{
"cells": [
{
"cell_type": "markdown",
"id": "06573cfa",
"metadata": {},
"source": [
"pandas是最有用的Python数据分析库, 两个数据类型DataFrame和Series,值的我们反复接触、学习和实验,逐渐的将pandas独特的语法掌握。\n",
"\n",
"
\n",
"\n",
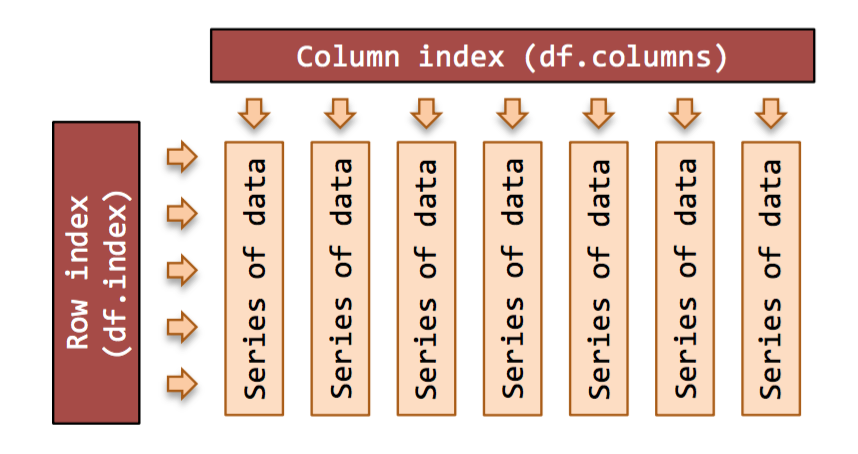
"## DataFrame是什么?\n",
"DataFrame是一种二维数据类型, 跟 Excel中的数据结构差不多, 即\n",
"\n",
"- 每行代表一条记录\n",
"- 每列代表一个字段(变量)\n",
"\n",
"每列(行),看做一个序列Series,在pandas中就是pd.Series类型的数据, 由很多pd.Sereis组成的数据就是DataFrame。\n",
"\n",
""
]
},
{
"cell_type": "markdown",
"id": "fdb1f460",
"metadata": {},
"source": [
"## 一、创建DataFrame\n",
"创建DataFrame有两种方式\n",
"\n",
"1. 使用pd.read_csv()/ pd.read_excel() 从csv、xlsx等文件导入, 得到DataFrame\n",
"2. 使用pd.DataFrame()函数构造DataFrame\n"
]
},
{
"cell_type": "code",
"execution_count": 3,
"id": "f730781a",
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" name | \n",
" age | \n",
" gender | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" David | \n",
" 25 | \n",
" male | \n",
"
\n",
" \n",
" | 1 | \n",
" Mary | \n",
" 30 | \n",
" female | \n",
"
\n",
" \n",
" | 2 | \n",
" Jessica | \n",
" 31 | \n",
" female | \n",
"
\n",
" \n",
" | 3 | \n",
" John | \n",
" 20 | \n",
" male | \n",
"
\n",
" \n",
"
\n",
"
\n",
"\n",
"## 二、选中某行(列)\n",
"\n",
"1. ``df.loc[row, :]`` 选中第row行所有数据\n",
"2. ``df.loc[row:row, :]`` 选中第row行所有数据\n",
"3. ``df.loc[row1: row2, ]`` 选中从row1至row2行的所有数据\n",
"4. ``df.loc[:, col]`` 选中第col列所有数据\n",
"5. ``df.loc[:, [col]]`` 选中第col列所有数据\n",
"6. ``df.loc[:, cols]`` 选中cols列的所有数据"
]
},
{
"cell_type": "code",
"execution_count": 14,
"id": "655c203c",
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"name Jessica\n",
"age 31\n",
"gender female\n",
"Name: 2, dtype: object"
]
},
"execution_count": 14,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"#选中第二行所有数据,返回结果为Series\n",
"df.loc[2, :]"
]
},
{
"cell_type": "code",
"execution_count": 15,
"id": "c94609ca",
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" name | \n",
" age | \n",
" gender | \n",
"
\n",
" \n",
" \n",
" \n",
" | 2 | \n",
" Jessica | \n",
" 31 | \n",
" female | \n",
"
\n",
" \n",
"
\n",
"
\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" gender | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" male | \n",
"
\n",
" \n",
" | 1 | \n",
" female | \n",
"
\n",
" \n",
" | 2 | \n",
" female | \n",
"
\n",
" \n",
" | 3 | \n",
" male | \n",
"
\n",
" \n",
"
\n",
"
\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" age | \n",
" gender | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" 25 | \n",
" male | \n",
"
\n",
" \n",
" | 1 | \n",
" 30 | \n",
" female | \n",
"
\n",
" \n",
" | 2 | \n",
" 31 | \n",
" female | \n",
"
\n",
" \n",
" | 3 | \n",
" 20 | \n",
" male | \n",
"
\n",
" \n",
"
\n",
"
\n",
"\n",
"## 三、新建某行(列)\n",
"- ``df[colname] = col_data`` 新增一列(字段)数据\n",
"- ``df.loc[row] = row_data`` 新增一条行(记录)数据"
]
},
{
"cell_type": "code",
"execution_count": 19,
"id": "a8dc829c",
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" name | \n",
" age | \n",
" gender | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" David | \n",
" 25 | \n",
" male | \n",
"
\n",
" \n",
" | 1 | \n",
" Mary | \n",
" 30 | \n",
" female | \n",
"
\n",
" \n",
" | 2 | \n",
" Jessica | \n",
" 31 | \n",
" female | \n",
"
\n",
" \n",
" | 3 | \n",
" John | \n",
" 20 | \n",
" male | \n",
"
\n",
" \n",
"
\n",
"
\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" name | \n",
" age | \n",
" gender | \n",
" nation | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" David | \n",
" 25 | \n",
" male | \n",
" US | \n",
"
\n",
" \n",
" | 1 | \n",
" Mary | \n",
" 30 | \n",
" female | \n",
" UK | \n",
"
\n",
" \n",
" | 2 | \n",
" Jessica | \n",
" 31 | \n",
" female | \n",
" UK | \n",
"
\n",
" \n",
" | 3 | \n",
" John | \n",
" 20 | \n",
" male | \n",
" US | \n",
"
\n",
" \n",
"
\n",
"
\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" name | \n",
" age | \n",
" gender | \n",
" nation | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" David | \n",
" 25 | \n",
" male | \n",
" US | \n",
"
\n",
" \n",
" | 1 | \n",
" Mary | \n",
" 30 | \n",
" female | \n",
" UK | \n",
"
\n",
" \n",
" | 2 | \n",
" Jessica | \n",
" 31 | \n",
" female | \n",
" UK | \n",
"
\n",
" \n",
" | 3 | \n",
" John | \n",
" 20 | \n",
" male | \n",
" US | \n",
"
\n",
" \n",
" | 4 | \n",
" Robert | \n",
" 22 | \n",
" male | \n",
" US | \n",
"
\n",
" \n",
"
\n",
"
\n",
"\n",
"## 四、删除\n",
"1. df.drop_duplicates() 删除重复的数据\n",
"2. df.drop() 删除某行(列)"
]
},
{
"cell_type": "code",
"execution_count": 39,
"id": "9021c4db",
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" name | \n",
" age | \n",
" gender | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" David | \n",
" 25 | \n",
" male | \n",
"
\n",
" \n",
" | 1 | \n",
" Mary | \n",
" 30 | \n",
" female | \n",
"
\n",
" \n",
" | 2 | \n",
" Jessica | \n",
" 31 | \n",
" female | \n",
"
\n",
" \n",
" | 3 | \n",
" John | \n",
" 20 | \n",
" male | \n",
"
\n",
" \n",
" | 4 | \n",
" John | \n",
" 20 | \n",
" male | \n",
"
\n",
" \n",
"
\n",
"
\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" name | \n",
" age | \n",
" gender | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" David | \n",
" 25 | \n",
" male | \n",
"
\n",
" \n",
" | 1 | \n",
" Mary | \n",
" 30 | \n",
" female | \n",
"
\n",
" \n",
" | 2 | \n",
" Jessica | \n",
" 31 | \n",
" female | \n",
"
\n",
" \n",
" | 3 | \n",
" John | \n",
" 20 | \n",
" male | \n",
"
\n",
" \n",
"
\n",
"
\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" name | \n",
" age | \n",
" gender | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" David | \n",
" 25 | \n",
" male | \n",
"
\n",
" \n",
" | 1 | \n",
" Mary | \n",
" 30 | \n",
" female | \n",
"
\n",
" \n",
" | 2 | \n",
" Jessica | \n",
" 31 | \n",
" female | \n",
"
\n",
" \n",
" | 3 | \n",
" John | \n",
" 20 | \n",
" male | \n",
"
\n",
" \n",
"
\n",
"
\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" name | \n",
" age | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" David | \n",
" 25 | \n",
"
\n",
" \n",
" | 1 | \n",
" Mary | \n",
" 30 | \n",
"
\n",
" \n",
" | 2 | \n",
" Jessica | \n",
" 31 | \n",
"
\n",
" \n",
" | 3 | \n",
" John | \n",
" 20 | \n",
"
\n",
" \n",
" | 4 | \n",
" John | \n",
" 20 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"\n",
"## 五、行列重命名\n",
"\n",
"使用 df.rename() 重命名dataframe"
]
},
{
"cell_type": "code",
"execution_count": 48,
"id": "4e219f97",
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" name | \n",
" age | \n",
" gender | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" David | \n",
" 25 | \n",
" male | \n",
"
\n",
" \n",
" | 1 | \n",
" Mary | \n",
" 30 | \n",
" female | \n",
"
\n",
" \n",
" | 2 | \n",
" Jessica | \n",
" 31 | \n",
" female | \n",
"
\n",
" \n",
" | 3 | \n",
" John | \n",
" 20 | \n",
" male | \n",
"
\n",
" \n",
"
\n",
"
\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" name | \n",
" age | \n",
" sex | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" David | \n",
" 25 | \n",
" male | \n",
"
\n",
" \n",
" | 1 | \n",
" Mary | \n",
" 30 | \n",
" female | \n",
"
\n",
" \n",
" | 2 | \n",
" Jessica | \n",
" 31 | \n",
" female | \n",
"
\n",
" \n",
" | 3 | \n",
" John | \n",
" 20 | \n",
" male | \n",
"
\n",
" \n",
"
\n",
"
\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" name | \n",
" age | \n",
" gender | \n",
"
\n",
" \n",
" \n",
" \n",
" | a | \n",
" David | \n",
" 25 | \n",
" male | \n",
"
\n",
" \n",
" | b | \n",
" Mary | \n",
" 30 | \n",
" female | \n",
"
\n",
" \n",
" | c | \n",
" Jessica | \n",
" 31 | \n",
" female | \n",
"
\n",
" \n",
" | c | \n",
" John | \n",
" 20 | \n",
" male | \n",
"
\n",
" \n",
"
\n",
"
\n",
"\n",
"## 六、替换"
]
},
{
"cell_type": "code",
"execution_count": 54,
"id": "eab9a2ef",
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" Student1 | \n",
" Student2 | \n",
" Student3 | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" OKs | \n",
" Perfect | \n",
" Acceptable | \n",
"
\n",
" \n",
" | 1 | \n",
" Awful | \n",
" Awful | \n",
" Perfect | \n",
"
\n",
" \n",
" | 2 | \n",
" Acceptable | \n",
" OK | \n",
" Poor | \n",
"
\n",
" \n",
"
\n",
"
\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" Student1 | \n",
" Student2 | \n",
" Student3 | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" OKs | \n",
" 4 | \n",
" 3 | \n",
"
\n",
" \n",
" | 1 | \n",
" 0 | \n",
" 0 | \n",
" 4 | \n",
"
\n",
" \n",
" | 2 | \n",
" 3 | \n",
" 2 | \n",
" 1 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" Student1 | \n",
" Student2 | \n",
" Student3 | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" 2 | \n",
" 4 | \n",
" 3 | \n",
"
\n",
" \n",
" | 1 | \n",
" 0 | \n",
" 0 | \n",
" 4 | \n",
"
\n",
" \n",
" | 2 | \n",
" 3 | \n",
" 2 | \n",
" 1 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"\n",
"## 七、 识别日期\n",
"\n",
"```python\n",
"import pandas as pd\n",
"\n",
"#自动识别日期数据\n",
"pd.read_csv('yourFile', parse_dates=True)\n",
"\n",
"#或指定日期所在列的字段名\n",
"pd.read_csv('yourFile', parse_dates=['columnName'])\n",
"\n",
"#指定日期字段的日期格式进行解析\n",
"dateparser = lambda x: pd.datetime.strptime(x, '%Y-%m-%d %H:%M:%S')\n",
"pd.read_csv(infile, parse_dates=['columnName'], date_parser=dateparse)\n",
"```"
]
},
{
"cell_type": "markdown",
"id": "3d4ca74f",
"metadata": {},
"source": [
"
\n",
"\n",
"## 八、保存\n",
"\n",
"```python\n",
"df.to_csv('myDataFrame.csv', encoding='utf-8')\n",
"df.to_excel('myDataFrame.xlsx')\n",
"```"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.9.7"
},
"toc": {
"base_numbering": 1,
"nav_menu": {},
"number_sections": false,
"sideBar": true,
"skip_h1_title": false,
"title_cell": "Table of Contents",
"title_sidebar": "Contents",
"toc_cell": false,
"toc_position": {},
"toc_section_display": true,
"toc_window_display": false
}
},
"nbformat": 4,
"nbformat_minor": 5
}