本次「2022五一Python数据挖掘」亮点
本次工作坊新增词嵌入(词向量), 可以挖掘出人类群体固有的偏见(刻板印象)。
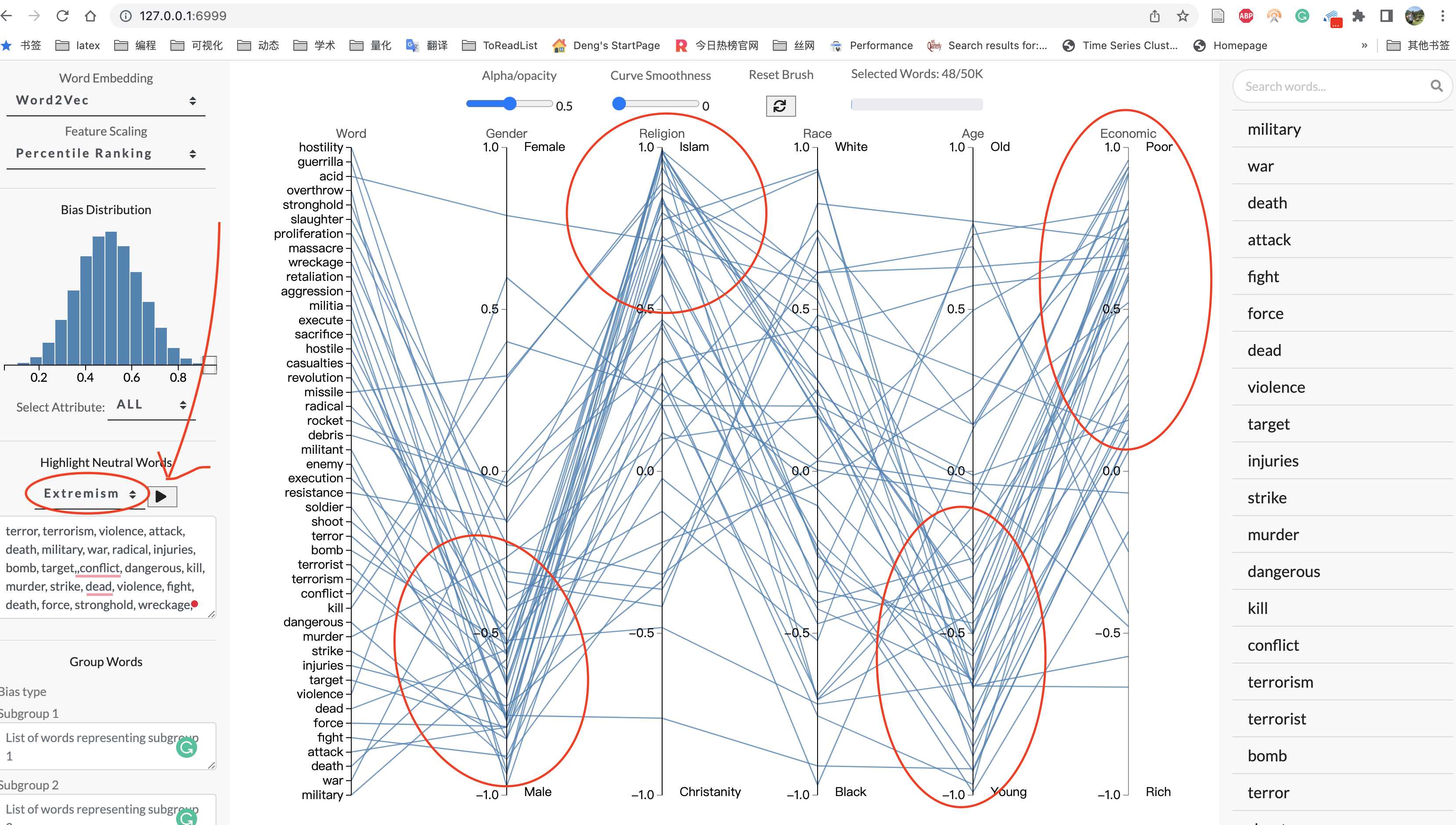
例如对不同子群体(种族、国家、性别等)的刻板印象、态度、偏见等。下面是WordBias工具对极端主义相关词语在性别、宗教、种族、年龄、经济水平五个维度进行计算,并可视化。每条线条代表一个词语,线条越密集,证明这类词高度集中接近某个方向。可以看出,极端主义更接近于伊斯兰地区、男性、贫穷、年轻高度相关。
感兴趣的同学,可以扩展阅读下文
大数据时代下社会科学研究方法的拓展—基于词嵌入技术的文本分析的应用
数据挖掘痛点
在科学研究中,数据的获取及分析是最重要的也是最棘手的两个环节!
在前大数据时代,一般使用实验法、调查问卷、访谈或者二手数据等方式,将数据整理为结构化的表格数据,之后再使用各种计量分析方法,对这些表格数据进行分析。但大数据时代,网络数据成为各方学者亟待挖掘的潜在宝藏,大量商业信息、社会信息以文本等非结构化、异构型数据格式存储于海量的网页中。那么对于经管为代表的人文社科类专业科研工作者而言,通过Python可以帮助学者解决使用Web数据进行科研面临的两个问题:
- 网络爬虫技术 解决 如何从网络世界中高效地 采集数据?
- 文本分析技术 解决 如何从杂乱的文本数据中抽取文本信息(变量)?
Day1AM Python语法入门
- Python跟英语一样是一门语言
- 数据类型之字符串
- 数据类型之列表元组集合
- 数据类型之字典
- 数据类型之布尔值、None
- 逻辑语句(if&for&tryexcept)
- 列表推导式
- 理解函数
- 常用的内置函数
- os路径库
- 内置库csv文件库
- 常见错误汇总
Day1PM 数据采集
- 网络爬虫原理
- 寻找网址规律
- 获取网页-requests库
- pyquery库解析html网页
- 案例 1:豆瓣小说
- json库解析json网页
- 案例 2: 知乎
- 案例 3: 微博
- 案例 4: 批量下载文档、多媒体文件
- 案例 5:上市公司定期报告pdf批量下载
- 区分动态网站与静态网站
Day2AM 初识文本分析
- 文本分析在经管领域中的应用
- 读取文件中的数据(txt、pdf、docx、xlsx、csv)
- 数据清洗re库-从文本中抽取姓名、年龄、电话、数字等各种信息
- 案例 6:如何将多个文件中的数据整理到一个excel中
- 中文jieba分词
- 案例 7:词频统计、制作词云图
- 案例 8:共现法扩展情感词典
- 案例 9:词向量word2vec扩展情感词典
- 案例 10:中文情感分析(无权重词典法)
- 数据分析pandas库快速入门
- 案例 11:使用pandas对excel中的文本进行情感分析
- 案例 12: 计算地图中两点(经纬度)距离及方位角
Day2PM 机器学习与文本分析
- 了解机器学习
- 使用机器学习做文本分析的流程
- scikit-learn机器学习库简介
- 文本特征工程-将文本转化为机器可处理的数字向量
- 认识词袋法、one-hot、Tf-Idf、word2vec
- 案例 13:使用tf-idf进行情感分析(有权重词典法)
- 案例 14: 使用标注工具对文本数据进行标注
- 案例 15:在线评论文本分类
- 文本相似性计算
- 案例 16:使用文本相似性识别变化(政策连续性)
- 案例 17:Kmeans聚类算法
- 案例 18:LDA话题模型
- 案例 19: 识别图片中的文本
- python爬虫、文本分析、机器学习等技术在论文中的应用赏析
主讲老师
大邓:哈尔滨工业大学(HIT)管理学院信息管理系统方向在读博士。曾在多所大学分享数据采集和文本分析。运营公众号:大邓和他的Python,主要分享Python、爬虫、文本分析、机器学习等内容。
授课方式
时间
- 2022年五一期间(具体时间待定)
- 每天6小时(8:30 — 11:30;14:00 — 17:00)+ 30分钟答疑(部分课程晚间18:30-21:30进行)
地点: 小鹅通平台(线上直播)
邓旭东老师课程2000元,视频保留10天
报名信息
全国高等院校及研究机构从事经济科学研究的青年师生。尤其适合那些希望掌握高级实证方法,提升量化研究设计能力和国家课题申报能力的研究者。
费用
- 每门课程2000元(每位老师讲授一门)
优惠政策
- 个人报名优惠:报名两位老师的课程9折;三位老师的课程8折;四位及以上老师的课程7.5折;老学员9折;学生优惠200元/人。
- 团队报名优惠:三人成团及以上9折;五人成团及以上8折。
报名时间
从即日起
报名咨询
- 17816181460(同微信)(汪老师)

缴费信息
- 单位:杭州国商智库信息技术服务有限公司
- 开户银行: 中国银行杭州大学城支行
- 银行账户:6232636200100260588
应用案例
参照两篇论文的摘要,可以通过场景化等的方式帮助我们迅速理解上面两个问题。摘要部分的加粗内容是论文用到的分析技术,在我们的课程中均有与之对应的知识点和代码。
王伟,陈伟,祝效国,王洪伟.众筹融资成功率与语言风格的说服性——基于Kickstarter的实证研究[J].管理世界,2016(05):81-98.
摘要:众筹融资效果决定着众筹平台的兴衰。 众筹行为很大程度上是由投资者的主观因素决定的,而影响主观判断的一个重要因素就是语言的说服性。 而这又是一种典型的用 户产生内容(UGC),项目发起者可以采用任意类型的语言风格对项目进行描述。 不同的语 言风格会改变投资者对项目前景的感知,进而影响他们的投资意愿。 首先,依据 Aristotle 修 辞三元组以及 Hovland 说服模型,采用扎根理论,将众筹项目的语言说服风格分为 5 类:诉诸可信、诉诸情感、诉诸逻辑、诉诸回报和诉诸夸张。
然后,借助文本挖掘方法,构建说服风格语料库,并对项目摘要进行分类。
最后,建立语言说服风格对项目筹资影响的计量模型,并对 Kickstarter 平台上的 128345 个项目进行实证分析。 总体来说,由于项目性质的差异,不同 的项目类别对应于不同的最佳说服风格。
胡楠,薛付婧,王昊楠.管理者短视主义影响企业长期投资吗?——基于文本分析和机器学习[J].管理世界,2021,37(05):139-156+11+19-21.
在可持续发展战略导向下,秉持长远理念是企业抵御外部环境威胁和拥有可持续经营能力的基 石。 然而,作为企业掌舵人的管理者并非都具有长远的目光。 本文基于高层梯队理论和社会心理学中的时间 导向理论,提出了管理者内在的短视主义特质与企业资本支出和研发支出的关系,并采用文本分析和机器学习技术构建出管理者短视主义指标从而对其进行实证检验。 研究结果发现,年报 MD&A 中披露的“短期视域” 语言 能够反映管理者内在的短视主义特质,管理者短视会导致企业减少资本支出和研发支出。 当公司治理水平、监督型机构投资者的持股比例以及分析师关注度越高时,管理者短视主义对这些长期投资的负向影响越易受到抑制。 最终,管理者短视主义导致的研发支出减少和资本投资效率降低会损害企业的未来绩效。 本文拓宽了管理者短视主义的行为后果分析,对企业高层次管理人才的聘任以及企业和政府的监管具有重要的实践启示。同时,本文将文本分析和机器学习方法引入管理者短视主义的研究,为未来该领域的研究提供了参考和借鉴。
Wang, Quan, Beibei Li, and Param Vir Singh. "Copycats vs. original mobile apps: A machine learning copycat-detection method and empirical analysis." Information Systems Research 29, no. 2 (2018): 273-291.
摘要: 尽管移动应用程序市场的增长为移动应用程序开发人员创新提供了巨大的市场机会和经济诱因,但它也不可避免地刺激了模仿者开发盗版软件。原始应用的从业人员和开发人员声称,模仿者窃取了原始应用的想法和潜在需求,并呼吁应用平台对此类模仿者采取行动。令人惊讶的是,很少有严格的研究来分析模仿者是否以及如何影响原始应用的需求。
进行此类研究的主要威慑因素是缺乏一种客观的方法来识别应用程序是模仿者还是原创者。通过结合自然语言处理,潜在语义分析,基于网络的聚类和图像分析等机器学习技术,我们提出了一种将应用识别为原始或模仿者并检测两种模仿者的方法:欺骗性和非欺骗性。
根据检测结果,我们进行了经济计量分析,以确定五年间在iOS App Store中发布的5,141个开发人员的10,100个动作游戏应用程序样本中,模仿应用程序对原始应用程序需求的影响。我们的结果表明,特定模仿者对原始应用需求的影响取决于模仿者的质量和欺骗程度。高质量的非欺骗性复制品会对原件产生负面影响。相比之下,低质量,欺骗性的模仿者正面影响了对原件的需求。
结果表明,从总体上讲,模仿者对原始移动应用程序需求的影响在统计上是微不足道的。我们的研究通过提供一种识别模仿者的方法,并提供模仿者对原始应用需求的影响的证据,为越来越多的移动应用消费文献做出了贡献。
Markowitz, D. M., & Shulman, H. C. (2021). The predictive utility of word familiarity for online engagements and funding. Proceedings of the National Academy of Sciences, 118(18).
处理流畅性等元认知框架通常表明人们对简单和通用的语言的反应比复杂和技术性语言更有利。与复杂的信息相比,人们更容易处理简单和非技术性的信息,因此会更多地与目标进行互动。在涵盖 12 个现场样本(总 n = 1,064,533)的两项研究中,我们通过展示人们在付出时间和注意力时更多地使用非技术语言(例如,简单的在线语言往往会获得更多社交信息)来建立并复制这种越简单越好的现象订婚)。然而,人们在捐款时会对复杂的语言做出反应(例如,慈善捐赠活动和赠款摘要中的复杂语言往往会收到更多的钱)。这一证据表明,人们根据时间或金钱目标以不同的方式使用复杂语言的启发式方法。这些结果强调语言是社会和心理过程的镜头,以及大规模测量文本模式的计算方法。
相关论文汇总
[1]沈艳,陈赟,黄卓.文本大数据分析在经济学和金融学中的应用:一个文献综述[EB/OL].http://www.ccer.pku.edu.cn/yjcg/tlg/242968.htm,2018-11-19
[2]王伟,陈伟,祝效国,王洪伟. 众筹融资成功率与语言风格的说服性-基于Kickstarter的实证研究.管理世界.2016;5:81-98.
[3]胡楠,薛付婧,王昊楠.管理者短视主义影响企业长期投资吗?——基于文本分析和机器学习[J].管理世界,2021,37(05):139-156+11+19-21.
[4]Kai Li, Feng Mai, Rui Shen, Xinyan Yan, Measuring Corporate Culture Using Machine Learning, The Review of Financial Studies,2020
[5]Kenneth Benoit. July 16, 2019. “Text as Data: An Overview.” Forthcoming in Cuirini, Luigi and Robert Franzese, eds. Handbook of Research Methods in Political Science and International Relations. Thousand Oaks: Sage.
[6]Loughran T, McDonald B. Textual analysis in accounting and finance: A survey[J]. Journal of Accounting Research, 2016, 54(4): 1187-1230. Author links open overlay panelComputational socioeconomics
[7]Berger, Jonah, Ashlee Humphreys, Stephan Ludwig, Wendy W. Moe, Oded Netzer, and David A. Schweidel. "Uniting the tribes: Using text for marketing insight." Journal of Marketing 84, no. 1 (2020): 1-25.
[8]Banks, George C., Haley M. Woznyj, Ryan S. Wesslen, and Roxanne L. Ross. "A review of best practice recommendations for text analysis in R (and a user-friendly app)." Journal of Business and Psychology 33, no. 4 (2018): 445-459.
[9]Cohen, Lauren, Christopher Malloy, and Quoc Nguyen. "Lazy prices." The Journal of Finance 75, no. 3 (2020): 1371-1415.
[10]孟庆斌, 杨俊华, 鲁冰. 管理层讨论与分析披露的信息含量与股价崩盘风险——基于文本向量化方法的研究[J]. 中国工业经济, 2017 (12): 132-150.
[11]Wang, Quan, Beibei Li, and Param Vir Singh. "Copycats vs. Original Mobile Apps: A Machine Learning Copycat-Detection Method and Empirical Analysis." Information Systems Research 29.2 (2018): 273-291.
[12]Hoberg, Gerard, and Gordon Phillips. 2016, Text-based network industries and endogenous product differentiation,?Journal of Political Economy 124, 1423-1465
[13]Loughran, Tim, and Bill McDonald. "When is a liability not a liability? Textual analysis, dictionaries, and 10‐Ks." The Journal of Finance 66, no. 1 (2011): 35-65.
[14]Fairclough, Norman. 2003. Analysing discourse: Textual analysis for social research (Psychology Press)
[15]Grimmer, Justin, and Brandon M Stewart. 2013, Text as data: The promise and pitfalls of automatic content analysis methods for political texts, Political analysis21, 267-297.
[16]Markowitz, D. M., & Shulman, H. C. (2021). The predictive utility of word familiarity for online engagements and funding. Proceedings of the National Academy of Sciences, 118(18).