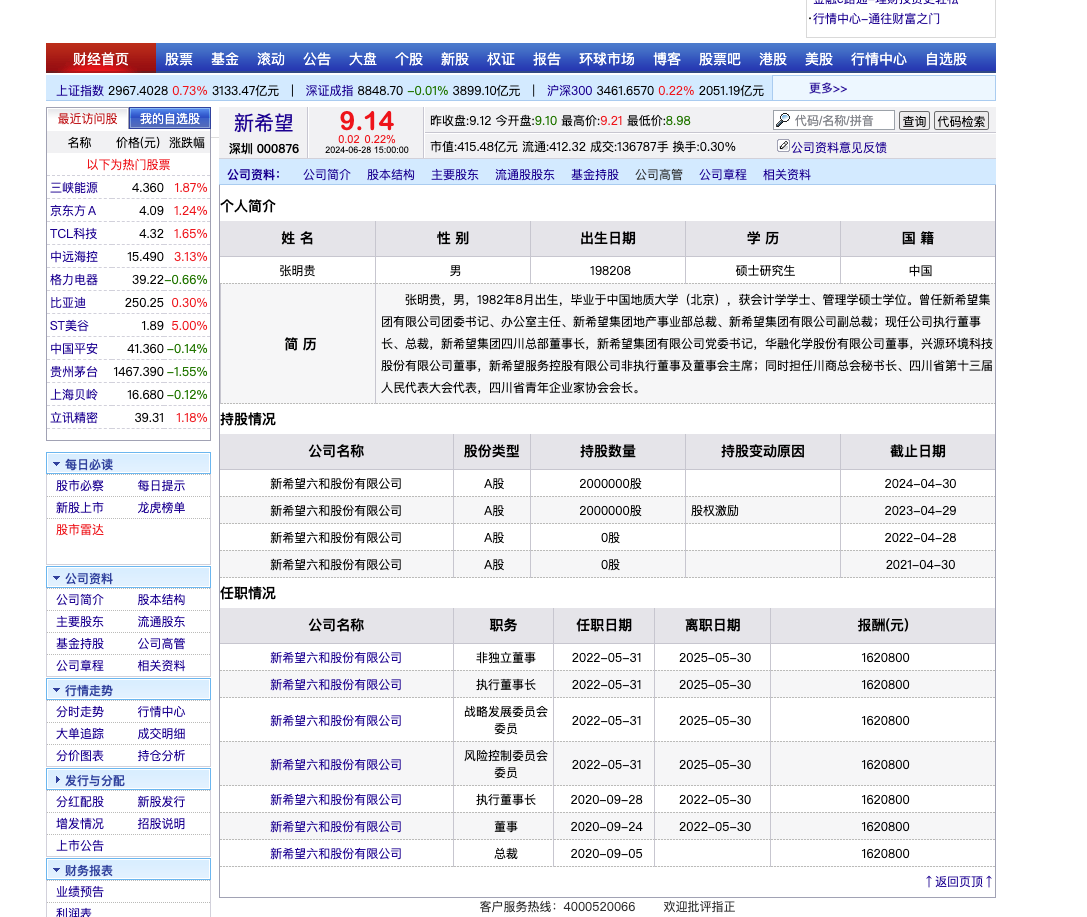
1.2 数据集字段
数据集的字段含,大多是从「个人简历」中计算衍生出来的。
- ID
- 姓名
- 证券代码
- 统计截止日期
- 个人简历
- 国籍
- 籍贯
- 籍贯所在地区代码
- 出生地
- 出生地所在地区代码
- 性别
- 年龄
- 毕业院校
- 学历 1=中专及中专以下; 2=大专; 3=本科; 4=硕士研究生; 5=博士研究生; 6=其他(以其他形式公布的学历,如荣誉博士、函授等); 7=MBA/EMBA
- 专业
- 职称
- 是否领取薪酬
- 报告期报酬总额
- 年末持股数
- 是否高管团队成员
- 是否董事会成员
- 是否独立董事
- 是否兼任董事长和CEO
- 是否监事
- 具体职务
二、实验代码
2.1 读取数据
- 数据文件
高管数据.xlsx - 强制某几个字段的数据类型
- 将字段 「统计截止日期」 转化为 datetime 类型
import pandas as pd
# 导入数据,
df = pd.read_excel('高管数据.xlsx',
#保证这两个字段是字符串格式
converters={'证券代码': str,
'ID': str})
#将字段「统计截止日期」 整理为datetime格式
df['统计截止日期'] = pd.to_datetime(df['统计截止日期'])
#显示前1条记录
df.head(1)
Run

2.2 字段
df.columns
Run
Index(['ID', '姓名', '证券代码', '统计截止日期', '个人简历', '国籍', '籍贯', '籍贯所在地区代码', '出生地',
'出生地所在地区代码', '性别', '年龄', '毕业院校', '学历', '专业', '职称', '是否领取薪酬', '报告期报酬总额',
'津贴', '年末持股数', '是否高管团队成员', '是否董事会成员', '是否独立董事', '是否兼任董事长和CEO', '是否监事',
'具体职务'],
dtype='object')
2.3 记录数
数据集记录数共
len(df)
Run
900887
2.4 覆盖日期
数据统计日期范围自 1990年12月10日 至 2021年7月19日
df['统计截止日期'].sort_values()
Run
900886 1990-12-10
900884 1990-12-10
900883 1990-12-10
900882 1990-12-10
900881 1990-12-10
...
59734 2021-07-19
59733 2021-07-19
59731 2021-07-19
59736 2021-07-19
59742 2021-07-19
Name: 统计截止日期, Length: 900887, dtype: datetime64[ns]
数据集字段 有
df.columns
Run
Index(['ID', '姓名', '证券代码', '统计截止日期', '个人简历', '国籍', '籍贯', '籍贯所在地区代码', '出生地',
'出生地所在地区代码', '性别', '年龄', '毕业院校', '学历', '专业', '职称', '是否领取薪酬', '报告期报酬总额',
'津贴', '年末持股数', '是否高管团队成员', '是否董事会成员', '是否独立董事', '是否兼任董事长和CEO', '是否监事',
'具体职务'],
dtype='object')
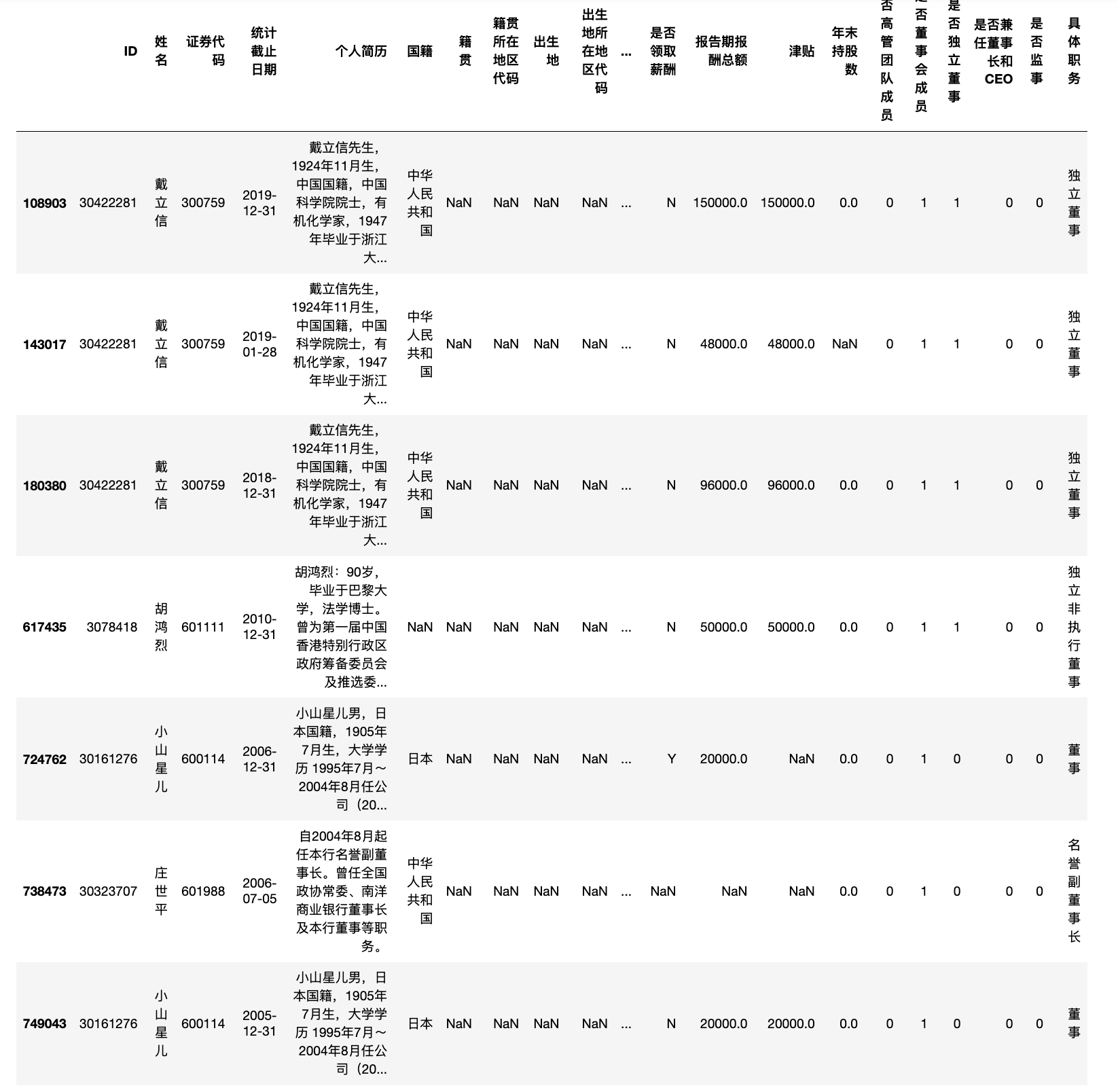
2.5 按条件筛选记录
截止统计日期时大于90岁的高管 记录有
df[df['年龄']>90]
三、相关内容
何瑛,于文蕾,戴逸驰,王砚羽.高管职业经历与企业创新[J].管理世界,2019,35(11):174-192.
摘要:管理的本质是一种实践,在某些情形下,阅历比简历更重要,丰富的职业经历有助于企业高管形成多元化的思维结构、广阔的管理视野、丰富的社会资源和过人的胆识,也是塑造复合型人才的重要路径。本文基于行为金融理论和高层梯队理论,手工搜集整理了2007~2016年中国沪深A股上市公司高管职业经历独特数据集,从职能部门、企业、行业、组织机构和地域类型五个维度构建了复合型职业经历的衡量指标——职业经历丰富度指数,对CEO职业经历与企业创新的影响因素和影响机理进行理论解释、数据分析和验证。研究结果表明:CEO职业经历越丰富,企业创新水平越高,其中跨企业经历对创新水平的影响最为显著,其次是跨行业经历和跨组织机构经历,跨职能部门经历和跨地域经历对企业创新水平的影响最小;影响因素方面,基于公司内外部治理的视角发现,市场化程度越低、企业融资约束程度越低时,CEO职业经历丰富度对企业创新水平的促进作用越明显,国有企业CEO职业经历丰富度对企业创新水平的促进作用更强,而股权制衡度对CEO职业经历丰富度与企业创新水平的调节作用不明显;影响机理方面,CEO复合型职业经历主要是通过丰富高管的社会网络资源以及增强高管的风险偏好倾向,从而提升企业的创新水平。本文的研究结论拓展了企业创新影响因素及高管职业经历经济后果领域的相关文献,将复合型人才的影响从国家宏观层面拓展到企业微观层面,为企业高层次人才的招聘和选拔提供新的证据支持。 中提到高管的创新
高管,一般是有多个企业经历的, 如何将高管职业经历转化为可以计算和比较的 高管职业经历向量 呢?
如何用「图嵌入」将企业、高管职业经历表征为向量数据 , 有了向量可以
- 计算高管之间的相似度
- 企业高管团队异质性,计算高管向量之间的距离
- …
相关论文
这里粘贴部分应用高管数据论文
- 何瑛,于文蕾,戴逸驰,王砚羽.高管职业经历与企业创新[J].管理世界,2019,35(11):174-192.
- 杨林,和欣,顾红芳.高管团队经验、动态能力与企业战略突变:管理自主权的调节效应[J].管理世界,2020,36(06):168-188+201+252.
- 周楷唐,麻志明,吴联生.高管学术经历与公司债务融资成本[J].经济研究,2017,52(07):169-183.
- 陆瑶,张叶青,黎波,赵浩宇.高管个人特征与公司业绩——基于机器学习的经验证据[J].管理科学学报,2020,23(02):120-140.
- 柳光强,孔高文.高管经管教育背景与企业内部薪酬差距[J].会计研究,2021,(03):110-121.
- 郑建明,孙诗璐,李金甜.高管文化背景与企业债务成本——基于劳模文化的视角[J].会计研究,2021,(03):137-145.
